


其实大模型收“翻译税”的问题,主要还是在于:
-训练集对非英文语言的采集比例;
-分词器对非英文语言的优化程度。
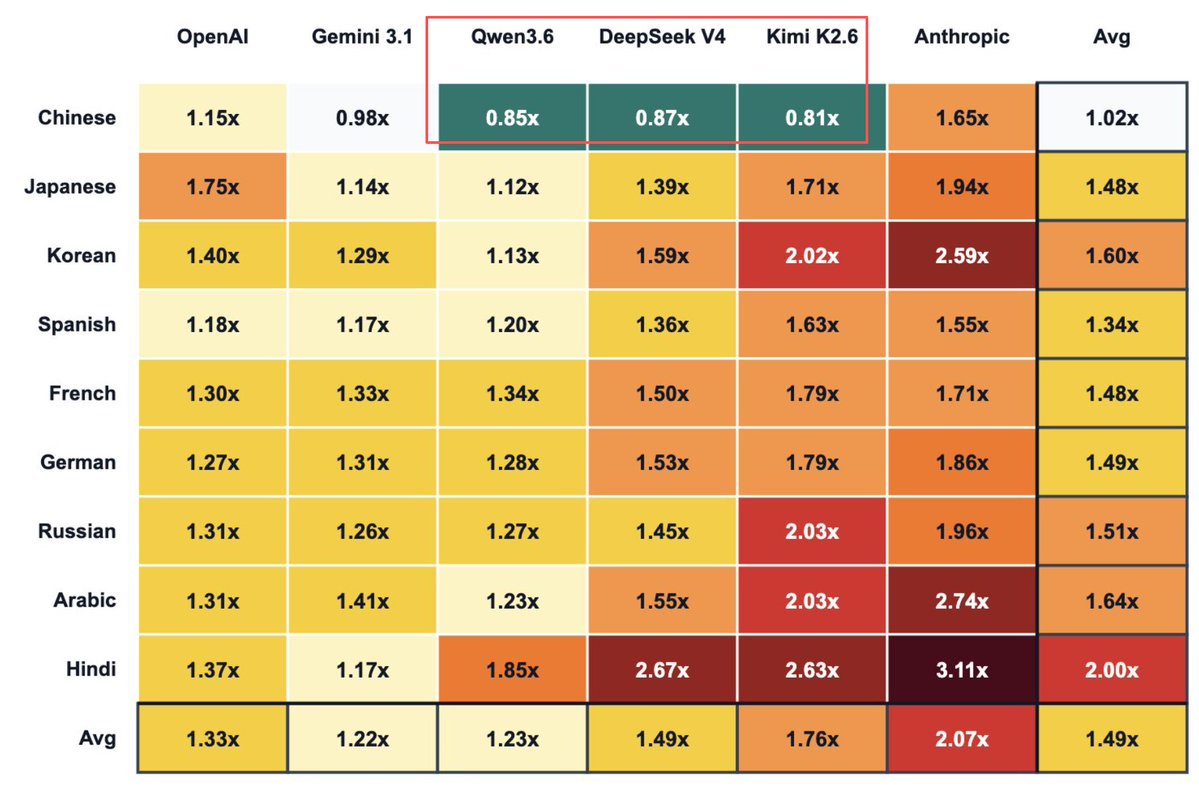
比方说,同样一段话,A 社 Claude 英文消耗的 token 是 1,中文的话就是 1.7。
说白了,就是他们的分词器优先能把英文识别成高频单词,而中文只能拆得更细、更碎一点(浪费 Token)。
比方说“推特”这个词,低效的分词器就会把它拆成“推”加“特”;
但如果你是针对中文优化过的分词器,它就会直接把“推特”作为一个词整体。
所以说,反过来,如果你用 DeepSeek 或者是 Kimi,他们对于中文语料的采集更多,所以分词器能更高效地把中文拆成单个 token,这样他们就更省钱。
因此,这些国产大模型在处理中文时,消耗的 token 甚至比英文还要更少,还能反向收“翻译补贴”。


From X
Disclaimer: The above content reflects only the author's opinion and does not represent any stance of CoinNX, nor does it constitute any investment advice related to CoinNX.