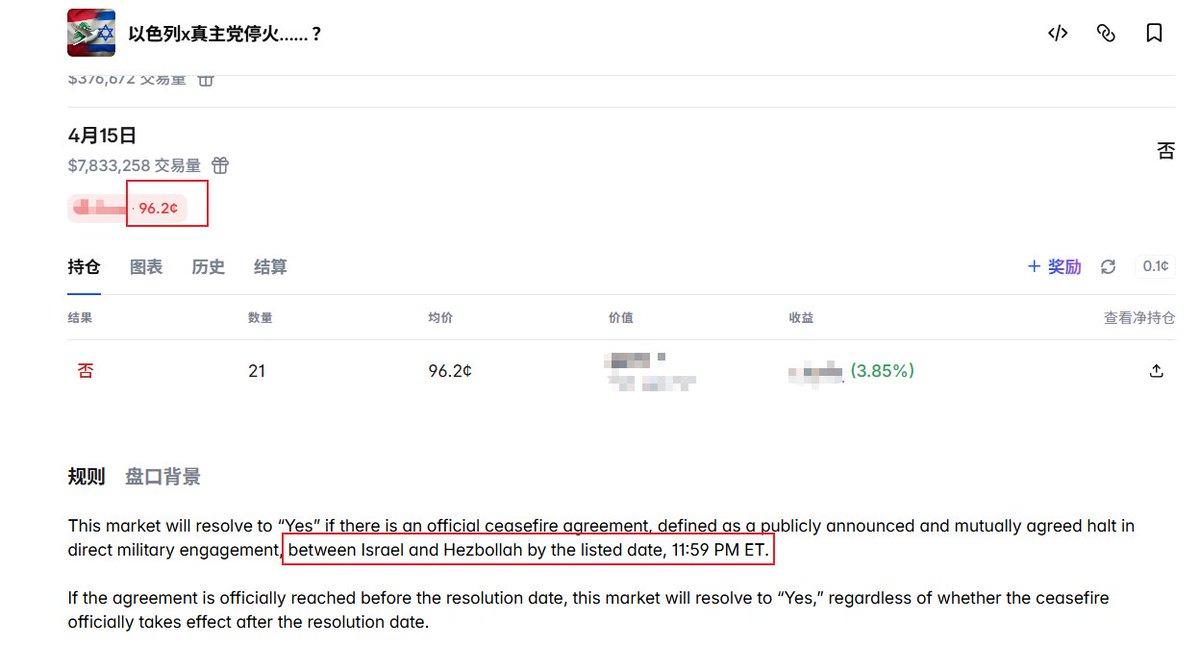
我昨天差点把实盘的亏损原因归到“买贵了”。
这个判断很顺:聪明钱先买,我们晚 30-60 秒跟,盘口一动,价格自然变差。可把账拆开后,结论反而变了。
我按每笔实际买入份额算成本差:我买入份额 ×(我买入价 - 聪明钱买入价)。
能匹配到聪明钱 BUY 的有 158 笔,其中 150 笔是精确时间匹配。结果是:买贵的部分确实多花 44.6719 U,但买便宜的部分节省 79.8196 U,净成本差是 -35.1477 U。也就是说,只看买入价,我们整体反而少花了 35.15 U。
这不代表入场速度不重要。短周期市场里,30 秒当然会伤收益。
但它提醒我:别因为几笔刺眼的“买贵”,就把整个亏损归因到买贵。收益差要拆开看:买入成本、漏买、漏卖、仓位规则,各算各的,最后再看净影响。
以前我会直接去优化入场延迟,或者放宽价格保护。现在我会先问一句:这项损耗在总账里到底占多少?如果不先算清楚,优化方向很可能是错的。
这次的结论是:买贵不是主犯。先别信直觉,先把账拆开。

为文章配好看的图片,昨天找了一圈,最后选中4个github开源的skills,做出来感觉还不错。
4个skill可以对应不同的场景。
说明一下,他们不是单独的skill项目,在baoyu和huashu的skill里面。
还有一个经验就是,codex直接画图效果要比调用gpt-image2画图,效果差一些。推荐用gpt-image2
1. baoyu-image-cards
- Skill 名称:`baoyu-image-cards`
- 适合场景:社交媒体图片卡片、知识卡片、轮播图、推文配图。
- 使用建议:适合把一篇推文拆成 1-3 张重点卡片,突出标题、判断点和结论。
2. baoyu-cover-image
- Skill 名称:`baoyu-cover-image`
- 适合场景:文章封面图、推文主视觉、标题大字图。
- 使用建议:适合每篇推文只配一张封面图时使用,重点放大标题和核心概念。
3. huashu-wechat-image
- Skill 名称:`huashu-wechat-image`
- 适合场景:公众号配图、文章插图、16:9 中文信息图、正文解释图。
- 使用建议:适合做中文准确、结构清楚的信息图,比如对比图、流程图、字段关系图。
4. huashu-xhs-image
- Skill 名称:`huashu-xhs-image`
- 适合场景:小红书风格配图、竖版社媒卡片、手机信息流大字图。
- 使用建议:适合做竖版图,标题要大,重点要少,适合移动端阅读。






跟AI的对话会成为个人宝贵的资产。
所以我做了一件产品呢,就是把AI的对话汇集成自己数据。CC和codex虽然都有自动总结功能。但是它只限自己对话。
而我的脚本可以claude code ,codex ,cursor,antigravity,opencode都汇总起来。
它可以用来
1)总结,
2)汇集skill优化,
3)查找历史记录
4)根据题材写成文章等等
它的流程是:先把所有 AI 工作记录编译出来(有些需要破译),再生成一份更轻的 manifest,然后只看 manifest 粗筛,最后再回到原始记录里精读候选素材。
这里的关键不是“让 AI 总结一下昨天干了什么”。
那样太粗。
