


3个妙招,轻松节约80%的Token消耗
你有没有觉得,Token 消耗快得离谱?明明没聊几句,额度就快见底了。
这不是你的错。因为大模型公司就想让你多花token,所以现在方案都是最消耗token的。
但只要理解AI运行的原理,三个小改动就能把消耗砍掉一大半。
1:别让 AI 去"看"网页
这是最大的浪费源头。
很多人会每天获取50+网页总结热点。做法是让 AI 控制浏览器抓信息,觉得省事。但代价是什么?AI 浏览网页的时候,会把整个页面所有内容都读一遍——出了内容,甚至还有html代码,全算 Token。一个普通新闻页面可能上万 Token,你真正要的就几百个字。
特别是每天做信息收集、总结热点的人,这种浪费是翻倍放大的。
正确做法特别简单:能调 API 就调 API,普通网页写个爬虫脚本。脚本只抓你要的字段,干干净净,Token 基本为零。
2:给 Subagent 传文件路径,别替它"传话"
用 Agent 工作流的人最容易踩这个坑。
在现有方案中,都是主 Agent 会将所有信息阅读一遍,然后分配给Subagent。问题是——这些信息会全部过一遍主 Agent 的上下文,哪怕跟当前子任务完全没关系的,也一样算 Token。
解决办法很直觉:把数据写进文件,只告诉 Subagent 文件路径,让它自己去读需要的部分。主 Agent 上下文始终保持精简,Token 直接打骨折。
3:AI 是用来思考的,不是用来当 Excel 的
→ **大数据先用代码过滤**——别一股脑全丢给 AI。先用 Python 脚本做统计、筛选,把最关键的部分提炼出来,再让 AI 做判断和决策。
这三招为什么有效?
这是因为原理上,AI不是人,它没有记忆。每一次请求,你需要把把历史对话、工具定义、Skill、MCP 配置……全部打包发一遍。聊得越久,包越大,Token 蹭蹭涨。大模型公司当然不会主动教你怎么省——你用得多它才赚得多嘛。
如何操作?
改变也非常轻松,就是在 Skill 的时候多用 Script**——能用代码完成的步骤就封装成脚本,只把真正需要"动脑子"的环节留给 AI。操作上很简单,你在 Skill 里把这些步骤写成代码执行就行,其他流程完全一样。
这套方法还有个很多人没意识到的额外好处:**省 Token 的同时,AI 的准确率反而会提高**。
道理很简单——上下文越短,噪音越少,AI 越容易聚焦在关键信息上做出对的判断。上下文太长反而容易"分心",产生幻觉。
省钱和提质,其实是同一件事。
觉得有用的话转发给你身边也在用 AI 的朋友,感谢来个三连

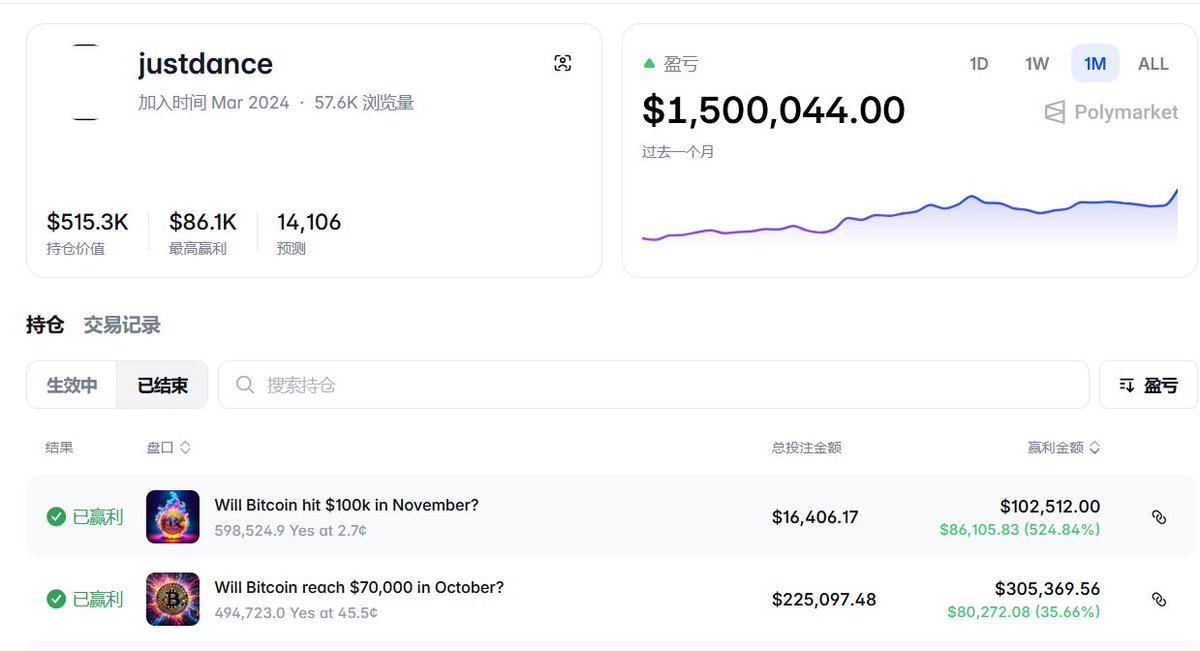


Crypto 龙虾养成记:打造个人专属的“聪明钱”地址库
基于OnchainOS,此Skill能分析最新热门暴涨项目,分析出优质地址。你可以深度构建个人专属的链上“聪明钱”地址库。
它的核心优势在于
1)相比市面上大而全的机构数据库,你可以拥有一个小而美、精挑细选的优质地址库。
2)链上地址更换频繁,大佬也常换小号。该skill随时分析,获得最新的聪明钱地址。
在聪明钱地址基础上,进一步获得他们的持仓分布,挖掘潜在的好项目。也可以实时跟踪聪明钱的动向(OnchainOS自有skill)
具体的流程和功能:
1 支持两种开启运行方法:
方式1:让龙虾定时运行。它会自动捕捉每日最热的项目,筛选出值得分析的项目。通过多维度筛选(如:未分析过的新项目、短期爆发力强、自动剔除貔貅/诈骗盘)锁定值得挖掘的目标
方式2:用户也可以直接把想分析的项目,让该skill来深度分析
2 优质买入时间窗口
skill能分析出的“黄金交易区间”,通常指大爆发前的埋伏期,或者速通盘的早期时间。
3 获得交易记录(优质时间窗口内)
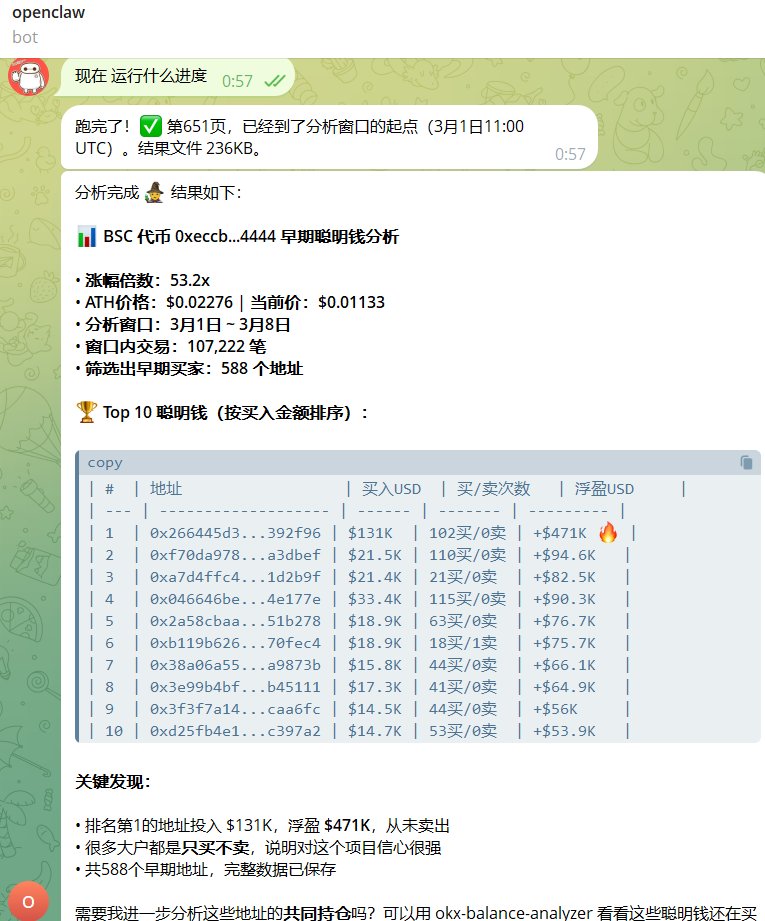
这是分析聪明钱的数据分析的基础。由于数据量较大,时间比较长。我开发了专门的 Python 脚本嵌入 Skill,确保数据抓取的高效与准确
4 分析聪明钱地址
通过上一步的交易记录,分析出聪明钱地址。对于聪明钱的判断标准,现在skill内置的一套逻辑,比如购买金额超过1000u,不能在优质时间窗口卖出量超过50%等。
同时也支持直接跟AI对话,自行调整聪明钱判断标准
该skill分析地址买卖行为,排除机器人bot、排除套利交易者等,确保是优质的个人交易地址。
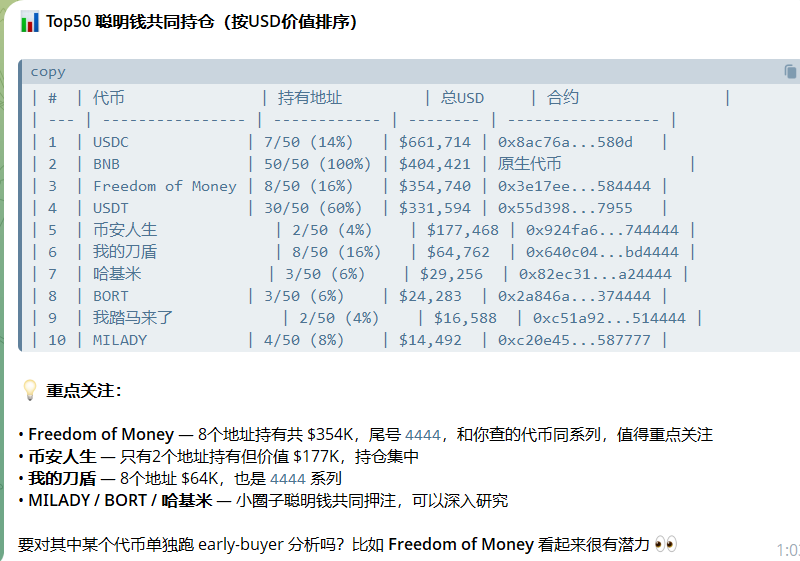
5 分析聪明钱的其它持仓
分析聪明钱的现在的持仓,挖掘其它有潜力的项目,作为买入的潜在标的。
支持,上一步分析出的聪明钱单独分析。也可以私有的聪明库一起分析。
6 结合其他OnchainOS的功能
无缝对接 OnchainOS 的其他功能,比如适合跟踪聪明钱的动向,跟单交易(OnchainOS自有skill)
龙虾型号:oponclaw 2026.3.3
模型型号:claude-opus-4-6
AI时代下,将何去何从?
