


强推大宇这篇高通研报!
大宇上上篇《英伟达份额大降,AI革命新阶段机会在哪》结尾说到端侧AI的时候,我就想到了高通,没想到大宇这么快就把高通的研报写出来了,当真是高产似那啥……
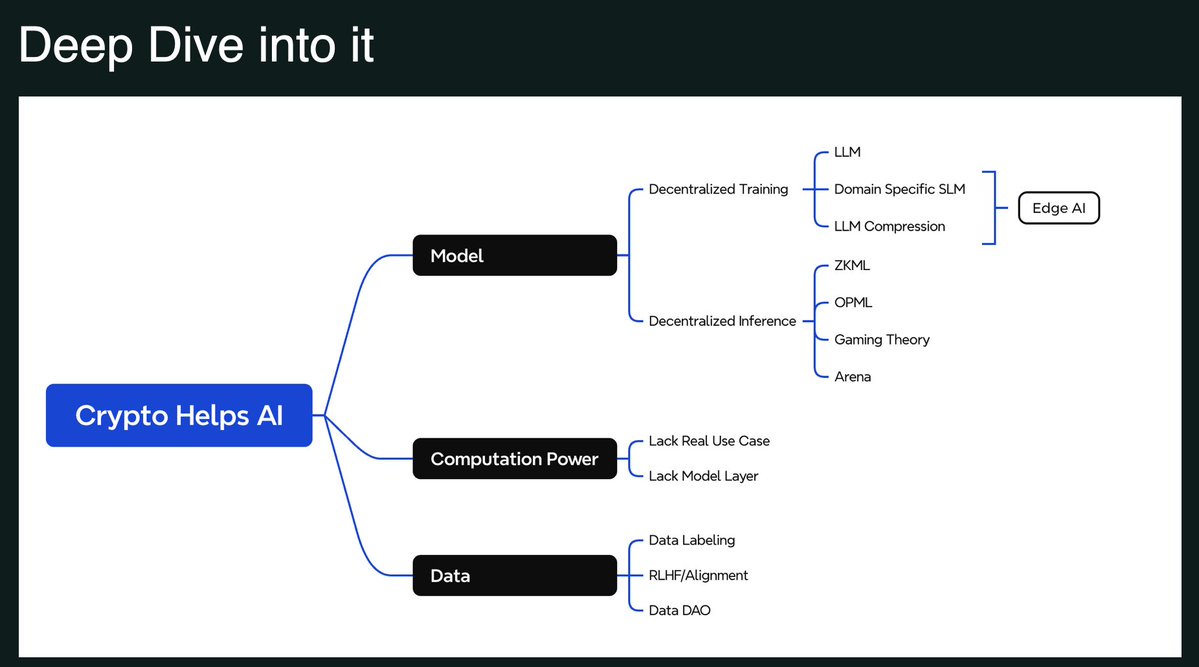
24年在Amber内部一次的Cypto+AI的分享会上也分享过端侧AI,不过当时更多是从去中心化,或者说分布式训练小模型的应用场景来切入的,当时的PPT我还留着,给大家截个图看下
顺着大宇的思路再补充两个小点
一是投资标的的选择
除了高通之外,另外两个标的也值得一说
1. 苹果 - 这个不难理解,如果Edge AI爆发,入口端最明显的标的一定是Apple,20多亿台设备+IOS就是全球最大的推理网络,届时也许会重新估值
2. MediaTek - 联发科,大宇研报中提到过。这个算高通的直接竞对,有那么点当年Intel/AMD的Feel,不过有个区别得说一下。 Intel和AMD当初在X86阵营里面竞争,算是个相对封闭的市场,毕竟完整授权的只有他俩,外人进不来。但是高通和联发科的ARM授权,竞争对手很多,苹果,三星,华为,等等都是竞争对手,只是当前老大老二是高通和联发科,也有一定护城河,但未来端则AI时代,会发生什么不一定。
二是端侧AI发生的时间点
过去几年因为一直关注去中心化训练这个赛道,所以对垂类模型包括小模型也一直有关注
现在1-7B的小模型已经可以在手机和笔记本上用了,属于“能用,但还不够好用”的阶段,基本上简单问答、文本摘要、语音识别、图像描述、实时翻译这些是OK的,但你一旦需要长上下文,复杂推理、多步骤任务规划之类的,你还是得指望云