真正有用的是先把阅读成本降下来。原始 JSON 很大,里面有完整回答、工具调用、路径、日志、过程。如果一上来全塞给 AI,它会被细节淹没,也容易把普通操作当成选题。
manifest 只保留几个东西:
用户当时问了什么。
AI 回复摘要的开头和结尾。
用了哪些工具。
这轮内容大概多长。
是不是明显低价值指令。
这样第一遍只做一件事:找“值得写”的事件。
比如这次筛出来的,不是“运行了某个脚本”这种流水账,而是几类真正能写的东西:交易系统对账口径错了、`market_missing` 其实不是找不到市场、推文配图不是先换模型。
这些都有一个共同点:有具体事件,有内容,有最后的处理办法。
这才是素材。
下一步再回 raw JSON 精读候选轮次,抽关键数字、用户追问、定位过程、最后结论。最后生成选题报告,让人来选。
人选完以后,还会把选择写回报告最前面。
这一步很小,但很重要。因为它让“AI 推荐过什么”和“我最后选了什么”连在一起。下次你再回看,不是面对一堆聊天记录,而是一条完整链路:
记录 -> 粗筛 -> 精读 -> 选题 -> 人工选择 -> 正文。
我越来越觉得,AI 工作记录本身就是一种内容矿。
但矿不会自己变成文章。
你需要先把它做成一张能被筛选、能被复盘、能继续加工的素材表。否则它只是昨天很忙的证据,不是今天能用的资产。
复盘的时候,发现追踪的polymarket聪明钱地址,最近2周,突然不聪明了。
原来V2版本 后,出现了新的钱包地址了。
Polymarket 在 `2026-04-28 11:00 UTC` 左右正式迁移到 CLOB V2。V2 后确实有新东西:新 Exchange 合约、新 pUSD、新签名类型,还有 deposit wallet。
但这不等于所有老用户都被强制换钱包。
老的 proxy wallet / safe wallet,一般还能继续用。真正复杂的是新 API 流程里的 deposit wallet。
如果某个用户开始用 deposit wallet,下单时你看到的字段可能会变:
`maker` 可能是 deposit wallet。
`signer` 可能是 deposit wallet。
`funder` 也可能是 deposit wallet。
而你原来跟踪的地址,可能只是旧的 proxy wallet,或者 Data API 里的 `proxyWallet`。
这就麻烦了。
我看了一下项目里的 M2/M3 采集脚本,它们从官方接口里拿的主要是 `proxyWallet`。但这些接口没有直接返回:
`depositWallet`
`walletType`
`signatureType`
`maker`
`signer`
`funder`
所以只靠这两个接口,很难判断一个地址是不是已经切到了 deposit wallet 流程。
这对聪明钱跟踪很重要。
你以为你在跟踪“这个人”。
但代码里实际跟踪的,可能只是某个展示地址。
V2 后真正发生交易的地址,可能在订单字段或链上资金流里。
所以我现在会把地址分成几层看:
展示地址是谁。
订单 maker/signer/funder 是谁。
有没有 deposit wallet。
资金有没有从旧地址流到新地址。
这个新地址有没有继续在 V2 CLOB 交易。
一句话:
V2 后不要只问“聪明钱是不是换地址了”。
要先问:“我现在跟踪的这个字段,到底代表哪一种钱包?”