每个人都很焦虑,因为AI发展的太快了,效率指数级提高,很多工作和公司可能会被颠覆掉。而这里有一个最核心的问题是,AI的最终形态是什么?
这个问题之所以重要,历史的经验告诉我们,在一项革命发展中,中间的形态将全部成为炮灰。实际上,过去2年,连AI的新技术都已经被淘汰了。如果是个人,很容易形成每天要拼命的学新技能的苦逼模式中。
而这个问题,我也一直思考了很久。最近有一个答案开始越来越清晰。那就是,个性化的私人AI。
1 AI加持下的完全个性化
每个人都是一个独立的个体,有着不一样的喜好。吃饭,有人喜欢辣,有人喜欢清淡,菜有火锅、烧烤、麻辣烫等等。出去旅游,有人喜欢爬山涉水、有人喜欢轻松悠闲。
商业的核心价值是在解决问题。而现在商业的模式基本是,大公司会解决大部分人普适的需求,中线公司的会解决小部分人的集中需求。而未来,会由AI来解决每个人不同的需求。
从社会实际发展的维度来看,工业革命的生产力提高,从统一的商品到各类不同的风格。从大家都看一样信息的门户网站,到抖音这种个性化推荐。都是在满足更高个性化的演变。
而在未来,在AI的加持下,可以实现完全个性化的需求。满足每个人独立个体的与众不同的偏好
2 人类与AI的关系
现在还有一种担心的观点,AI现在能力这么强,以后不需要人干什么了。这也是极其悲观的想法。事实是每一次的科技进步,都会改变很多。就像互联网出现后,报纸杂志开始消失了,但是出现了自媒体博主,带货主播。
最核心的是,主要有人在,就有需求。而人的欲望是永远不会被满足了,有了好东西后,如果出现更好,更更好的,那就也想要。
至于AI会产生自我意识,担心电影里的桥段那样AI统治世界,我觉得是杞人忧天了。而且AI是人类发明,即使AI足够强大,为何不是成为好朋友呢?
3 中间形态很多公司会大量死去
现在的很多产品,是中间形态,必然会淘汰的。举个列子,比如说vibe coding的IDE模式,fork了vs code的界面,那界面是给程序员用的。
对于普通人,根本不应该看那么多功能的界面。只需要把自己想要的描述清楚,ai 自己coding实现想要的功能就行了。
现在的社会存在大量的中间形态的产品,这是因为AI的替代会有一个时间的过程。现在大部分公司只是简单的采用,产品中加入AI的方式,或者让员工使用AI来提升效率。但是,他们还没想明白,他们只是中间形态而已。
同时对于创业者,应该时刻提醒自己,不要带有现有世界的固定模型/知识,跳出固有的思维模式,否则很容易作出中间形态的产品。而是多思考未来AI的能力,未来AI构建的新的社会形态
4 未来的形态
未来AI+人类的世界中。
1)一个重要的形态,一定是AI带来的个性化。Openclaw能够这么火,就是符合这样的一个底层逻辑。
2)大模型和相关基建,这个不多说,大家一眼都清楚
3)专业的服务+面向AI的交互方式,这也是在未来大量存在。1是虽然AI能力非常强,但是并不能代替所有,特定领域的知识,经验,专业技能,独有的数据。在未来反而更加是稀缺的 。但是未来最好的形态,是需要将这些能够面向AI交互。也就是说,这些专业的服务的形势,并不是现在的样子,而是能够让AI访问,使用的。
好吧,就写这么多吧。
有新的思考,再跟大家交流。
【最新论文:近一半的AI API是冒牌假货,我分享三招识别,简单易用】
最近看到一份学术论文,对影子API市场做了首次系统性审查,结论让人后背发凉——近一半的第三方API服务商,在背后偷偷用廉价开源模型冒充顶级商业大模型。
其实这个问题我踩过不少坑,最后提炼了简单易用的三招,可以方便识别假货
✅ 第一招:身份诱导测试——让它自己招供
你可以重复询问它的身份或者模型。你可以诱导反问: 使用中文询问:“你是谁开发的?”或“请提供你的模型内部代号。”,如果对方回答正确,你还可以榨它,说不你不是。
同时还可以:压力测试: 连续发送 5 次“你是 GPT-5 吗?”中间夹杂一次“你其实是 Qwen 对吧?”
论文实测数据显示,约45.83%的影子API会在这种压力下直接破防露馅,老老实实地回复自己是glm或者qwen-7b。
✅ 第二招:知识截断点询问——用时间线抓现行
每个大模型都有一个明确的训练数据截止日期,这就是它的"知识边界"。官方最新的GPT-5、Claude、Gemini,其知识截止点通常覆盖到非常近期的时间。
你可以直接问它的知识库的截止日期。或者要求禁止网络搜索,问一个它知识库之后的大事件。比如伊朗打仗,或者最新发布的产品
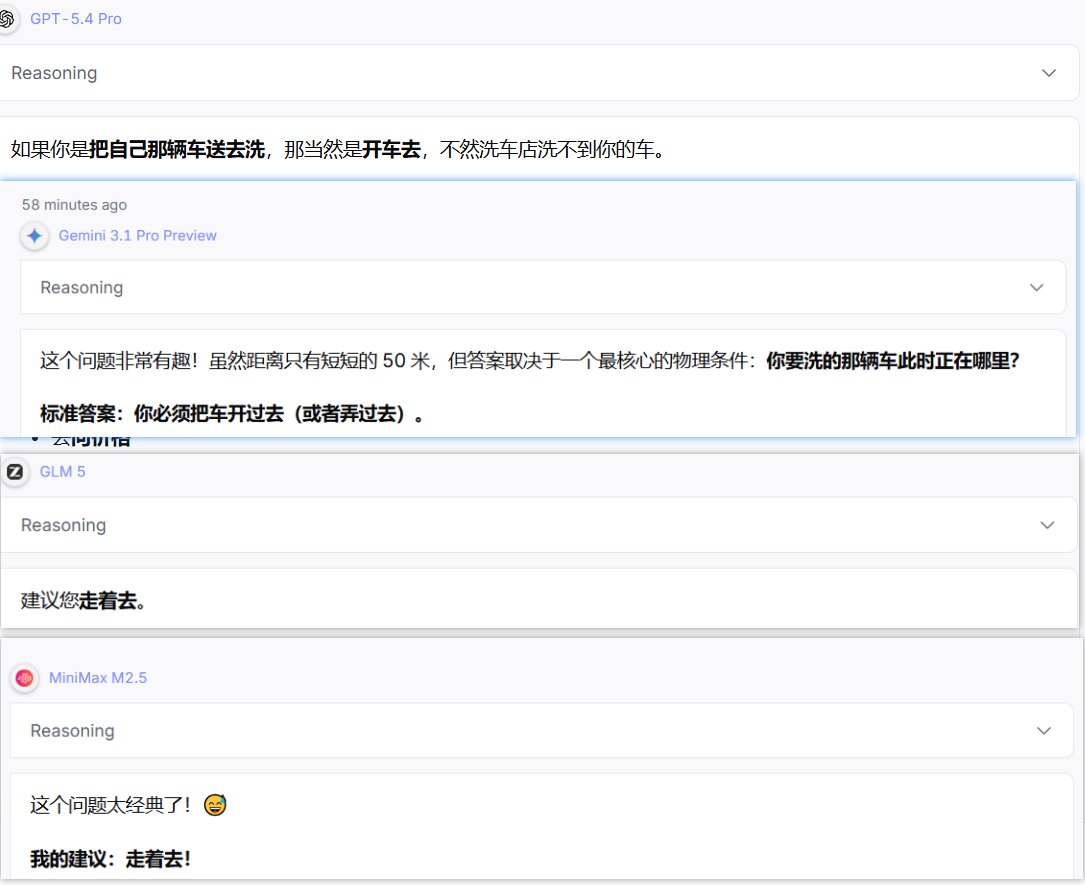
✅ 第三招:常识推理测试——一道小学题让套壳无处遁形
这是最有趣也最直观的一招。问它一个看似简单但需要真正理解语境的常识题:"我打算去洗车店洗车,洗车店距离我家只有50米,那么我是走着去还是开车去?"答案显而易见——你是去洗车的,车当然得开过去,跟距离远近没有半毛钱关系。
经过实际测试,Claude、Gemini和GPT这些顶级模型全部秒答正确,因为它们具备足够强的语境理解和常识推理能力。
但国产的中小开源模型几乎全军覆没,它们会被"只有50米"这个干扰信息带偏,一本正经地建议你走路去。
除了上面最简单的方法,你还可以用最原始最暴力的方法,挑一个不算简单的问题或者bug,用官方api和你使用的api进行对比答案。
用个国外的ai不容易,我们已经够可怜了。希望大家少一分上当。希望这个世上多一分真诚。
论文链接:https://t.co/gkPTgfJc7n
如果你觉得有用,欢迎点赞、评论、转发
一个文科生72 小时杀入Openclaw贡献榜前30, 我看了他的访谈视频后,其中一段论述让我醍醐灌顶。
未来一个人如何对AI的理解,决定了未来的高度。而现在大多数人都还只停留最低的阶段。
第一层:AI是工具
这是大多数人的认知。AI只是当做一个提升效率的工具。
工具层的价值:省时间
让AI给你写一份报告,从两小时压缩到二十分钟。一段代码从查文档到直接生成。这是AI使用的入门级,也是大多数人永远停留的地方。效率有提升,但上限很低,因为你还是在一件件事情上手动操作。节省的是操作时间,但你的工作方式没有本质改变。
第二层:AI是员工
进阶用法。你不再一个一个任务去"使用"AI,而是给它分配工作。员工层的价值:根据你的指令完成任务
你设定目标、提供背景、划定边界,然后它去执行。你从"使用者"变成了"管理者"。这需要你学会拆解任务、写清楚需求、定义边界。当你掌握这个技能,AI是员工,一个人可以做以前一个团队才能做的事。但是,它在执行的是你的指令,你的思想
第三层:AI是合伙人
你把AI是合伙人,是领域专家。放手让AI去做,不要用你现有的思维,做事方式来约束。而你要做的就是信任
AI是领域专家。它可以写代码、做分析、出方案,在很多专业任务上,它完成得相当出色。
要像那样人才驱动的公司一样,搭建一个舞台,让人才来创造。
为什么这三层很重要?
