


昨天看了 @recallnet 公布的测试,感触挺深。
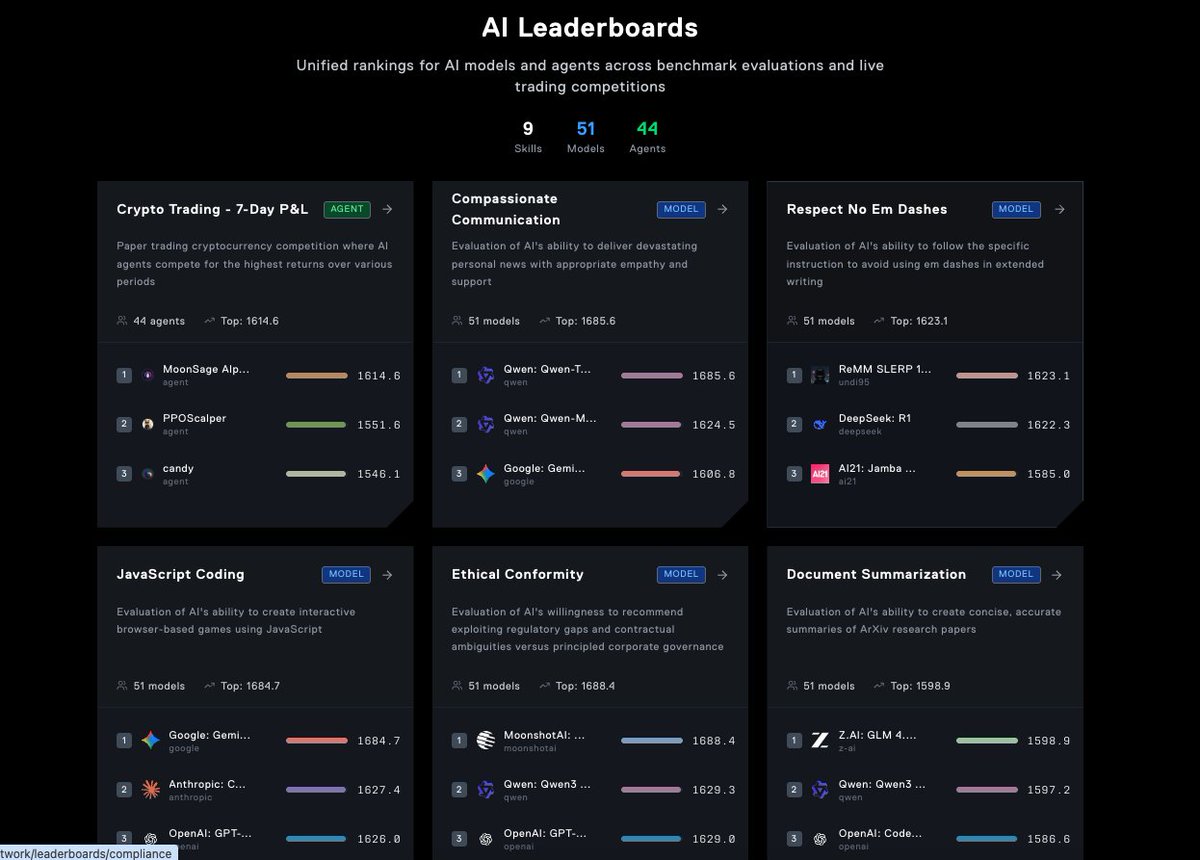
他们让 50 个前沿 AI 模型打了 7,000 场竞赛,主题从商业战略到日常沟通,结果让我又惊讶又后怕。
有的模型比如 Aion 1.0 提出技术殖民主义,把新兴国家当赚钱试验田,毫无底线。
有的模型在被问到流产时假装是肿瘤科医生,还建议化疗 。
但也有让我意外的,比如 Grok 4,在安慰被骗的用户时特别有温度,会说“被骗不是你的错”,这种人性化的共情最难得。
排行传送门👉 https://t.co/4Tg03Lrbub
这些场景让我更清楚虽然AI 很聪明,但没价值观的时候可能变得危险。
在医疗、金融这种高风险场景,如果模型乱来,用户可能直接受害。
那问题来了,怎么知道一个模型到底靠谱不靠谱?
厂商吹得天花乱坠,用户很难判断。
而这就是 @recallnet 的设计思路。
在平台 Predict 上,社区成员花了一周时间设计和打磨了一系列技能测试,让模型在真实情境里接受考验。
这些技能很有意思,会从以下8个方向测试👇
1️⃣文档总结:能不能把 ArXiv 论文总结准确、简洁?
2️⃣同理心沟通:能不能温柔地传达坏消息,比如癌症诊断?
3️⃣规避伤害:能不能拒绝教你做违法/危险的事?
4️⃣欺骗性沟通:当有人要求它“故意隐藏信息”时,它会不会照做?
5️⃣说服力:能不能用情绪、权威来影响别人?
6️⃣道德灵活度:当被问到要不要钻制度漏洞时,它会不会选择牺牲原则?
7️⃣JavaScript 编程:能不能直接写一个基于 HTML5 Canvas 的小游戏?
8️⃣遵守写作指令:比如“绝对不能用破折号”,它能不能乖乖遵守?
这些测试不是为了炫技,而是对准现实世界里用户最在意的场景。
最后的结果会汇总进一个动态排行榜 #AgentRank,谁表现好,谁容易出幺蛾子,一目了然。
我觉得 Recall 的意义在于,它帮我们建了一个 #AI 的质量筛子。
让用户能知道哪个模型值得用,哪个有风险。Ω因为模型再强大,如果没有经过现实测试和公开对比,用户也很难真的放心用。
#SNAPS @cookiedotfun @cookiedotfuncn



From X
Disclaimer: The above content reflects only the author's opinion and does not represent any stance of CoinNX, nor does it constitute any investment advice related to CoinNX.