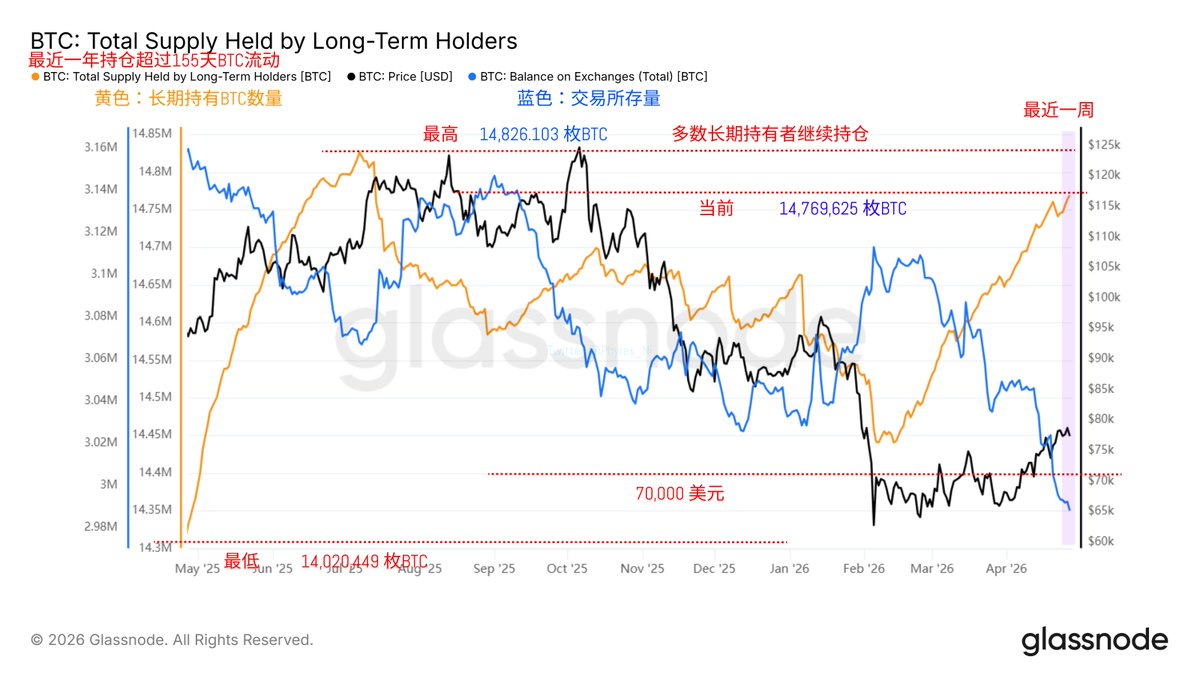
我昨天踩了一个很典型的 PnL 坑:现金流看起来亏了 335 万,但它根本不是每日收益。
事情是这样的。
我拿 5 个 盈利最高的Polymarket 地址,按 activity 流水算最近 14 天表现,结果合计是 -3,350,709.97。第一眼看,很吓人,像是这批地址 14 天亏了 335 万。
难道是翻车了吗?
