


[Tới giờ học] Mấy anh Trung Quốc đã clone AI model đạt 80% bản gốc rồi bán giá 1/10 như thế nào? 😁
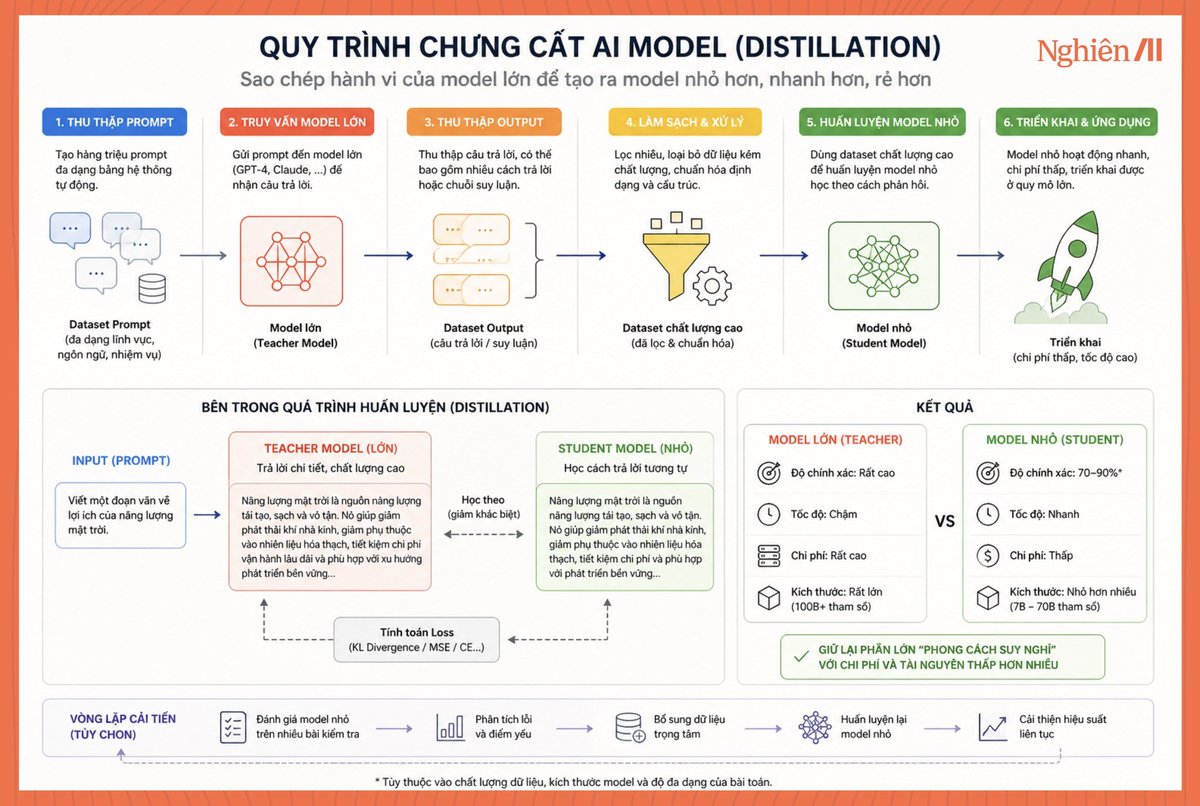
Điểm mấu chốt nằm ở chưng cất: lấy cách trả lời của model lớn làm dữ liệu, rồi dạy lại cho model nhỏ. LLM vốn chỉ là hệ dự đoán token tiếp theo, nên nếu có đủ nhiều cặp hỏi – đáp chất lượng cao, model nhỏ sẽ học được pattern đó.
Trong lúc huấn luyện, họ tối ưu hai thứ cùng lúc:
- Học đúng câu trả lời (cross-entropy)
- Học “độ tự tin” của từng từ mà model lớn đã chọn (KL-divergence trên logits).
Nhờ vậy, model nhỏ không chỉ trả lời đúng ý mà còn giữ được độ mượt và ổn định.