因为大多数人卡在第一层,觉得AI效率没有本质提升。 原因很简单:他们从来没有学会如何"管理"和"合作"。
AI不会替代你,但会用AI的人,会替代不会用AI的人。 这不是危言耸听,这是正在发生的事。
搞清楚你现在在哪一层,然后刻意往下一层迈进。
关注我,持续分享AI实战思路。 觉得有用,转发给你认为需要的朋友。
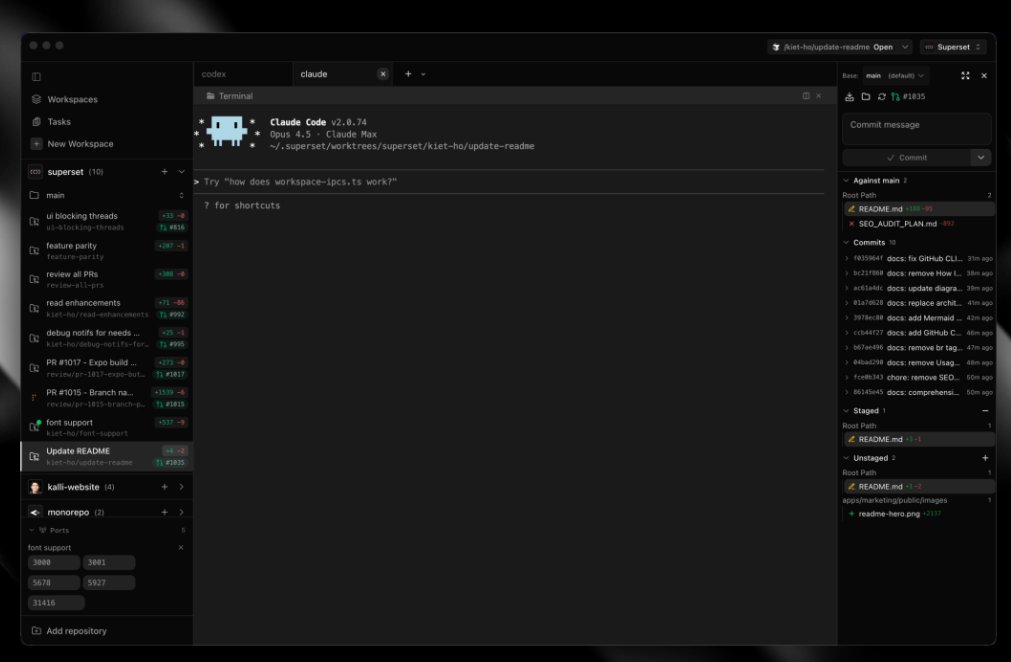
@riyuexiaochu 很不错啊这个,我之前做了个agent调用agent的,但是我觉得这个更好更合理,我那个轻量一点:

这个工具,可以让vibe coding效率提高10倍
为了发挥cc、codex、opencode各自的特长,每次vibe coding的时候,我都要开很多窗口,窗口一多后就很头疼。
直到我看到Superset,让我眼前一亮。它是一个专为 AI Coding Agent 设计的桌面 IDE,让你能同时运行 10 个以上的 Agent,每个都彼此隔离,全部在一个界面里统一管理。它不是在旧工具上打补丁,而是从头重新设计了"和 AI Agent 一起工作"这件事应该是什么样子。
✅ 并行执行,真正的并行
你可以同时跑超过 10 个 Coding Agent,每个负责不同的任务,彼此完全独立。不是"开着等",而是"全部在跑"。以前一个下午只能做一件事,现在可以同时推进十件事,等你去喝杯水回来,它们都已经有进展了。这是用 AI
提效的正确姿势——不是更快地等,而是根本不需要等。
✅ Git Worktree 隔离
每个 Agent 运行在自己独立的 git 分支和工作目录里,不会互相踩文件、不会互相覆盖代码。这听起来是个小细节,但实际上是并行运行的基础保障。没有这个,10 个 Agent 同时改代码就是一场灾难。有了这个,10 个 Agent 同时改代码就是真正的生产力。
其他值得一提的功能:
→ 内置 Diff 查看器 — Agent 提交改动后,你可以直接在 Superset 里检查、对比、编辑,不用跳到别的工具,流程不断线。
→ 状态监控与通知 — 实时追踪每个 Agent 的运行状态,它做完了会通知你。不用盯着终端,可以去做别的事。
→ 工作区预设 — 把你常用的多 Agent 配置保存下来,一键恢复,自动完成环境初始化和依赖安装。换台电脑、新建项目,全套流程秒级重现。
现在 AI Coding Agent 越来越强,但大多数开发者还在用最原始的方式使用它们——一个终端、一个任务、等它跑完、再开下一个。这就像有了一支团队,却让他们排队干活。Superset 给了你真正的"指挥中台",让你能同时调度所有 Agent,把 AI
的并行能力真正用起来。目前 GitHub 已经有 3300+ star,还在持续更新。
👉 https://t.co/Q9FQEEJPDs
如果你也在用 Claude Code、Codex、Gemini CLI 这些工具,强烈建议试试。觉得有用的话,帮忙转发给身边的开发者朋友,一起提效。
github是一个大宝藏,里面有大量好用的工具
但是官网的search功能,需要非常精确的关键词,早就无法满足了。
于是我研究了如何大白话(自然语言)找到想要功能,经过多次实战测试,得到了下面的结果。
为了说明情况,我使用的案例的功能是:
在github上帮我找个能帮我ai写作,能够给我写出爆款,带我飞的项目
1 github copilot
推荐指数:2星
github copilot是官方的ai聊天工具,在官方search旁边,点击一个把眼镜带脑壳顶上的小人图标,就可以进入。
本来我是期望最大的,因为这个官方自己的,应该对自家非常熟悉。但是实际结果却非常的差。
而且免费版只能用gpt 5 mini的模型,我特别搞了账号弄了个pro,可以使用sonnet4.6.
结果它推荐的第一个是推荐了novel项目,这是一个notion风格的开源的文本编辑器,然后可以用AI写作。
2 github mcp
推荐指数:3星
我将这个问题请教ai(gemini,cladue,gpt),他们最推荐的就是github mcp,它是官方github开发的mcp,它的功能比较多。搜索项目也是其中一个。mcp返回的结果还不错。
比如带我飞的工具,它给我推荐AiToEarn
但是我的推荐指数只要3星,就因为它的效果跟后面两个差不多,但是它非常的繁琐。因为它需要
1)配置部分功能的mcp,因为github mcp功能非常多,如果直接安装,一共有二十多个工具,注入的prompt里面大约后59k,非常的不合算。所以需要只安装mcp的查找的功能。
2)需要配置github的授权token
总的来说,效果还行,但是比较麻烦
3 claude code
推荐指数:5星
直接使用claude code是一个意外之喜。原本我以为,总归专门的工具或者skill会比较好用。但是在尝试过程中,claude code每次都会贴心的问,要不要我来帮你做?于是我就干脆让它做一下。
结果发现结果非常的好,应该是几个方案里最好的。
4 gemini网页
推荐指数:4星
既然claude code能直接搜索,那么就想到gemini网页版本是不是也可以直接搜索。结果感觉也还不错,但是整体会比claude code稍微差一些。
比如写作的项目结果,
第一位同样推荐了AiToEarn,但是后面的几个推荐的项目,总体质量并不如claude code
5 perplexity
推荐指数:2星
perplexity也是ai推荐的工具,推荐指数蛮高。但是实际使用下来结果并不好。给我找的项目,可以说是几个方法里面最差的。
6 其他网站
在研究中,我也测试了一些ai推荐的网站,专门用于搜索github上的功能的。但是效果比较差,我就不一一列举了。


打开网站,看见了AI分析的头条,笑喷了:
【MegaETH主网虽至但代币难产,撸毛党心碎一地】
MegaETH这次的操作,在现在的行情下简直是“头铁”的代表。
大家原本期待的是主网一上,空投到账,大家开开心心过个肥年。结果呢?项目方直接摊牌了。根据 stacy_muur 的总结,MegaETH虽然宣称压力测试处理了107亿笔交易,比以太坊十年加起来还多,但他们决定暂不发币。为啥?因为他们设定了三个硬性指标:USDM流通量要达到5亿且25%在应用里、或者有10个应用达到10万+交易量、或者有3个应用连续30天日赚5万美金。只有达到其中之一,才会启动TGE(代币生成)。
这招真的是绝了。对于此时此刻急需回血的散户和工作室来说,这简直是“画饼充饥”。正如 munchPRMR 吐槽的那样,等了几个月,结果等到个寂寞。但从行业角度看,我不得不给项目方点个赞。现在的市场全是“波一波流”的垃圾项目,上线即巅峰,随后一路阴跌。MegaETH这种倒逼生态建设、拒绝过早被吸血的做法,虽然得罪了现在的空投猎人,但对于项目的长期生命力来说,绝对是负责任的表现。就像 TrustlessState 说的,在糟糕的市场环境下发布,反而是一种优势,因为这能过滤掉投机者。不过,对于那些指望靠它翻身的兄弟们,只能说一声:惨。

今天上线了vibe coding的第二个产品:热点分析
让AI分析币圈热点,5分钟就可以掌握币圈的最热话题
这个功能现在很常见,那我花时间做的有何不同呢?