研究了半天才意识到有个关键问题:
买入没有卖出的仓位,只是现金流流出,不等于当天亏损。
如果一个钱包今天花 10 万买入仓位,系统只看流水,就会看到 -10 万。可这个仓位还在,可能明天涨,也可能下周结算。你不能因为钱从余额里出去了,就直接说它今天亏了 10 万。
更明显的是,同一批地址按一个月 activity 公式算,结果是 1,398,554.24;但 PredictFolio 同期只有 100,977.66,差了 1,297,576.58。
问题不在数字,而在口径。
activity 更像现金流审计:钱什么时候进,什么时候出。
PnL 更像收益统计:这段时间资产到底涨了多少,跌了多少。
所以我的判断标准变成了:
看时间段收益,用累计 PnL 快照。
查资金流向,用 activity。
不要把“买入形成仓位”,误看成“当天亏掉本金”。
链上数据最容易骗人的地方,不是它没有数据。
而是它给了你一个看起来很精确、但口径完全不对的数字



我最近看高流量的文章,发现很多套路表面不同,本质都在做同一件事:
压缩读者的决策时间。
--“2026 + 全面指南”,压缩的是学习成本:你不用到处找,看这一篇就够。
--“拆解 / 复盘 / 从 0 到 1”,压缩的是试错成本:我把过程摊开,你可以少走弯路。
--“我做了 X,所以你可以信我”,压缩的是信任成本:先证明我有现场经验。
--“你以为 X,其实 Y”,压缩的是判断成本:你可能理解错了,点进来看看真相。
--“闷声发大财”,压缩的是入场犹豫:这事赚钱,而且知道的人还不多。
这些模板确实有效,有效到知道套路的我,经常忍不住会点进去。
但模板越有效,越容易同质化。
最后真正拉开差距的,不是句式。
是真实经历、具体数字和别人复制不了的细节。







在龙虾爆火后,我越来越相信在不久的将来,各类AI Agent会替代它的主人,活跃在网络上进行交流、交易信息、购物等等行为。
而其中最最基础的一个,那就是支付。而AI Agent世界的支付,需要满足
1)足够快,能支持高频的交易转账
2)极低的手续费的支持微小金额转账(甚至是0.0001刀以下)
3)无国界
很明显,能满足上面条件的只有区块链。在Agent时代,区块链和AI真的是绝配。
看到肖老板刚发布的HSK 白皮书2.0,很明显也是主打的这个点。为Agent提供一个完善的支付网络,是web3最有前景的方向。
