


🛠️ Prompt tiếng Anh tiết kiệm hơn tiếng Việt bao nhiêu %?
- Tiếng Việt: “Viết một đoạn phân tích về cách AI giúp doanh nghiệp tăng năng suất”
- Tiếng Anh: “Write an analysis of how AI improves business productivity”
Cùng một ý, nhưng:
- Bản tiếng Việt thường ~18–22 tokens
- Bản tiếng Anh ~12–15 tokens
=> Tiết kiệm khoảng 25–30%
Lý do là
- Thứ nhất, tiếng Việt là đơn âm tiết. “năng suất” = 2 phần, “doanh nghiệp” = 2–3 phần. Tokenizer thường phải tách nhỏ từng mảnh → số token tăng lên.
Trong khi tiếng Anh “productivity”, “enterprise” thường được nén thành ít token hơn vì là từ ghép.
- Thứ hai, tiếng Việt có dấu. Những ký tự như “ă, â, ư…” khiến tokenizer khó match pattern tối ưu, nên phải chia nhỏ hơn để biểu diễn. → cùng một từ, tiếng Việt thường bị split nhiều hơn.
- Thứ ba, bias từ dữ liệu training. Phần lớn model được train mạnh trên tiếng Anh, nên tokenizer được tối ưu để “nén” tiếng Anh hiệu quả nhất. → tiếng Anh = ít token hơn cho cùng lượng thông tin
----
1 phút làm quen 😁
Thứ 7 tuần này @nghienaivn sẽ tổ chức buổi cafe “cai nghiện AI” ☕ để giúp mọi người không bị "lạc lối" với AI nữa.
Anh em có thể đăng ký ở đây https://t.co/rJgh07GozR
Đảm bảo có nhiều insights giá trị 👀
----
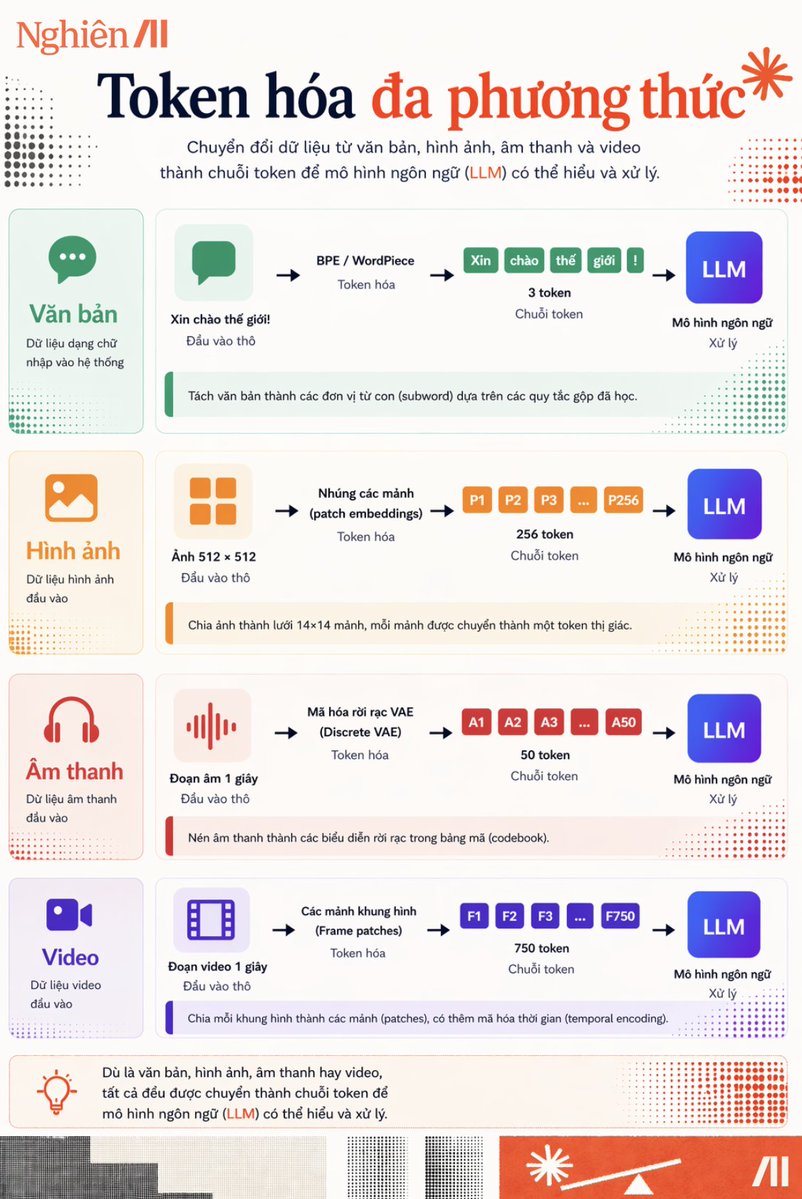
Nhìn cái hình này, nếu chỉ hiểu là “cách AI chia nhỏ dữ liệu thành token” thì hơi nông. Thứ nó đang lộ ra thực ra là một thứ quan trọng hơn nhiều: mọi loại dữ liệu cuối cùng đều bị ép về token, nhưng mỗi loại có một “tỷ giá” khác nhau.
Text là rẻ nhất. Một câu đơn giản chỉ vài token. Nhưng sang image, một tấm 512x512 đã thành 256 token. Audio 1 giây ~50 token. Video 1 giây nhảy lên ~750 token.
Lý do là LLM không “hiểu” ảnh hay video như con người. Nó chỉ hiểu chuỗi token. Với text, bản thân ngôn ngữ đã là một dạng nén thông tin rồi. Nhưng với ảnh, audio, video, model buộc phải băm nhỏ dữ liệu thô thành từng mảnh để xử lý.
Từ góc nhìn này, giới hạn của AI không nằm ở model trước, mà nằm ở token budget. Khi hiểu được phần này, bạn sẽ không chỉ prompt tốt hơn, quản lý context windows tốt hơn mà còn tiết kiệm hơn khi nghĩ đến bài toán business.
#NghiênAI @nghienaivn

From X
Disclaimer: The above content reflects only the author's opinion and does not represent any stance of CoinNX, nor does it constitute any investment advice related to CoinNX.