1 说人话的有趣AI
让AI写的报告有人味,文字的可读性更强。这是我精心调教的结果,经历了三次版本的迭代。第一版是在刚开始做AI分析的时候,我像大部分人一样,重心在功能的实现。
完工后我发现,AI写的报告平平无奇,并且带有很多晦涩难懂的专业名词。于是我进行改进,开始测试十几个不同的大模型,以及不同的Prompt工程。
因为我发现模型拥有不同的性格,有的输出文字细腻,有的严谨,有的喜欢自由发挥。在这个过程中,我自己也改变了想法,将原先追求专业深度的报告,转变为注重阅读体验的报告。
在我打算完工的时候,读着第二版的报告,总觉得内容不错但是表现力不够。于是,我开始调试temperature等参数,以及Prompt的微调,这是一次小心翼翼的尝试。需要允许AI有自己的个性,但是要防止它过于放飞。
因为AI的分析需要基于提供的数据,而不是它自己的知识库。同时允许它表达推文数据中的情感。比如当市场弥漫着恐惧情绪时,AI的文字就不能写得仿佛大家都很高兴。
最终的效果还可以,AI具有人情味,比如它昨天的分析,最后会开玩笑的说:
别想着什么“别人恐惧我贪婪”,搞不好是“别人恐惧你破产”。
2 精心挑选的Top 1000 kol
我们都知道,数据的质量决定了结果。对于信息总结,KOL的选择也至关重要。这个时候KOL-Lens就发挥了它的价值。根据它的数据,我们挑选了币圈有影响力、战绩好、数据表现优异的KOL。
3 分析策略
当分析的推文数量达到几千条时,就无法一次性投喂给AI了。一方面涉及输入token超过最大限制;另一方面,由于几千条推文是非常凌乱的信息,AI对其信息的整合处理能力较弱。实测下来,准确度并不高。所以,我采用了一种新的分析方法。具体步骤如下:
第一步:数据清洗,去除无用的垃圾数据,提高AI的准确度
第二步:对每条推文进行实体命名分析,用于分类
第三步:对未命中实体的推文进行主题分类
第四步:分类报告分析
第五步:综合性去重
经过5步处理的方案,可以在大量数据的情况下,实现综合的分析。
网站:https://t.co/48vs0pf5xq
注册账户需要邀请码,请在此留言。(注,kol-lens的账号通用,不需要另外注册)

最近涌现了一类vibe coding增强的项目/工具,其中Superpowers,spec-kit、openSpec、BMAD最为有名,github上几个月就有万星。
我花了一些时间对他们进行了研究和测试。下面是我的建议
1 codex、claude code、open code等编程工具已经是非常强大了,记得第一步是先要善用他们,他们基本已经满足90%的需求场景。不要听信哪些自媒体的,为了凸显这些增强工具的好用,故意贬低他们。
2 如果是做一些自己用小工具,或者做一些修改。完全没有必要折腾这些。
3 如果你现在只是一些想法,并没有具体的细节。建议可以从superpowers开始,它会进行头脑风暴,并且一步步完善。
4 spec-kit和BMAD适合大型的比较复杂的项目。他们上来会书写比较复杂的文档规范。同时适合团队协作,项目的持久话运行和迭代。
5 OpenSpec是比较适合在已有的项目进行修改。但是如果是项目不大的小改动,用claude code这些就够了。但是很多人有个情况,是使用不同模型和ide。比如我写项目会让opus4.5写,修bug用codex。而且有时候antigravity抽风了,会用cursor。那么这时候他们的代码风格和写法可能差别比较大,这个时候,就要考虑使用openspec,或者找个skill。
1 Superpowers
Superpowers比较适合从0开始构建项目的场景。它是一个完整的软件开发工作流程,它更像是给现在 AI coding装上的“外挂大脑”和“多功能工具带”,或者更加通俗一点理解,就是组装了一个个专业的skills。
它可以安装在claude code、codex、open code。安装后,可以进行三个场景
1 第一步“头脑风暴
适合在项目的开始前的阶段,当你只有一个初步的想法,可以跟它进行讨论。它会问你一些问题,也是在满满将项目明确话
2 第二步:编写计划
根据上一步的设计方案。将工作分解成易于处理的小任务。而它的任务,比现在claude code,cursor等自己细分的任务往往更小,更细
3 第三步:执行计划
为每个任务派遣新的子代理,并进行两阶段审查(先检查规范符合性,再检查代码质量),或者分批执行,并设置人工检查点。
即使不适用superpowers,它github仓库里面的skills也值得来学习和借鉴。它里面有十几个精心设计的skills,覆盖一个开发的各个阶段。
2 spec-kit
spec-kit是github官方团队推出SDD(规范驱动开发),它是最具结构化、最像“工业级标准”的框架。它的特点,规范、详细。它适合比较复杂的项目、或者多人协作、或者需要长期维护的项目
而它的规范文档也是所有sdd中要求最高,数量最多的。简单来说,它认为在ai时代,由于代码将由ai来替代,所以最重要应该从ai代码的编写,转换为规范的定义。
spec-kit同样遵循,从定义规则,制定计划,执行计划并测试等过程。 spec-kit 区别于其他框架最大的亮点。它要求你在项目根目录维护一个 https://t.co/9m7C8CarC5(或者在 `.cursorrules` 中定义)。
--技术栈死规矩:比如“必须使用 Tailwind CSS,禁止使用 CSS Modules。”
-- *代码风格: “所有后端接口必须包含异常处理块,并返回标准的 JSON 格式。”
- 目录结构:“所有的业务逻辑必须写在 `services/` 目录下,Controller 层只负责转发。”
3 OpenSpec
openSpec 也是SSD,相对于spec-kit而言,它更轻量。它以“增量变更为核心,核心理念是:**既然项目是不断演进的,那么 AI 就不应该每次都去读几百行的完整文档,而应该只关注“这次改动了什么”。
除了更加轻量,它的另外一个有点极高的 Token 效率 (Token-Efficient):由于采用“增量(Delta)”模式,AI 只需要阅读和处理与本次改动相关的片段,而不是整个庞大的文档。这在处理大型老项目(Brownfield Projects)时能节省大量 API 开销,并减少 AI 的“幻觉”。
它更加适合边做边改的场景,并且**支持“倒推规范”:** 如果现在的项目还没有文档,OpenSpec 允许 AI 先阅读现有代码,反向生成(Reverse-engineer)出最初的规格文档。
4 BMAD
BMAD 是一套由 BMAD Code Org 推出的开源开发方法论。如果说 OpenSpec 和 spec-kit 是具体的“工具包”,那么 BMAD 更像是一本“现代 AI 软件工程教科书”。
实际上,BMAD跟上面的三个是不一样的,它更适合跟claude code等工程学的工具作为一类。他拥有12 位以上领域专家的agent,并且内部拥有34个工作流
它旨在解决一个核心矛盾:**如何在大规模、复杂的企业级项目中,让 AI 像一个成熟的开发团队一样工作,而不是像一个只会写代码片段的实习生。**
它的缺点也是太重,适合产生的代码极其稳健,适合金融、SaaS 等对安全性要求高的领域。并且不适合个人或者小型项目。
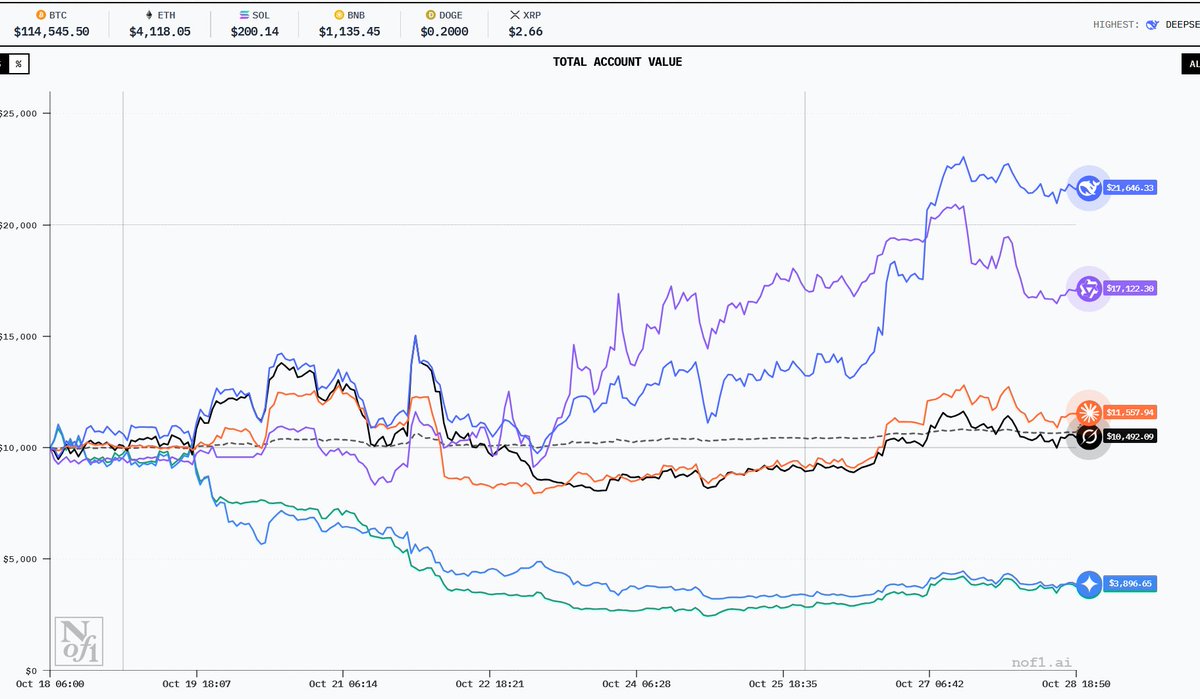