除了前面说的几个优先,我发现肖老板还考虑的更深,Hashkey Chain 还使用零知识证明,可以让Agent有一个合规数字身份证,它不仅有隐私保护的功能。更重要的,能解决一大部分安全的问题。杜绝了高资产的Agent被坏人跟踪惦记。
Hashkey Chain还设计了机构级许可链,利用其合规的优势,它可以作为结算的主链,而机构可以构建执行层,实现每秒百万笔的吞吐。
Anyway,AI并不是抢了区块链的风头,而是更需要区块链了,这个方向越来越有意思了。



Codex编程能力非常牛,但是它最令人头疼的是:给出的回答里有一堆专业术语,看都看不懂。
之前我的做法是把它拷贝给另外一个ai,让它解释一下。
这两天突然想到,其实可以做一个skill,直接让gpt5.4说人话。
它会直接把刚才回答改写成更简单、适合初学者看的中文说明。
特别是碰到分析出的问题的时候,会根据下面的格式
问题:就像门卫只看了通行证上的名字,却没有检查印章是不是真的。
原因:代码里用了 jwt.decode(),这个方法只会把通行证上的内容读出来,不会检查印章真伪。
后果:任何人只要随便伪造一张通行证,就能冒充别的用户登录。
修复建议:把 jwt.decode() 换成 jwt.verify(),这个方法会同时检查印章,是假的就会直接拒绝。
具体skill已经开源
https://t.co/rzEWskUnPa
现在的ai面对复杂的项目,依然会有bug。而且局部改bug经常会越改越麻烦。
其实,我一直采用一招最最简单的方法:就是重复3遍的方法。
很多人会写subagent、skills,或者superpower、oh-my-claude等复杂项目。但是我感觉下来,依然不如重复3遍简来的简单方便。
做法很简单,当ai完成任务后,你就说,让ai根据要求审核一下代码。根据我的经验:
第一遍,ai会找到好几个问题,你无脑让它修改就好。
第二遍,ai会找到好几个问题,你需要大致看一眼,让它修改严重的。
第三遍,需要特别注意的地方到了。 ai每次都会找一些问题,有些问题压根不重要。所以,这个时候你需要请另外一个ai来审核一下。
比如codex编码的,可以让claude code审核。反之亦然。
基本上第三遍让第二个ai对问题评价出,都是小问题。那你就可以停止了。如果还有一些严重的问题,那还可以继续审查。
我用下来的结果,在过去几个月来,到了项目运行阶段没有碰到过要修复代码的情况了。
在这种最质朴的方法实践多次,我也明白了