未来2-3年,端侧AI主要依赖下面三个因素的进步
1. 硬件上不断提升 - 就是NPU的TOPS在不断提升,手机和笔记本的内存也逐步变大,这是高通和联发科的领域
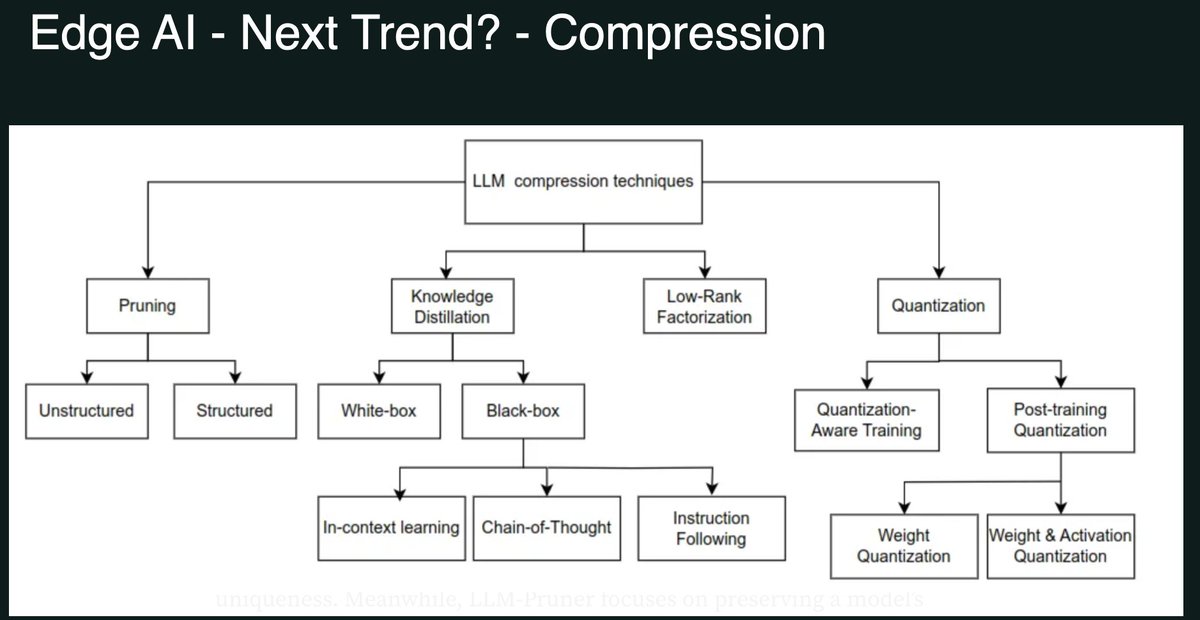
2.压缩持续进步 - 就是我PPT里面那张图,量化、蒸馏、剪枝这些技术。现在DeepSeek R1蒸馏版1.5B的推理能力放到两年前需要 20B+
3. 架构优化 - 比如MOE(混合专家)稀疏化。DeepSeek V4 671B的总参数,每次推理只激活 37B——相当于用了671B的"知识库",但每次只调动其中5%干活。
以及KV cache/attention优化 - 也是DeepSeek V4弄出来的,本质就是推理过程中“需要记住的东西更少”,解决长上下文推理的内存瓶颈,毕竟手机和笔记本上可没法上服务器那种海量的HBM
所以这个时间点大概率会是2-3年左右的时间,从能用到好用。当前业界的大致共识是 - 7B级别的模型在手机上流畅运行,是端侧 AI 真正实用化的门槛,估计两年之后7B能有现在上百B模型的能力,就能处理80%+的日常任务了

From X
Disclaimer: The above content reflects only the author's opinion and does not represent any stance of CoinNX, nor does it constitute any investment advice related to CoinNX.