


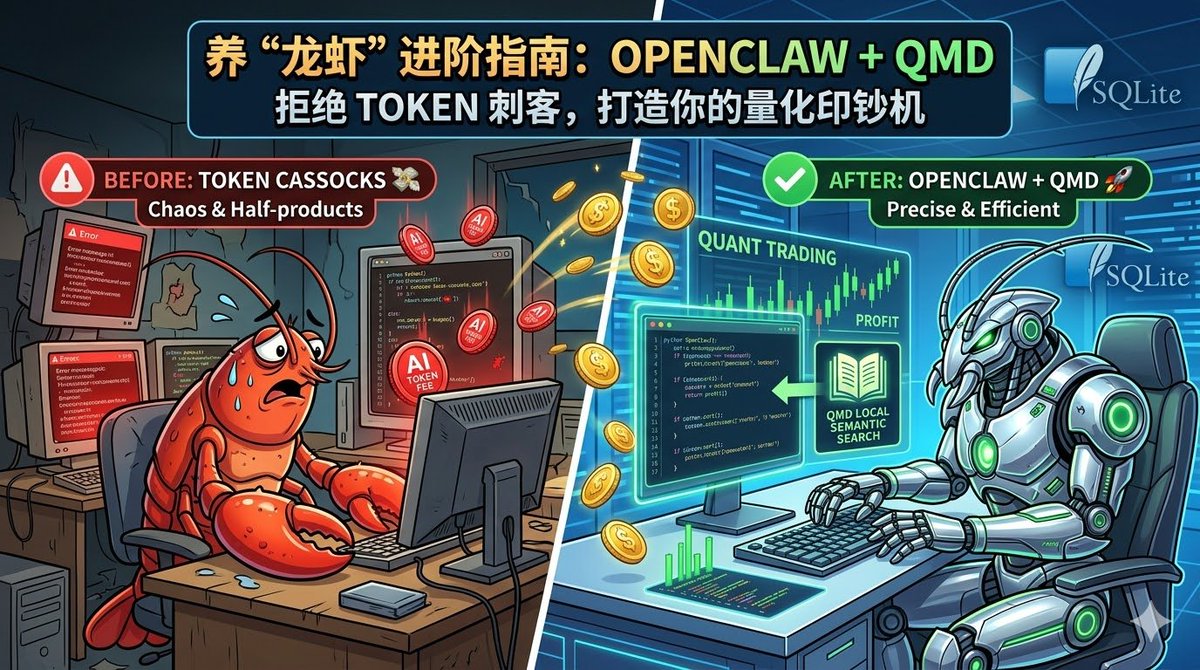
你真的会用龙虾吗?解决TOKEN大量浪费,如何让 OpenClaw 真正为你写出量化印钞机?
安装好龙虾,大部分人脑海中的画面一定是这样的:
你:“帮我去赚钱。”
龙虾:“收到,老板,自动化程序已部署,1000U 已到账。” 💸
现实中的龙虾:
你:“帮我写个赚钱的量化程序。
龙虾:“收到。” 你的 API Token 余额:-1, -2, -3...
一顿操作猛如虎,最后交接给你的,是一堆充满 Bug、连基础回测都跑不通的 Python 半成品。
这就是我们的常态,龙虾并非没用,而是你没给它配上“导航”。 今天这篇实操,教你如何拒绝瞎折腾,真正发挥 AI 的生产力。
一. 破局核心:
给 AI 的记忆做“减法” 为什么 AI 会写出残次品?