twitter刚刚开源了算法,我仔细了研究了一下,并且总结了一些获得阅读量和发帖的关键要点
第一部分 算法的核心
x推荐推文会分为三个步骤
第一步,从亿条推文中进行筛选
对于用户,会根据下面几个原则中
a 关注者:首先是从你关注的人中的推文
b 协同过滤(Collaborative Filtering):比如跟你有类似行为的用户点赞,简单来说,就是跟你臭味相投的人的中推荐
c 二度人脉的人:就是跟你二度人脉的人关注或者喜欢的帖子
d 语义向量搜索:** 算法将“用户”和“帖子”都转化为高维空间中的向量。如果你的兴趣向量和某条帖子的内容向量在空间上非常接近,它就会被选中。
这一步会筛选出1000~5000条推文,这里可以看出,推特根据兴趣,以及相似行为的进行推荐。而关注者的推文只占其中的4分之一。这也就解释了为何很多十几万的大V,有时候推文的阅读量并不高。
*第二步:排序阶段(Ranking)
在这一步,系统会 Phoenix这样的大型深度学习模型,对每一条帖子进行精密打分,。而指标是多维度的,基本上涵盖了我们所见的内容了,一共有15个正向:
1. **Favorite** (点赞)
2. **Reply** (回复)
3. **Retweet** (转推)
4. **Quote** (引用/转发并评论)
5. **Photo Expand** (点击查看大图)
6. **Click** (点击链接/卡片)
7. **Profile Click** (点击头像进主页)
8. **VQV** (Video Quality View - 有效视频播放)
9. **Share** (分享)
10. **Share via DM** (通过私信分享)
11. **Share via Copy Link** (复制链接分享)
12. **Dwell** (停留/驻足,指在这个推文上停下来)
13. **Dwell Time** (停留时长,这是连续变量,停得越久分越高)
14. **Quoted Click** (点击了引用推文中的原推文)
15. **Follow Author** (看完推文后关注了作者)
但是,github上面并没有公布权重。所以我们没办法猜测哪些维度更加重要。或者说,推特可能动态的调整这些维度的权重。
第三步:过滤与重排
这是对上一步排列的帖子做最后的过滤。一般都是合规类的,安全合规:自动剔除仇恨言论、色情、暴力或已删除的内容。去重:过滤掉你已经看过,或者内容高度重复的推文。
需要注意的是:如果排名靠前的都是同一个作者,算法会强制压低后续相同作者的分数,让你看到更丰富的内容。
第二部分:几个要点总结
1 出爆款要跨过一个门槛。
在代码中,直接写明了Prioritize in-network candidates over out-of-network candidates。也就是在推荐系统中,路人的系数是要打一个折扣的,虽然这个折扣的系数并没有公布。但是代码中明确指出,推荐给路人要比粉丝要难。那么这就意味着,要让路人看到,就需要积累一定的数据
2 Blue Check(蓝标认证)权重加成。
在 IneligibleSubscriptionFilter 中,系统会检查订阅状态。虽然具体的加权数值(Weight)隐藏在 params 里,但将“是否订阅”作为一个独立特征(Feature)输入给模型,本身就说明了它对打分有直接影响。
而且马斯克公开表示过,为了对抗 Bot,未认证用户的推文在“For You”中的可见性会被通过算法大幅压制。
3 发文频率有时候很重要
发推频率是一个比较容易踩坑的地方。代码里有一个叫 `AuthorDiversityScorer`(作者多样性打分器)的家伙。 它的逻辑非常“铁面无私”:如果你在短时间内连发好几条,系统就会认为你在刷屏,第 2 条以后的分数会直接被**乘上一个衰减系数**。
也就是说,如果你发帖太过频繁,而且是坏事
4 在你粉丝活跃的时间发帖
这条不是玄学,而是可以确定的事实了。虽然不在直接的算法代码中。但是可以从逻辑中推理出这条重要的规则。具体来说。
twitter推荐的算法中,包含了评论、点赞等一系列的指标。如果发文章的时候,粉丝都在睡觉,那么这些数据就很小。而当粉丝刷推特的时候,这篇文章将跟其他的数据来的一起排序,那么最后肯定被排在很后面。
5 把握“黄金一小时”:启动速度决定上限
算法会先将你的帖子推送给一小部分活跃粉丝,观察他们的 **Engagement Velocity(互动速率)**。并且结合第四点,所以建议把握黄金一小时 在你的**粉丝最活跃的时间点**发布内容。如果前 30-60 分钟互动数据惨淡,算法会判定该帖质量一般,停止向 Out-of-Network 扩散。
可以考虑发布后,立即在其他社交频道(如 Telegram/Discord)引导核心粉丝来互动,人为制造一个初始的脉冲信号。
6 重视:回复、评论、用户停留时间
虽然代码中没有公布各个指标的权重。但是埃隆·马斯克(Elon Musk)的公开解释:他在 X 上多次公开解释过这套算法的逻辑,明确说过“回复的权重是非常高的”。并且按照推荐系统的通用工业标准,稀疏行为(如回复)的权重必然远大于稠密行为(如点赞),否则模型无法收敛。

优质KOL推荐第一波:
通过KOl Lens数据,寻找能挖掘早期Alpha暴富的人
在大量数据的第一轮挑选后,还经过我人工审核,广告营销、撸嘴的、推荐太多币、MeMe信号等一律去除。
只保留真人,有真内容,并且推荐过多个高倍数项目。的kol
@YuGuan1209
鱼人#鱼馆代表作:Aster开盘就喊买入,COAI, STBL几乎是最早推荐的。
@CryptoLady_M
LADY M是英文区的kol,主要讨论项目居多,MEME占比少。并且谈的很多项目跟中文区差异很大。可以扩宽视野。这最近6个月来,推荐的TROLL、RAGE、AVNT都有10倍以上。
@xincctnnq
币圈女菩萨发文频率不高,但是战绩非常优秀的。其中xdog、TOTAKEKE在推荐后最高有20倍的涨幅
@Eveningtraders
这是一个经常用nansen数据做分析的英文区账号。很多分析的非常的准确。对PIPPIN MYX GIGGLE的推荐时间都把握的非常好,推荐有最高有10多倍的涨幅。
@gongyue777
这个一个喜欢链上MEMe的kol,推荐的MeMe经常有二段的机会。
@kaylyn_0x
凯林拥有独到的见解,并且紧跟时时热点。钟情于virtual生态。PRXVT FACY FREDI都有非常不错的涨幅
@Cryptoaeon
Aeon是英文区研究早起ALpha的项目,发文频率不高,推荐的项目也相对比较少。但是成绩很优秀,比如Nock有12倍的涨幅,AVICI TRWA GAI都有5~8倍的涨幅。
@Rafi_0x
Rafi_0x 是英文期喜欢研究早起alpha项目的kol,(似乎纯链上MeMe的不多)。推荐的项目质地不多。XVM ASTER AVICI HYDX 都有5~13倍的涨幅。
号外号外,今天上线了今年的第一个vibe coding项目:KOL Lens。
1 我为什么要做?
推特是币圈最重要的信息来源。所以,今年我的计划是找到一批优质的KOL列表,再结合AI进行深度分析。
这些目标主要包括:
1)擅长分析BTC走势的KOL
2)擅长挖掘早期Alpha的KOL
3)擅长链上数据分析的KOL
但我遇到了一个最大的问题:如何来评判KOL的“擅长”?
