


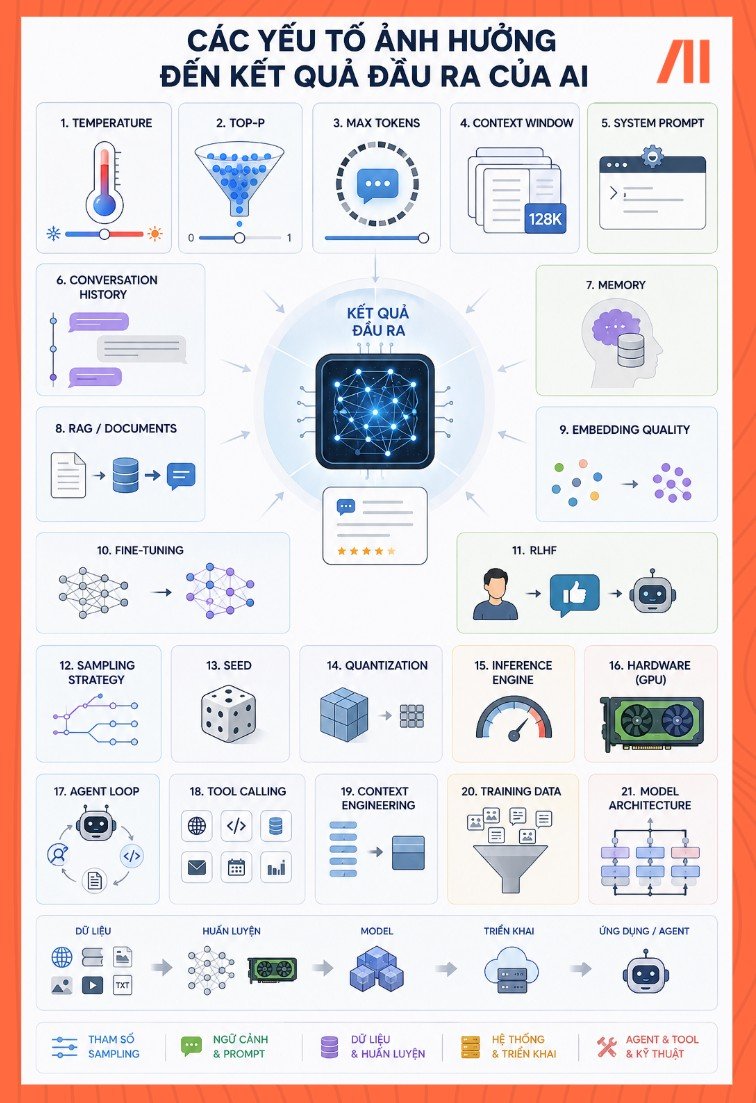
✅ 21 yếu tố quan trọng nhất ảnh hưởng đến câu trả lời của AI
1/ Temperature
Độ “sáng tạo” của AI. Temperature thấp thì AI trả lời ổn định, an toàn và ít random hơn. Hợp cho coding, phân tích dữ liệu hay workflow cần tính chính xác. Temperature cao thì AI sáng tạo hơn, brainstorm đa dạng hơn nhưng dễ hallucination hơn.
Ví dụ:
Temperature = 0 → hỏi nhiều lần gần như ra cùng đáp án
Temperature = 1.2 → mỗi lần có thể trả lời khác hẳn
2/ Top-p
Giới hạn phạm vi token AI được phép chọn tiếp theo. Hiểu đơn giản là AI chỉ được chọn trong nhóm từ có xác suất cao nhất thay vì toàn bộ từ vựng. Top-p thấp giúp output tập trung hơn, top-p cao giúp output đa dạng hơn.
3/Max Tokens
Giới hạn độ dài output. Nếu để quá ngắn, AI sẽ bị cắt giữa chừng. Nếu để quá dài sẽ tăng chi phí và đôi khi khiến AI lan man hơn.
4/ Context Window
Lượng thông tin AI có thể nhìn cùng lúc. Ví dụ: 8k token, 32k token, 128k token, 1M token.
Context window càng lớn thì AI càng đọc được nhiều file, nhiều đoạn chat và nhiều tài liệu hơn trong một lần xử lý. Nhưng cũng không phải càng nhiều là càng tốt, mà đôi khi càng cô đọng thì sẽ ra được kết quả chính xác hơn.
5/ System Prompt
“Luật nền” điều khiển hành vi AI. Đây là thứ quyết định AI đóng vai trò gì, giọng văn ra sao, được phép hay không được phép làm gì. System prompt thường ảnh hưởng cực mạnh tới output.
