


有时候会想有一些 N 人命题——比如说人类有一天会不会停止创作?
这并非危言耸听,尽管创作是人类的一项基本欲望。
但是如果你把各种 AI 比喻成各种刮刀,你只要发布了一些新想法,你的想法立刻就会被 AI 的刮刀刮走,变成它训练数据的一部分,这听起来是不是有点负反馈😂?
有时候情愿听到一句楼主好人一生平安,也好过一些 AI 留下一些意义不明的吹捧评论,更好过几天后它出现在 AI 的免费互联网训练集里。
以前大家常骂微信的公众号搞信息孤岛太可恶了,里面的内容在百度谷歌完全搜不到,严重违背了互联网精神,弄一个 robots 协议屏蔽了所有搜索引擎的爬虫。
但是直到腾讯元宝降世,明明和 DeepSeek R1 是同样的模型,它却可以旁征博引大量微信公众号的内容,内容质量甚至超过 DS 本身。大家才恍然大悟,开始佩服张小龙的远见。
虽然这不影响基层公众号作者依然不赚钱的事实,但是至少这钱被腾讯截住了,而不是 AI 公司。
所以,OpenLedger 这个 Attribution(内容归属)系统一出,尽管还不清楚它为此额外付出的成本有多少,但是还是让人看到了希望——AI 是有能力指出,你这个训练数据是来自于哪里的。
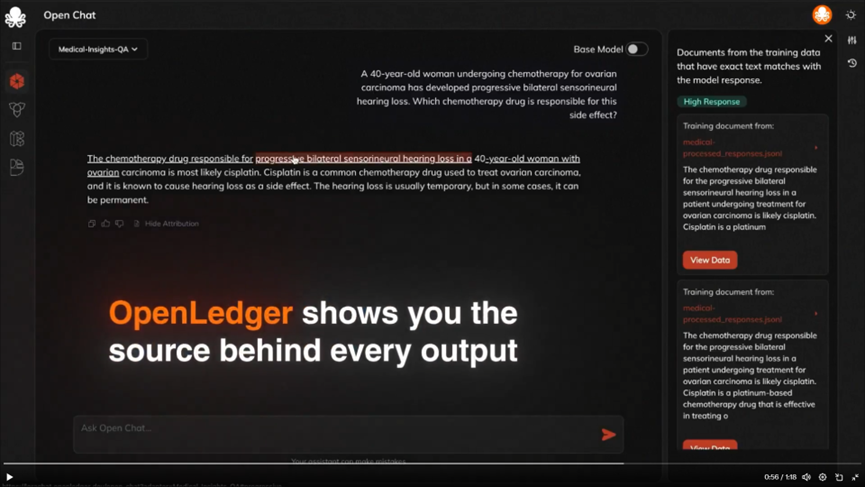
比如视频里这个问题:“一名 40 岁的女性因卵巢癌正在接受化疗,现出现进行性双侧感音神经性听力损失。导致这一副作用的化疗药物是哪一种?”
普通 AI 给出答案是Cisplatin 这种药物;而 OpenLedger 的AI 模型同样给出 Cisplatin 答案,但是它明确指出了这个答案来自于 medical-processed-responses 数据训练集。
这个属于基建。你要先有基建系统,能判断 AI 和数据集之间的归属关系,后面你才能让作者有机会拿到来自 AI 的补贴,这有助于增加互联网分享这个精神。
基于 OpenLedger 的 Attribution 系统,理论上应该是这样的:AI 用户付费→AI 公司盈利→AI 公司付费给数据提供商→数据提供商获利→数据提供商付费给创作者→创作者获利→创作者更多地创作和分享→…
这样,一个正反馈的正循环系统就成立了。
新时代的人们,尤其是 15 后、20 后一代,从小就接触 AI,习惯和 AI 交互,属于 AI 时代原住民。而人们需要做的不仅仅是培养他们使用 AI,更需要让他们在新的时代仍有创作欲望。

From X
Disclaimer: The above content reflects only the author's opinion and does not represent any stance of CoinNX, nor does it constitute any investment advice related to CoinNX.