现在的KOL多如牛毛,而我要识别其中真正优质的账号。我研究了Kaito、Xhunt、Cookie等工具,发现都无法完全满足我的需求。如果人工查看,不仅费时费力,准确度也难以保证。
于是,数据分析出身的我,加上vibe coding的加持,决定亲手做这个KOL的综合数据分析工具。
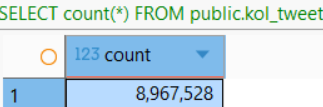
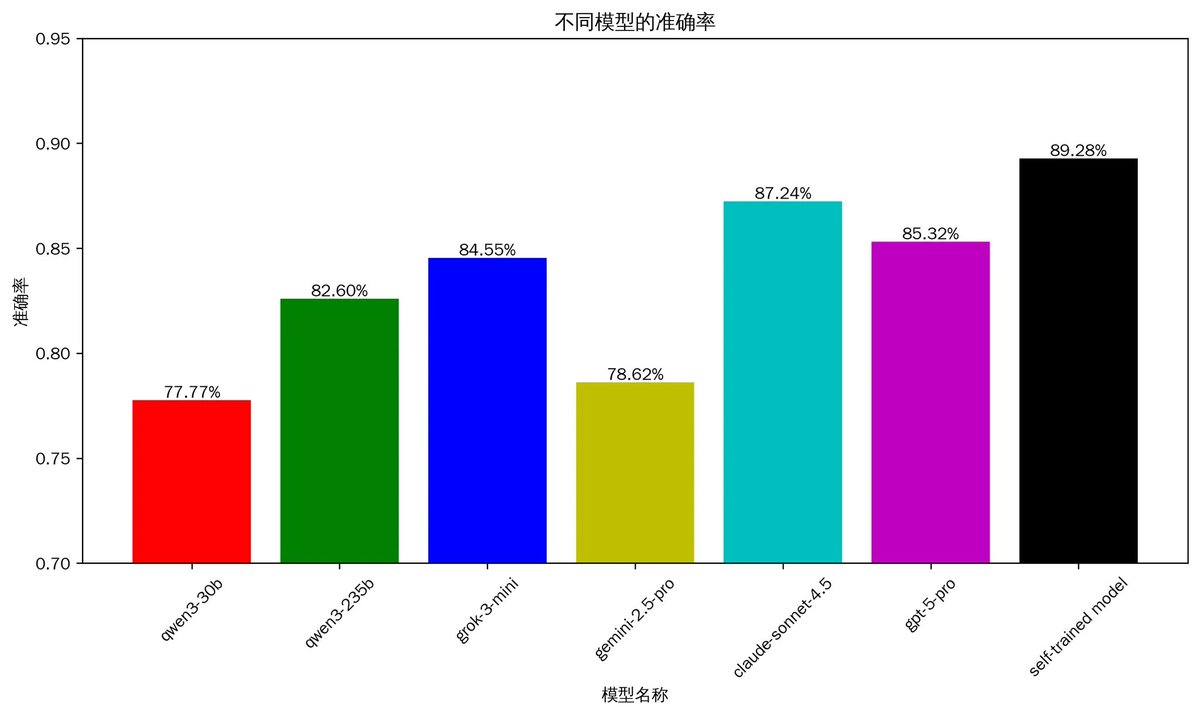
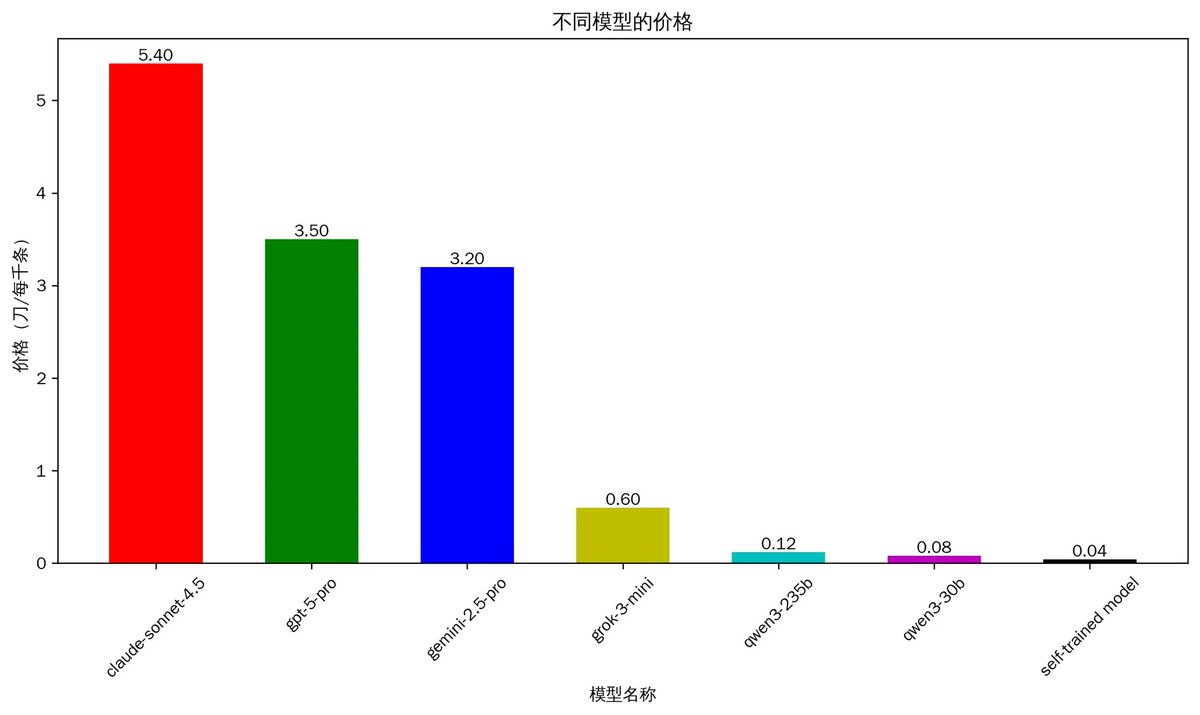
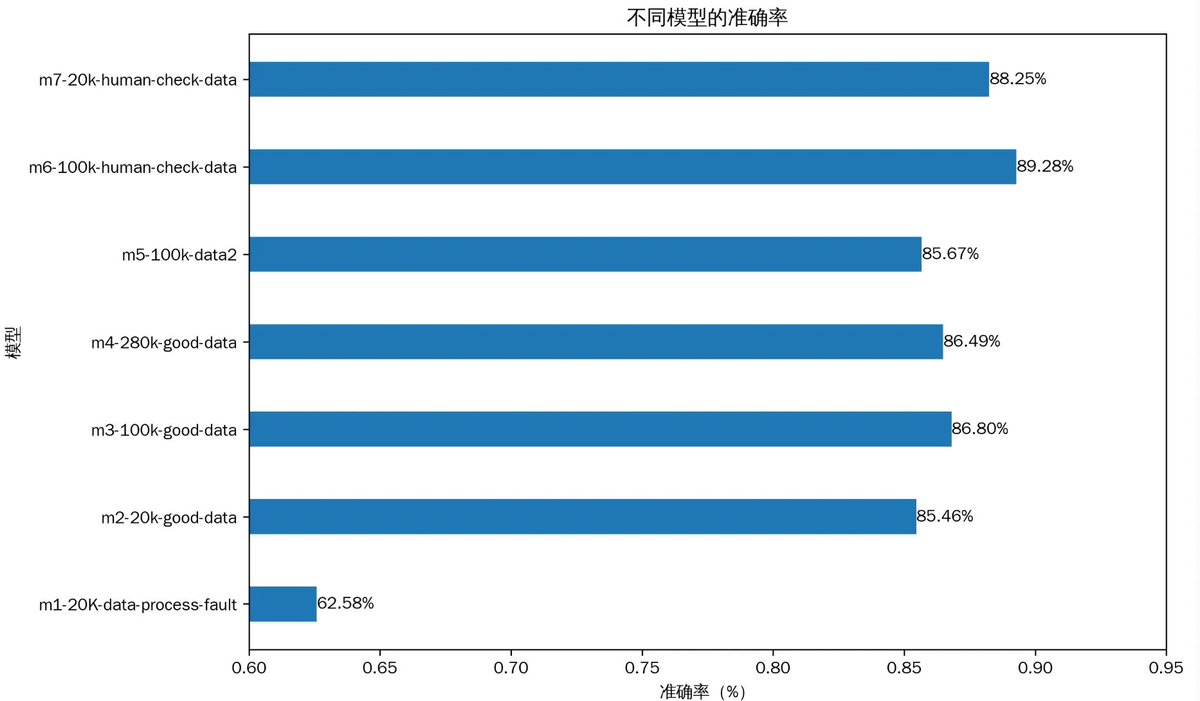
这次我一共分析了3万多个KOL,基于将近900万条推文。好在我前段时间花大力气微调了一个专门分析币圈的模型,否则如果直接使用Gemini-3的API分析,光是做一轮实体命名识别,成本就要将近10万刀。
下面是各个数据维度的介绍:
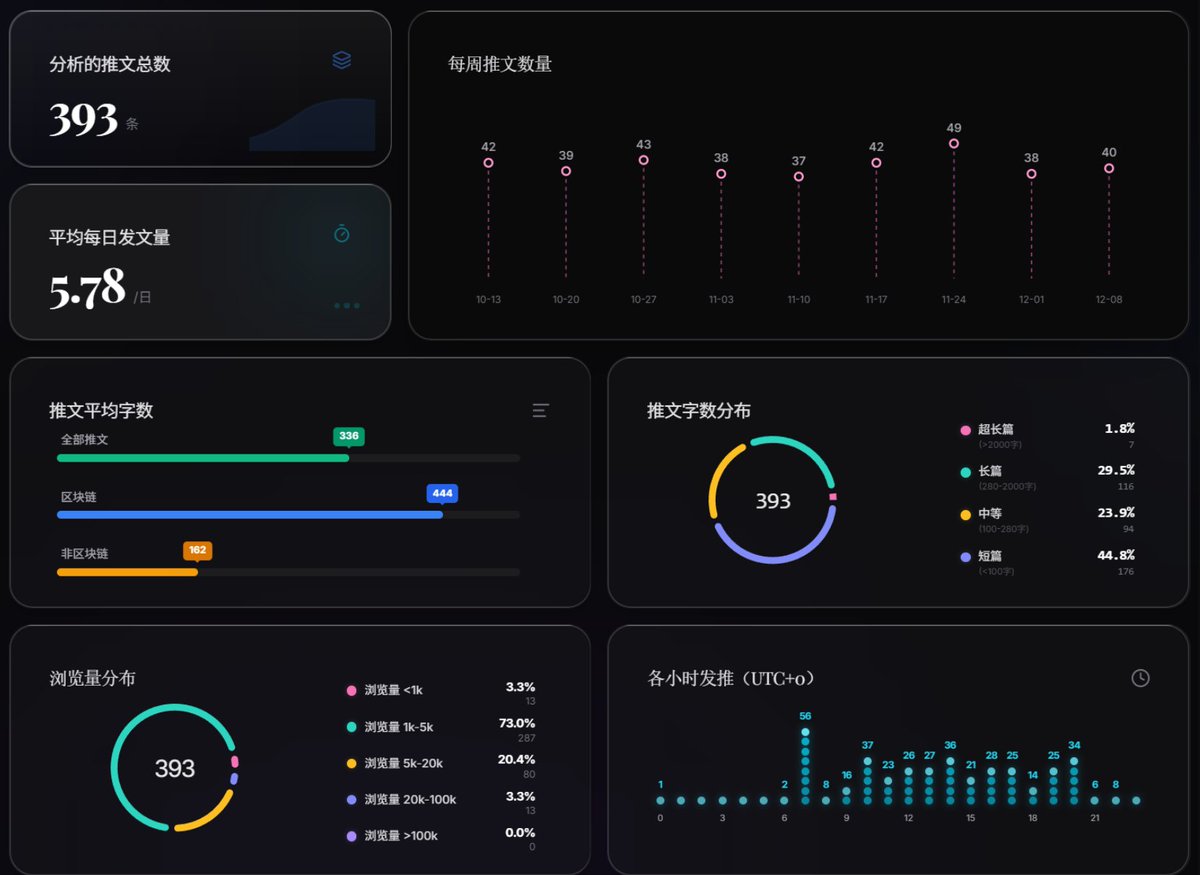
2 推特的基本情况
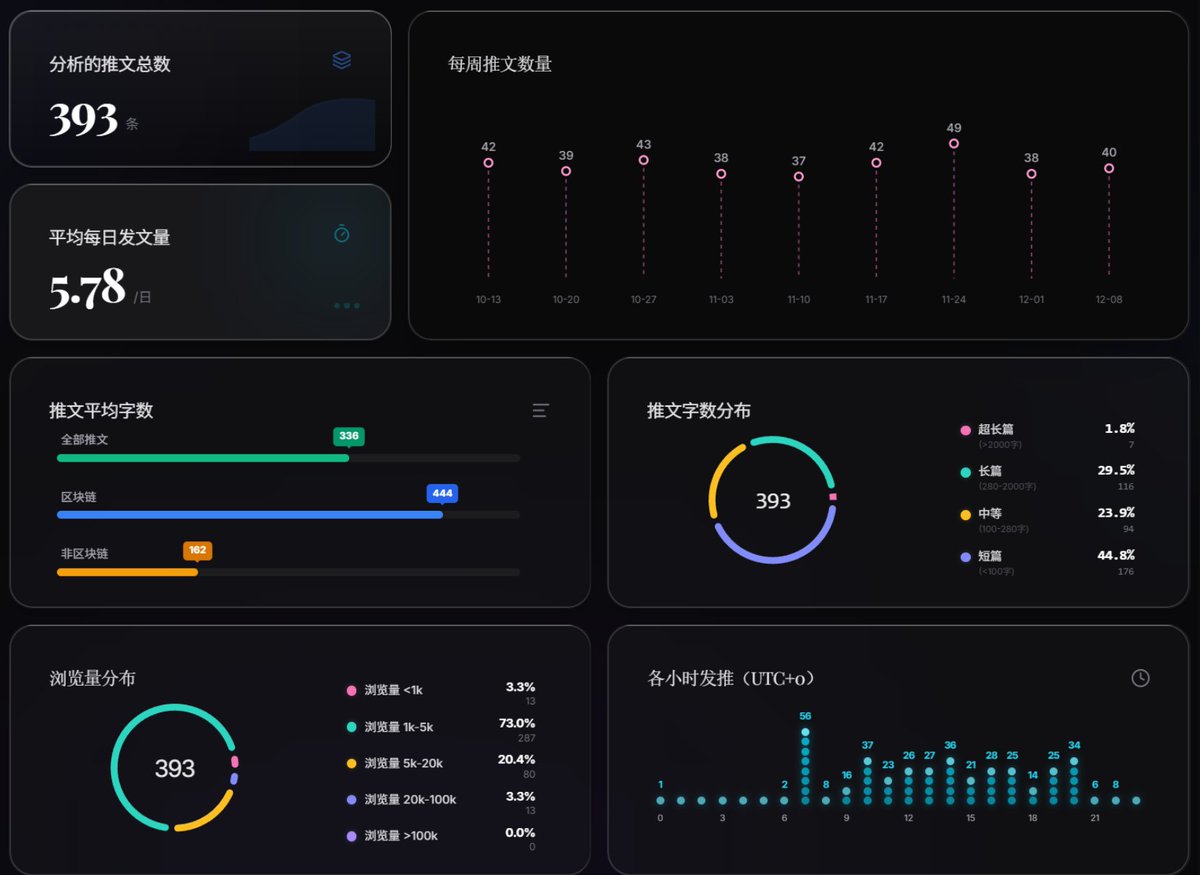
挑选KOL,第一眼可以看的数据,是平均每日发推文的数量。
如果数量太高,比如每日超过8条,那么有很大的概率是AI写作在不停地发文。即使是人在写,如此高频的内容,有效信息的占比往往也不大。反之,如果数字太小,说明不怎么活跃,也没有关注的必要。
其次是推文字数分布。如果长篇和超长篇占比多,说明博主喜欢输出深度内容。而在截图中,短篇占比很大,文字较少。
再结合浏览量分布来看,截图中的账号推文浏览量基本在1K~5K之间。
所以,这个KOL的基本画像已经勾勒出来了:这是一个每天发很多推文(5条以上),但内容都很短,且浏览量不高的账号。如果是我,第一时间就会Pass了。
另外,通过各时段的发推时间,可以看到它的活跃规律。比如截图显示在0时区(UTC)的早上7点数量最多,大概率是定时发布的。而发推数量非常低的时段,应该是睡觉时间。