1)即使是最好的编程ai,比如codex或者搭配opus的claude code,写复杂项目的时候依然会出现bug
2)即使是最好的编程ai,也会没事找事的找到新的bug。
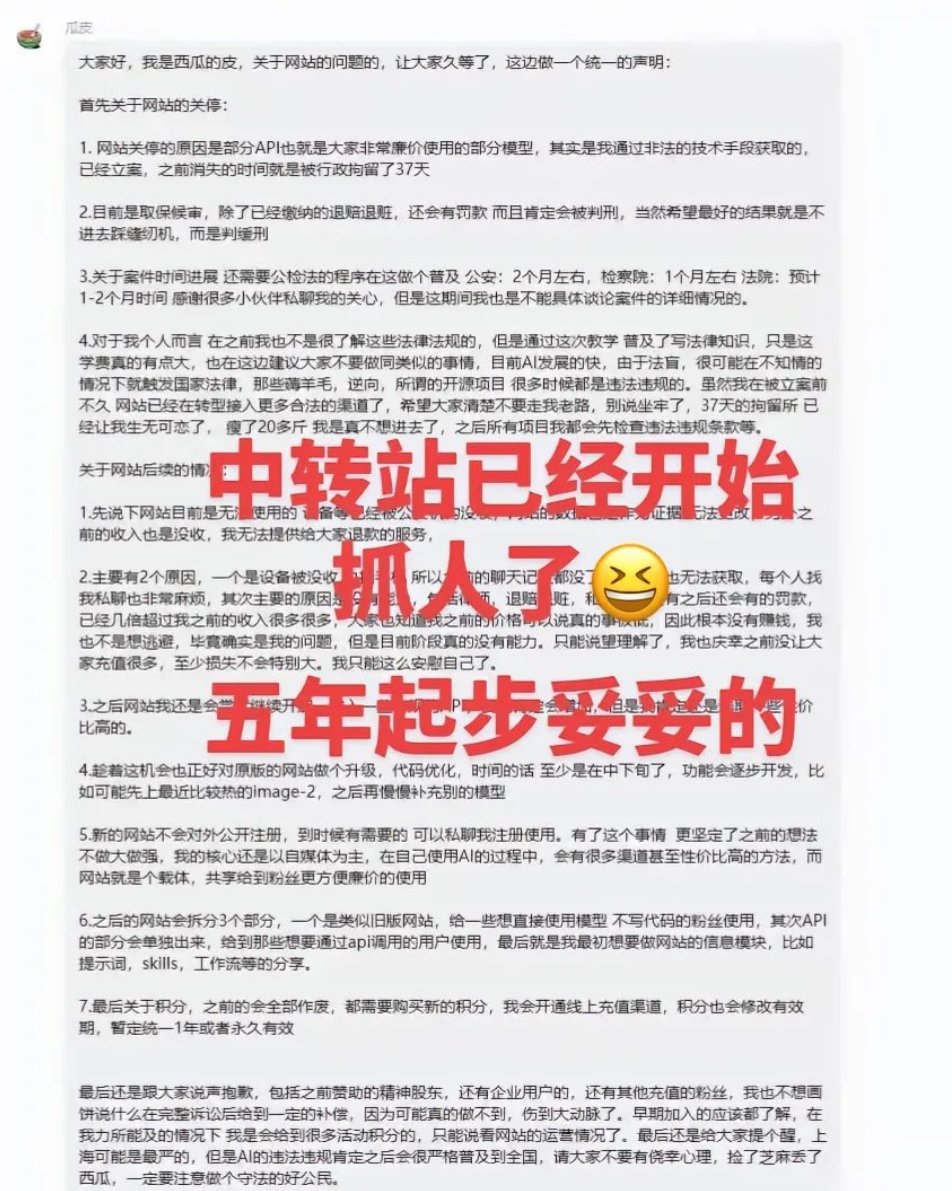
便宜的中转站,往往才是最贵的坑——我踩过之后,总结了3个辨别真假的工具
因为封号的原因,中转站已经成为唯一的选择的。但是,现在市面的中转站鱼龙混杂,良莠不齐。
今天,我分享几个评价中转站的评测
1 helpaio
这是一家专门评价中转站的网站,作者已经评价好了并打分,推荐了一些比较好。并且中转站的基本情况、价格。以及一些真实用户的。我还发现,他们的排名会经常变化。
https://t.co/KTAIfH3Lqg
2 hvoy
这个网站提供评测工具,用户可以自己评估是否是真实的模型,有没有参数。只输入需要评价的中转站url和你自己的api(注意,建一个临时的api,用完删掉)。
同时,它还有中转站的收录和价格,实际感觉价格不太准。
https://t.co/kPjuBgeszE
3 API Relay Audit
https://t.co/0Ui1Bhx6Wf
这是一个github的项目,专门用于全面审计第三方 AI API 中转站(反代/转发站)的安全性、可靠性和透明度。通过11 步审计,全方面的评估中转站的各方面的指标。可以用于深入专业的评估。
再推荐3个我常用的中转站吧
1 packyapi
它的体量应该在中转站属于头部吧,赞助了很多相关的开源项目。自己使用下来,感觉比较稳定。基本上在封号的时候,其他中转站挂了,它还能支撑。但是缺点的话,价格也属于比较贵的一批。claude code已经多次涨价。
所以,我会当做一个托底的中转站,别家用不了了,我就用它。
https://t.co/lkEPi1u6sN
2 米醋
这是我用的比较多的中转站。我用前面的的工具都评测过,都是真实的模型。大部分时候比较稳定,日常用它,偶尔不能用的时候转到packyapi。
最大的优势价格只有前面packyapi的一半,也是见过最便宜的中转站了。(有些更加便宜的,但是使用了一下是掺假的。)
https://t.co/6cRqn4P47i
3 ikun
这家用过一段时间,质量还行,稳定性也还行。但是后来claude code 涨价了,涨的好贵。但是codex依然便宜。
https://t.co/XJYJtMjh6l
其实中转站时候也不稳定,碰到大封号的时候,就会挂掉。之前还用过2个还不错的,因为封号都不干了。
