


🧠 [Mỗi ngày 1 từ khoá] Kiến trúc Transformer của Google là gì mà gần như toàn bộ AI hiện nay đều chạy trên nó?
Thứ Google tạo ra năm 2017 không chỉ là một AI model mới, mà là một cách hoàn toàn mới để máy hiểu ngôn ngữ.
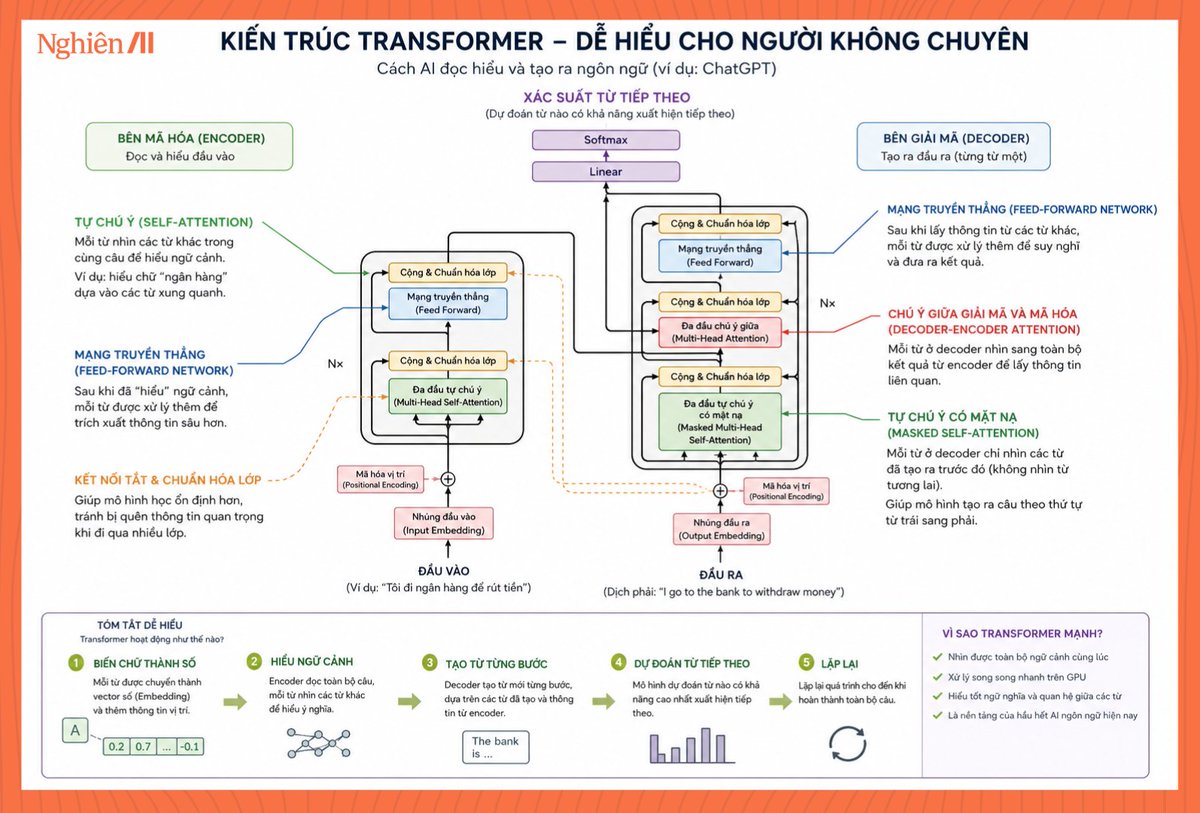
Trước Transformer, AI đọc văn bản theo kiểu tuần tự từng token một nên rất khó nhớ context dài. Đọc càng xa thì càng mất liên kết với phần đầu câu.
Transformer giải quyết chuyện đó bằng cơ chế “Attention”. Thay vì chỉ nhìn vài chữ gần nhất, model có thể nhìn toàn bộ câu cùng lúc để hiểu ngữ cảnh.
Ví dụ câu:
- “Tôi đi ngân hàng để rút tiền” → hiểu “ngân hàng” là bank tài chính.
- “Tôi ngồi bên bờ ngân hàng” → hiểu theo nghĩa địa lý.
Đây là bước nhảy cực lớn vì AI bắt đầu hiểu context thay vì chỉ đoán token tiếp theo. Transformer cũng cực kỳ hợp với GPU vì có thể xử lý song song cả đoạn văn cùng lúc. Trong khi các kiến trúc cũ như RNN hay LSTM phải đọc từng token tuần tự nên train rất chậm.
Đó là lý do sau 2017, toàn ngành AI tăng tốc khủng khiếp:
- Model scale lớn hơn
- Dataset scale lớn hơn
- GPU cluster scale lớn hơn
- Khả năng AI tăng theo cấp số nhân.
Ngay trong tên ChatGPT cũng đã có chữ Transformer: Generative Pretrained Transformer.
Hiện tại gần như mọi công ty AI lớn như OpenAI, Anthropic, Meta hay DeepSeek đều xây trên nền móng này. Họ cạnh tranh ở dữ liệu, cách train, inference hay agent system, nhưng phần lõi xử lý ngôn ngữ vẫn là Transformer.
Đây cũng là lý do các công ty AI Trung Quốc chưng cất model rất nhanh. Vì phần lớn AI text hiện đại đều dùng cùng kiểu kiến trúc, nên việc transfer knowledge giữa các model dễ hơn rất nhiều. Giống như cả ngành đang dùng chung một loại động cơ, còn mỗi công ty tối ưu chiếc xe riêng của mình.
Follow @nghienaivn để bắt kịp AI trong 2 tháng!
https://t.co/wOX7GsW3qv
----


From X
Disclaimer: The above content reflects only the author's opinion and does not represent any stance of CoinNX, nor does it constitute any investment advice related to CoinNX.