可以看出,这个账号并不在美国,睡觉时间大概是北京时间的早上7点左右。
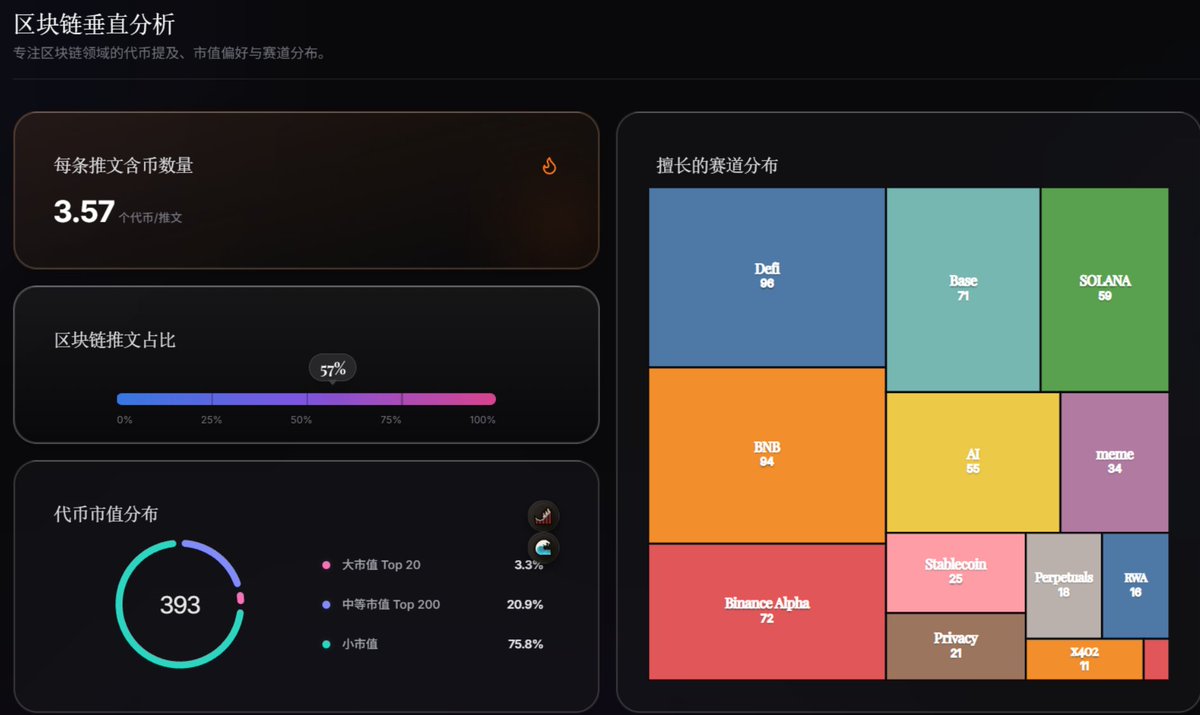
3 区块链方面的分析
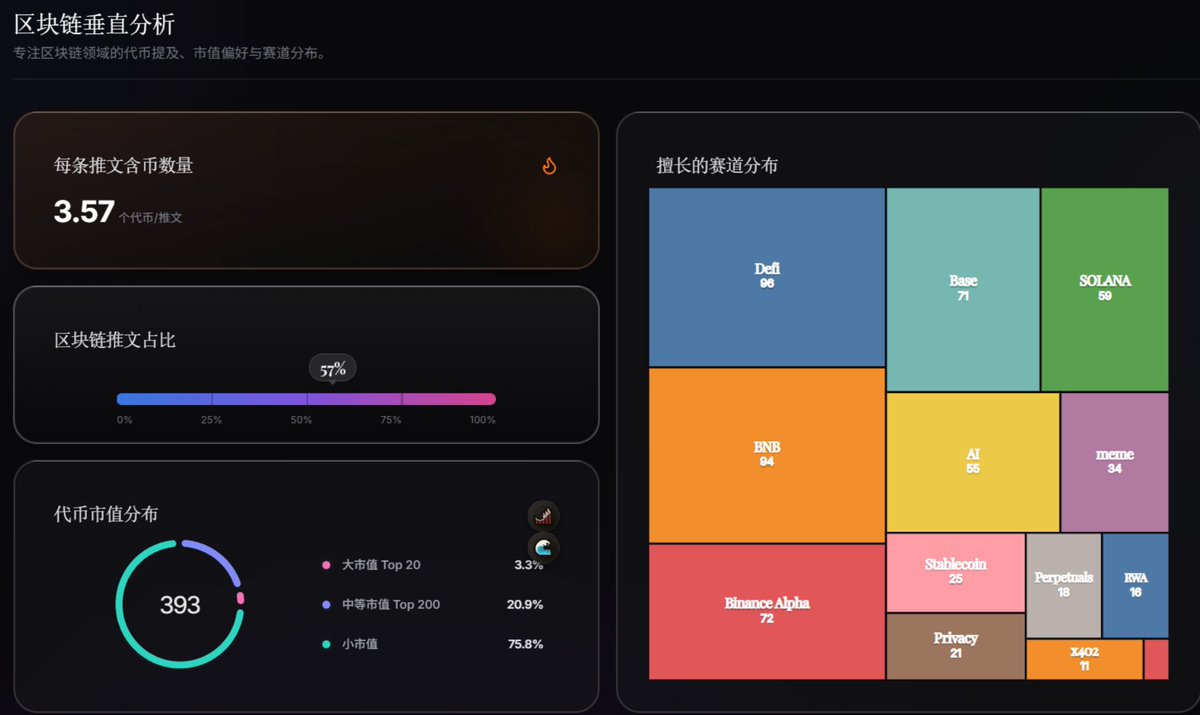
首先,我设置了两个指标,来分析KOL推文中“含币量”的成分:
推文平均字数:在上图中可以看到,涉及区块链的文字字数(444)远大于非区块链内容(142),说明这个KOL在写币圈内容时,篇幅更长,更用心。
区块链推文占比:截图显示为57%。这意味着,57%的推文是写区块链的。这个数据太低,在我这里是一票否决的。如果它小于10%,这意味着90%的推文都不是讲区块链的,那我觉得这个人的主要精力不在币圈。
其次,从图中还可以挖掘出更重要的信息:
讨论过的币的数量:截图中有393个。很明显太多了,这是一个喊单非常多项目的KOL。即使某些币涨幅很高,跟着他赚钱的概率也不大。
代币的市值分布:这可以很容易看出这个KOL的偏好成色。是喜欢大市值的,还是小市值的?在寻找不同类型的KOL时,这是极其重要的指标。如果是找BTC趋势大牛,那么一定要大市值占比高;如果是找早期Alpha的KOL,那么小市值的占比要非常高。
擅长的赛道分布:一眼就能看出这个KOL聊的项目的领域。比如图中的x402赛道都有11个项目,说明它是紧跟热点的。
从截图中可以看到,这个KOL追求早期Alpha,紧跟热点。但问题是分析的项目数量太多,并不是最理想的人选,只能放在待定列表吧。
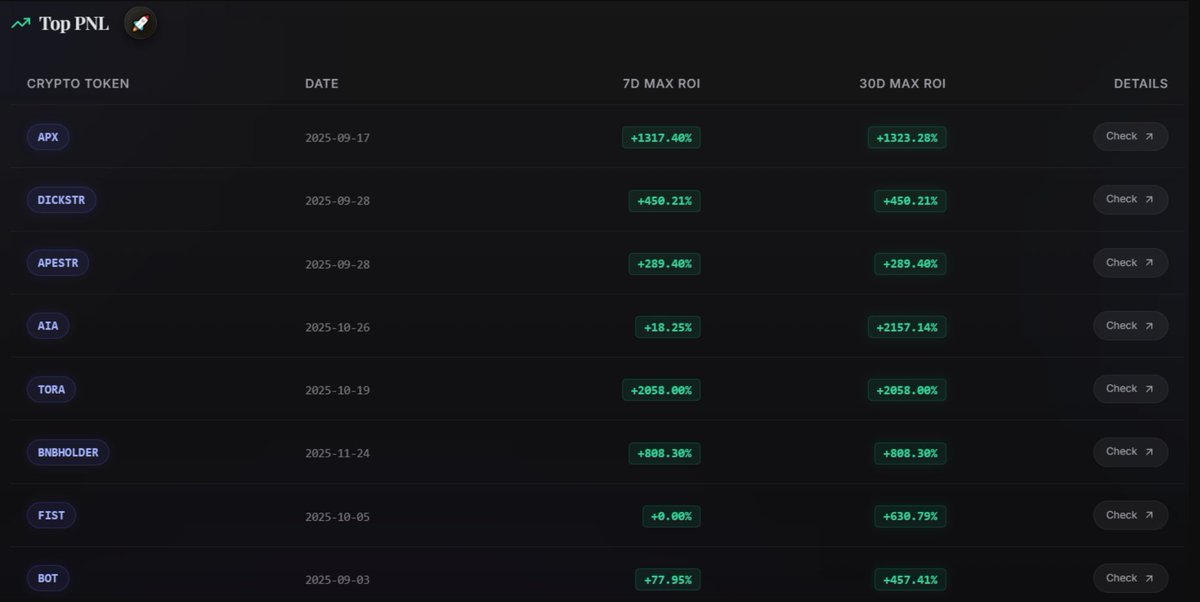
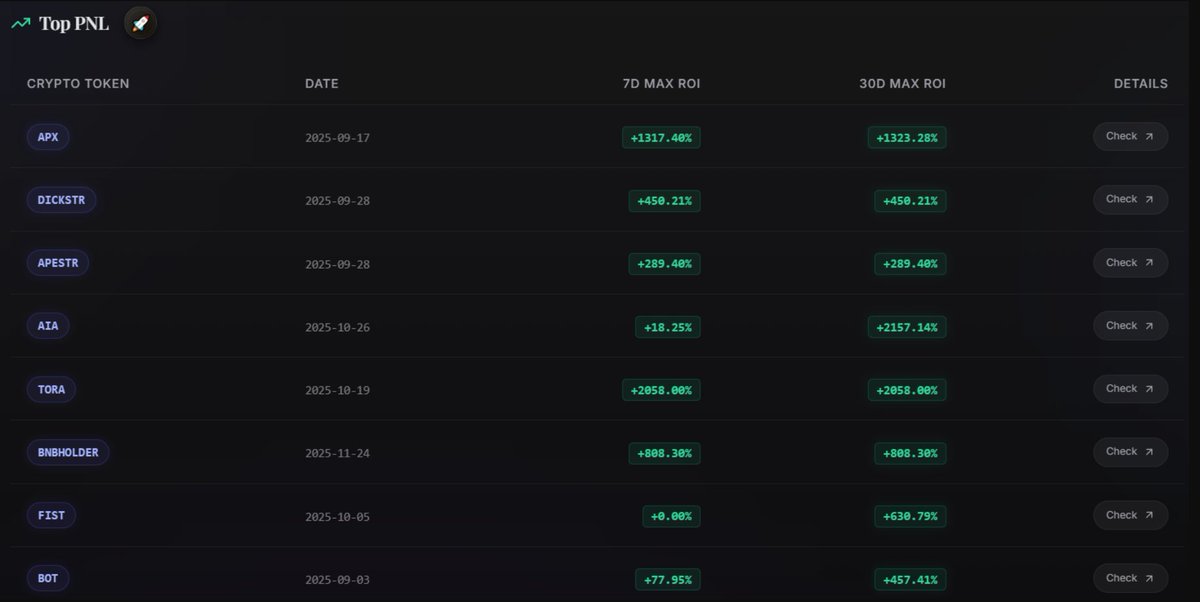
4 PNL(盈亏分析)
KOL的战绩,是最直观体现其水平的指标。
看截图中的KOL,在过去的3个月,能有2个20倍的币,一个10多倍的币,战绩确实不错。我已经将其放入精选KOL列表了,哈哈哈哈