还挺郁闷的,每过一段时间,政策变了,情况变了,就要重新搞一下ai工具。

将有用的内容保持到自己电脑,并形成知识库。这个逻辑走的第一步,我就遇到一个难题
微信、小红书、youtube等各平台不同平台内容,它都一一需要适配。
我突然灵机一动,想到了notebooklm,它是非常好的学习工具。但是换个角度,思路打开,它不就能处理各种类型内容吗?
于是我在github上面找到了notebooklm-py,已经1万多的star。它能解决内容处理的大部分格式了,并能够输出整理总结,连token的费用都省力了
1 天生就是 AI Agent 的技能
notebooklm-py 和普通 API 封装最大的区别——它从设计之初就是给 AI 编程代理用的。一条 `npx skills add` 命令装进 Claude Code 或 Codex,你的代理就能自主创建笔记本、导入资料、提问、生成内容——播客、视频、幻灯片、报告——
URL、PDF、YouTube、Google Drive、纯文本、音频、图片。浏览器里能喂的,这个库都能喂。
全程不用你打开浏览器。我上周把它配成 Claude Code 技能。现在我的代理自己跑完整条链路:导入我指定的 URL,生成音频概览,导出 JSON 格式的测验题,全部丢进文件夹。零手动步骤。整个循环自己转。
让强大产品变得可编程的开源工具,值得更多人知道。notebooklm-py 对 NotebookLM 做的就是这件事。
👉 https://t.co/E2Yl1pi0qC

发现一个好东西,它一句话就能把文章发到 8 个社交平台——而且网页改版了也不会挂。
我的文章一直只发推特,倒不是对x情有独钟,而是我很懒。同一篇内容,你要打开小红书粘贴一遍、打开知乎改一遍格式、打开微信公众号再排一遍版、打开 X 发一条摘要。五个浏览器标签页来回切,三十分钟就这么没了。我之前就是这么干的,每次发完内容都有种"我刚才干了什么"的虚无感。明明可以用来写下一篇文章的时间,全花在了复制粘贴上。
social-push 彻底解决了这个问题。它不是传统的脚本自动化,而是用 agent-browser——一个真正能"看懂"网页的 AI。
一句话发布 8 大平台