Phần quyết định chất lượng nằm ở pipeline dữ liệu. Các team như Moonshot, https://t.co/uBFZm5Tpwu, DeepSeek không bắn prompt ngẫu nhiên mà thiết kế bộ câu hỏi phủ đúng các tình huống dùng thật: chăm sóc khách hàng, viết nội dung, code, phân tích.
Mỗi câu hỏi được hỏi nhiều lần ở các mức “sáng tạo” khác nhau để lấy nhiều phương án trả lời, sau đó dùng một hệ chấm điểm để chọn câu tốt nhất theo tiêu chí rõ ràng: đủ ý, đúng tone, đúng format.
Ví dụ một câu “Khách yêu cầu hoàn tiền vì sản phẩm lỗi”, họ sẽ giữ câu trả lời có cấu trúc chuẩn: xin lỗi → hướng dẫn xử lý → kết thúc bằng hành động cụ thể.
Khi bước vào huấn luyện, model nhỏ chỉ cần học lại mapping đã được “tinh chế” này. Với các bài toán nhiều bước, họ cho model lớn giải theo nhiều cách, chọn lời giải cho kết quả ổn định nhất rồi đưa vào dữ liệu. Model nhỏ học lại pattern đó nên vẫn giữ được logic cơ bản.
Ví dụ bài toán tính chi phí đơn hàng sau giảm giá và phí ship, model nhỏ sẽ tái tạo đúng thứ tự tính toán đã được chọn từ model lớn.
Đánh giá chất lượng được gắn trực tiếp với bài toán thực tế. Với code thì đo pass@k, tức là chạy có đúng không; với hỏi đáp thì đo exact match hoặc F1; với nội dung thì so trực tiếp câu trả lời giữa model nhỏ và model lớn để tính win-rate.
Ví dụ đưa 100 câu hỏi support, nếu model nhỏ được chọn tốt hơn 60 lần thì win-rate là 60%. Song song đó, họ đo độ ổn định: cùng một câu hỏi, model có trả lời nhất quán hay không, và đo calibration để xem mức độ tự tin có khớp với độ chính xác.
Khi đưa vào sản phẩm, họ không dùng một model duy nhất mà chia việc theo chi phí. Model nhỏ xử lý phần lớn câu hỏi phổ biến vì rẻ và nhanh, còn những câu phức tạp sẽ được chuyển sang model lớn.
Ví dụ một hệ thống chăm sóc khách hàng có thể để 80% câu hỏi như “Đơn hàng ở đâu?”, “Đổi trả thế nào?” cho model nhỏ xử lý, và chỉ đẩy các trường hợp tranh chấp thanh toán lên model lớn. Với cấu trúc này, chi phí trung bình giảm mạnh trong khi trải nghiệm vẫn ổn định.
Một bước tối ưu sâu hơn là nén cả workflow. Một agent nhiều bước trước đây phải đọc dữ liệu, phân tích, viết, kiểm tra rồi chỉnh sửa. Họ log toàn bộ input và output cuối, sau đó train model nhỏ học trực tiếp kết quả.
Ví dụ từ yêu cầu “Viết báo cáo tuần từ dữ liệu này”, model nhỏ trả luôn báo cáo hoàn chỉnh trong một bước, không cần chạy qua nhiều vòng suy luận. Độ trễ giảm và chi phí cũng giảm theo.
Về kinh tế, cách này tạo ra chênh lệch rất lớn. Model lớn đạt chất lượng cao nhưng chi phí cao, còn model chưng cất đạt khoảng 70–90% hiệu năng trong các tình huống lặp lại với chi phí chỉ bằng một phần nhỏ. Đây là lý do vì sao các model Trung Quốc có thể rẻ hơn nhiều nhưng vẫn dùng tốt trong phần lớn use case.
Toàn bộ hệ thống vận hành xoay quanh bốn điểm: dữ liệu được thiết kế đúng phân phối sử dụng, loss tối ưu để giữ hành vi của model lớn, đánh giá sát với bài toán thật, và routing để cân bằng chi phí – chất lượng.
Vừa có kinh nghiệm & vừa có kiến thức. Follow @nghienaivn ở đây nè 👇
https://t.co/wOX7GsW3qv
---


From X
Disclaimer: The above content reflects only the author's opinion and does not represent any stance of CoinNX, nor does it constitute any investment advice related to CoinNX.