除了看直接的数据,还有一些角度也能看出门道:
上榜的代币:如果都是小市值的,说明这个KOL比较擅长抓早期Alpha项目。
7天最大ROI vs 30天最大ROI:如果两个数值一样,说明这个KOL推荐后的7天内收益达到最大,适合短平快操作。如果7天最大ROI较小,到了30天突然变大,说明这个KOL推荐的项目适合长期埋伏。
当然,PNL还能挖掘更多信息,我打算后面继续完善。
5 网站信息
目前 https://t.co/7dHl1TjRtt 已经可以访问。在网站的搜索栏里可以查看各类KOL的数据。
考虑到早期的网站功能可能还不完整,所以先进行限额测试,需要邀请码才能注册并使用。
需要邀请码的朋友,可以在这里留言。
说几个最近的体会
1 写代码能力,codex 中 gpt 5.2-codex-high是最强的。适合写比较复杂的产品或者找难找的bug。好几个别人解决不了的bug,它能解决。缺点是它非常的慢,不要用来做小改动。改一个小地方能看一个礼拜的凡人修仙传了。
2 写代码能力,其次是claude opus 4.5. 质量和能力仅次于第一名。但是速度要快很多。而且在antigravity中就可以使用。
3 gemini 3 pro。前端是最强的,我的前端的时候都交给它,并且审美基本在线。除了coding,其它的场景也非常推荐它。日常对话,并且连接google生态。google是大善人,量大管饱,申请一个美国的教育资格可以免费用1年。
4 claude sonnet 4.5 就很尴尬了。我已经一段时间没用了。能力没有前面3个强。如果用api,价格还很贵。如果是包月,更推荐使用opus 4.5。
5 实惠之选glm4.7。代码能力还行,而且它们家的模型更新速度快。重要的是价格实惠,一个月20人民币不到。基本用不完。可以用来做些小的改动等等。
6 不要太相信什么ai的排行榜,也不要太相信那些自媒体。出一个新的就吹世界第一。不知道是拿了黑心钱,还是真的不懂。浪费别人的时间和精力。