这是让我真正上头的功能。你在 AI 编程助手里输入一句 `/social-push 把这篇文章发到小红书`,AI 就会自动打开浏览器、进入编辑器、填标题、粘正文、加话题标签,最后存为草稿。目前支持 8 个平台:小红书图文、小红书长文、X/Twitter、知乎、微博、微信公众号、掘金、https://t.co/TAkVW56Ca2。我上周把一篇技术文章发了五个平台,前后不到四分钟。以前同样的操作要半个小时。
其他几个值得一提的点:
自进化——平台改版后,AI 自动检测页面变化、修复自己的 workflow 文件。你完全不用碰代码,它自己给自己打补丁。
Markdown 即配置——添加新平台只需要写一个 Markdown 文件描述操作步骤。没有脚本,没有选择器,没有代码。我参照现有模板,15 分钟就加了一个新平台。
安全设计——所有操作只到"暂存草稿",绝不会自动点"发布"按钮。发不发,你说了算。
如果你现在还在五个标签页之间来回粘贴同一篇文章,你正在浪费掉本该用来创作的时间。social-push 把这件苦差事变成了一句话的事。
https://t.co/fHpx26FoXG
发内容到中文社交平台的朋友,建议收藏。关注我,持续分享 AI 自动化好工具。
不要再使用polymarket的官方数据了!
做的实在是太差了!我已经不知道踩了多少坑!
正常逻辑,官网或者官方api获得数据是最可靠的
唯独我们的polymarket,非常之不靠谱
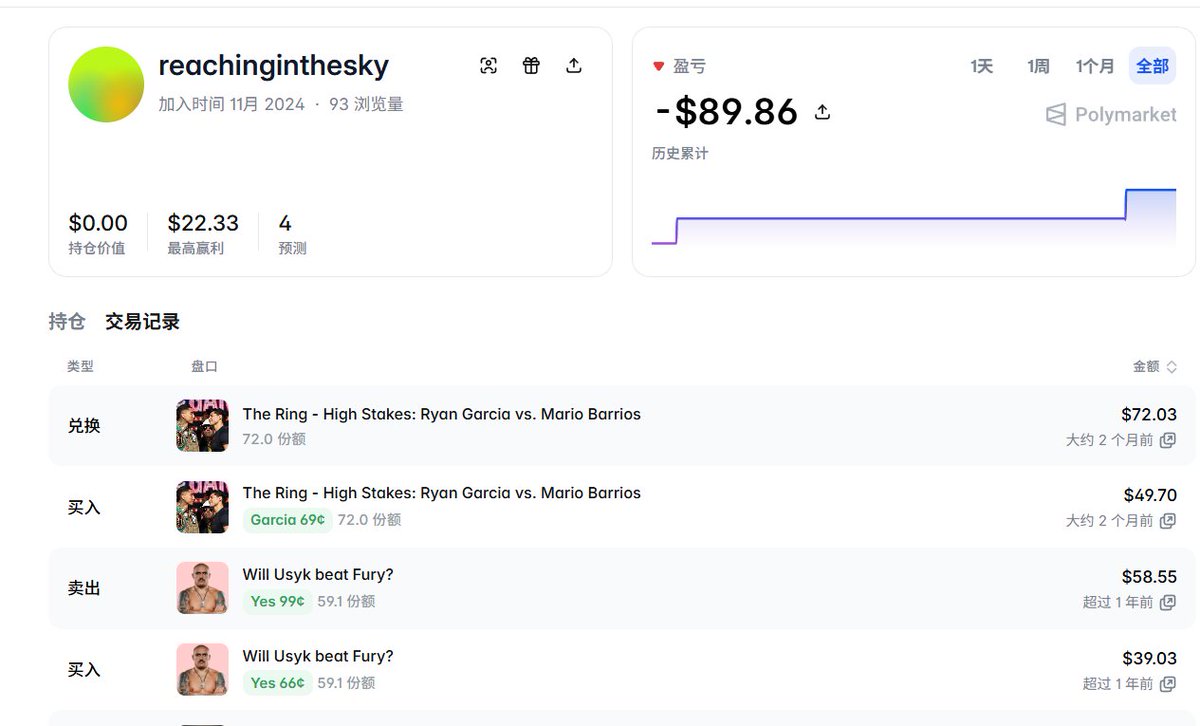
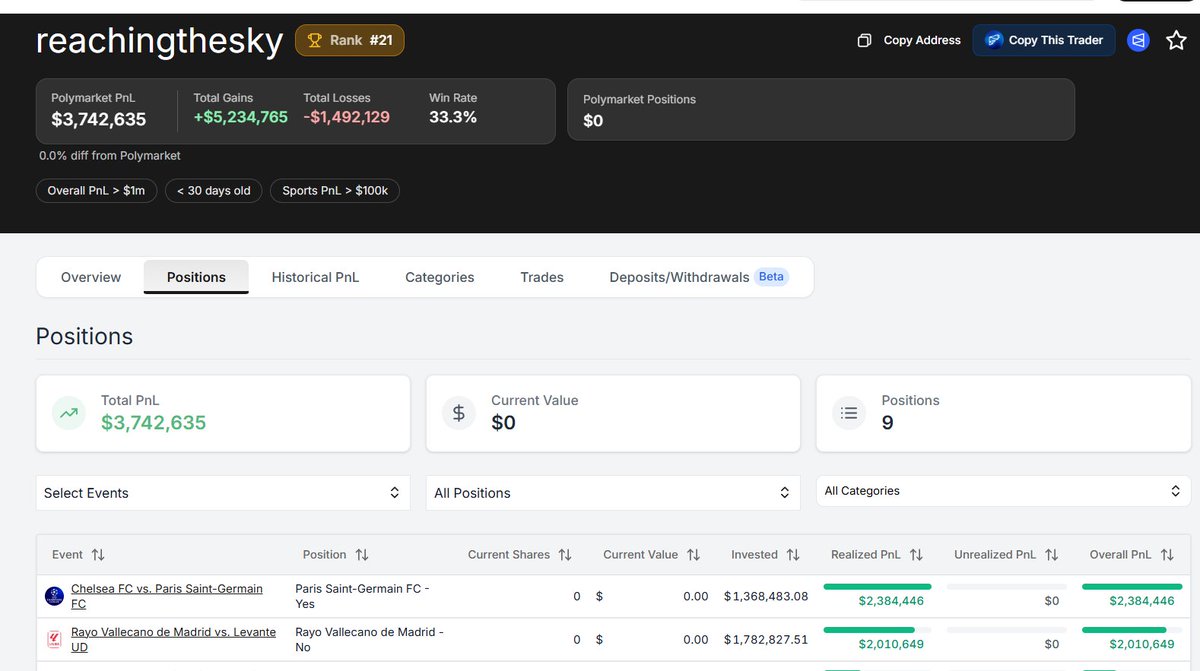
比如说这个地址reachingthesky,官网现实就是个菜逼。总共亏了90刀!实际上polygen链上的数据显示是超级大聪明!交易了8个市场,利润高达370万刀!!
如果你觉得拔链上不方便,可以考虑下面几个网站,我验证下数据比较准确的吧。
https://t.co/lHKyEKm2fN
这是一个专门针对去中心化预测平台 Polymarket 的数据分析平台。其核心功能是追踪链上地址的真实盈亏(PNL)、监控“聪明钱”动向,并解析复杂的链上交互操作。它的最大优点在于能够有效过滤套利机器人的干扰,提供比官方更精准的收益率维度,非常适合需要深度跟单和趋势研判的交易者。
Predictfolio https://t.co/s8Yywl4AGp
核心功能是帮助用户一站式汇总和管理在各个预测事件中的仓位、历史记录及预期收益。
Hashdive
https://t.co/SgJf4sNsKQ。它的核心功能侧重于追踪特定哈希值的交易流向、智能合约交互细节以及资金的底层异动。