因为你丢给它任务太笼统,以及你们历史上下文记录太长,它会出现“幻觉”,开始胡编乱造。
你需要安装 QMD——这是一个专为 OpenClaw 设计的本地语义搜索引擎。
它的核心作用是为 AI 的记忆系统做“提纯”。
QMD 就像给 AI 配了一个精准的图书管理员:它不再每次都把整个图书馆搬出来塞给大模型,而是先快速、智能地在本地检索出最相关的 2-3 句话,再将这部分精华内容传递给 AI。
结果就是:
不仅让 AI 找得准、找得快,还能大幅节省你燃烧的 Token 费用。
开源地址:
https://t.co/ZqBlPnCkQ2
以下是实操保姆级教程:
🛠️ 第一阶段:环境部署 第一步:
安装 SQLite(需带向量扩展支持)
根据你的操作系统执行对应命令:
macOS: brew install sqlite
Debian/Ubuntu: sudo apt update && sudo apt install sqlite3 libsqlite3-dev build-essential
Windows: 需要手动下载并配置 PATH 环境
验证安装: sqlite3 --version
第二步:全局安装 QMD 推荐使用 Bun 安装,速度最快:
使用 Bun 安装(推荐)
bun install -g github:tobi/qmd 或使用 npm 安装 npm install -g@tobilu/qmd
验证安装:
输入 qmd --version,显示版本号即说明安装成功。🚀(注意:如果通过 Bun 安装后找不到 qmd 命令,需要将 Bun 的 bin 目录添加到 PATH:export PATH="$HOME/.bun/bin:$PATH")
第三步:配置 OpenClaw
启用 QMD 找到你的 OpenClaw 配置文件: macOS/Linux: ~/.openclaw/openclaw.json
Windows: C:\Users\你的用户名\.openclaw\openclaw.json 编辑该文件,添加或修改 memory 部分:
{
"memory": {
"backend": "qmd",
"citations": "auto",
"qmd": {
"includeDefaultMemory": true,
"limits": {
"timeoutMs": 8000
},
"update": {
"interval": "5m",
"onBoot": true
}
}
}
}
配置说明:
backend: "qmd":关键配置,启用 QMD 后端。
citations: "auto":让 AI 在回答时附上信息来源。
timeoutMs: 8000:超时时间,默认 4 秒可能不够,建议设为 8000。
第四步:重启服务并建立初始索引
重启 OpenClaw 服务:openclaw gateway restart
查看日志确认:openclaw logs --follow (看到 Using QMD memory backend 提示即代表成功。首次启动会下载约 2GB 模型,请耐心等待)。
建立本地索引:进入你的工作区目录,执行 qmd update --dir .
测试搜索:qmd search "测试查询" --hybrid
(💡 偷懒小技巧:你可以直接把上述配置代码和步骤复制发给 AI,让它帮你排错或执行。)
第二阶段:
如何指挥龙虾写交易量化程序?(核心工作流)
工具装好了,接下来是重头戏。假设你想开发一个针对 Perp DEX 的自动化交易/刷量脚本,请严格按照以下 SOP 安排龙虾工作:
1️⃣ 本地固化(喂养) 去官网或 GitHub 找到该平台的 API 官方文档(比如智能合约交互说明、WebSocket 接口),下载或 Clone 到你的 QMD 索引文件夹内,并执行 qmd update 固化。这样 AI 就有了最准确的本地知识库。
2️⃣提纯报告(消化) 要求 AI:“必须通过 QMD 检索工具,深度阅读本地官方文档,提炼出鉴权、获取实时订单薄和下单的核心逻辑,并生成重点报告。报告必须保存在 QMD 索引文件中。”
3️⃣制定框架(骨架) 根据提炼出的核心内容,让 AI 制定出 Python 程序开发的详细框架和开发步骤。同样,把这份框架记录保存到固化位置。
4️⃣最后,根据敲定的框架和步骤,一步一步地让 AI 编写代码并进行回测调试。不要一次性让它写几百行,要拆解成模块进行。
总结: 用官方文档喂出来的代码,才是真代码。 解决 AI 胡乱思考和瞎测试的根本,在于用 QMD 给它锚定最准确的信息源。有了官方文档的加持,龙虾才能写出更贴合你需求的量化程序,而不是盲目地消耗大量的 Token 去网上搜一堆过时的教程进行试错。

From X
Disclaimer: The above content reflects only the author's opinion and does not represent any stance of CoinNX, nor does it constitute any investment advice related to CoinNX.