Ví dụ: “Bạn là chuyên gia tài chính", “Trả lời ngắn gọn”, “Luôn viết bằng tiếng Việt”...
6/ Conversation History
Toàn bộ lịch sử chat trước đó. AI dùng phần này để giữ mạch hội thoại và hiểu ngữ cảnh hiện tại. Đó là lý do chat càng dài thì AI càng “hiểu mình hơn”.
7/ Memory
Bộ nhớ dài hạn lưu sở thích, thói quen hoặc thông tin người dùng. Memory giúp AI cá nhân hóa câu trả lời giữa nhiều cuộc trò chuyện khác nhau.
8/ RAG (Retrieval-Augmented Generation)
Cơ chế nhét thêm tài liệu ngoài vào context trước khi AI trả lời. RAG giúp AI trả lời dựa trên dữ liệu riêng thay vì chỉ dùng kiến thức pretrain.
Ví dụ: PDF nội bộ, Notion, Google Drive, Vector Database
9/ Embedding Quality
Chất lượng embedding quyết định khả năng tìm đúng context trong RAG system. Embedding càng tốt thì AI càng lấy đúng tài liệu liên quan.
10/ Fine-tuning
Huấn luyện thêm model cho domain hoặc phong cách cụ thể. Fine-tune giống như “đào tạo nghề” thêm cho model. Ví dụ: AI chuyên luật, AI chuyên y tế, AI viết theo style riêng
11/ RLHF (Reinforcement Learning from Human Feedback)
Lớp huấn luyện hành vi bằng feedback con người. Đây là thứ giúp AI trả lời tự nhiên, an toàn và “giống trợ lý” hơn.
12/ Sampling Strategy
Cách model chọn token tiếp theo. Temperature và Top-p thực ra nằm trong nhóm sampling này. Sampling khác nhau → output khác nhau dù cùng model.
13/ Seed
Con số cố định randomness. Dùng để tái tạo kết quả giống nhau giữa nhiều lần chạy. Rất quan trọng khi testing hoặc benchmark model.
14/ Quantization
Nén model để chạy nhẹ hơn trên GPU yếu hoặc máy local. Quantization giúp tiết kiệm VRAM nhưng đôi khi làm giảm chất lượng output.
15/ Inference Engine
Hệ thống dùng để serve model. Cùng một model nhưng inference stack khác nhau vẫn có thể cho tốc độ và chất lượng khác nhau. Ví dụ: vLLM, Ollama, TensorRT-LLM, Groq stack,...
16/ GPU / Hardware
Phần cứng ảnh hưởng trực tiếp tới: tốc độ, context length, batch size, khả năng chạy model lớn. Đó là lý do NVIDIA gần như trở thành “xương sống” của ngành AI hiện tại vì GPU hoạt động hiệu quả.
17/ Agent Loop
Cách AI tự suy nghĩ nhiều bước và gọi tool liên tục. Agent loop càng tốt thì AI càng “giống nhân viên” thay vì chatbot.
Ví dụ: AI tự search web, tự đọc file, tự sửa code, tự kiểm tra output
18/ Tool Calling
Khả năng dùng công cụ ngoài như browser, Python, database, email, calendar, API. Tool giúp AI vượt khỏi giới hạn “chỉ chat text”.
19/ Context Engineering
Cách sắp xếp, nén và quản lý context trước khi đưa vào model. Đây đang là một trong những lợi thế cạnh tranh lớn nhất của các AI product hiện nay.
20/ Training Data
Dữ liệu dùng để train model. Dữ liệu càng lớn và chất lượng càng cao thì model càng thông minh. Đây là “nguồn thức ăn” của AI.
21/ Model Architecture
Kiến trúc nền phía dưới model. Hiện tại phần lớn AI text hiện đại đều dùng Transformer hoặc biến thể từ Transformer.
Đó là lý do cùng một nền móng nhưng mỗi công ty vẫn tạo ra chất lượng rất khác nhau bằng cách tối ưu toàn bộ stack phía trên.
AI hiện đại thực ra không còn là “một model”. Nó là cả một hệ thống gồm model + dữ liệu + context + memory + sampling + tools + agent + inference stack + orchestration.
🟠 Follow @nghienaivn để cập nhật kiến thức hữu ích về AI
https://t.co/wOX7GsW3qv
-----


From X
Disclaimer: The above content reflects only the author's opinion and does not represent any stance of CoinNX, nor does it constitute any investment advice related to CoinNX.