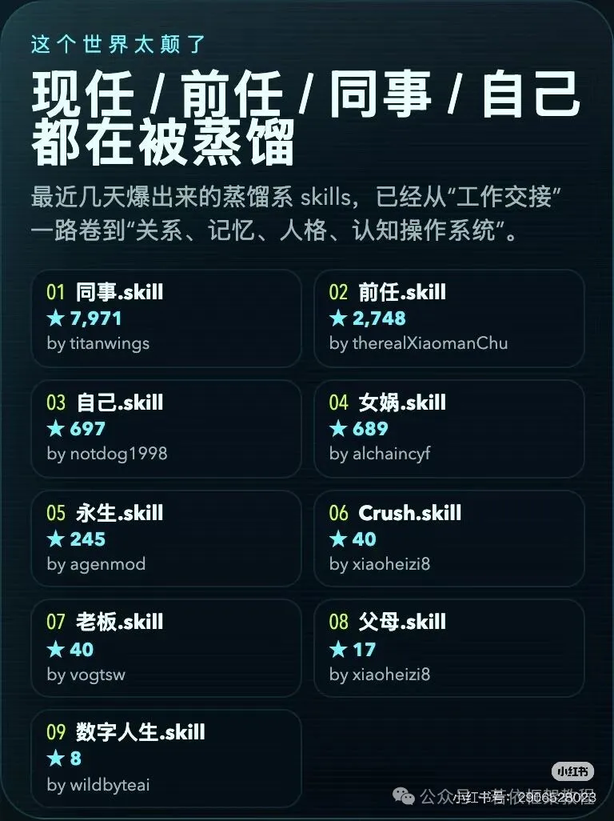
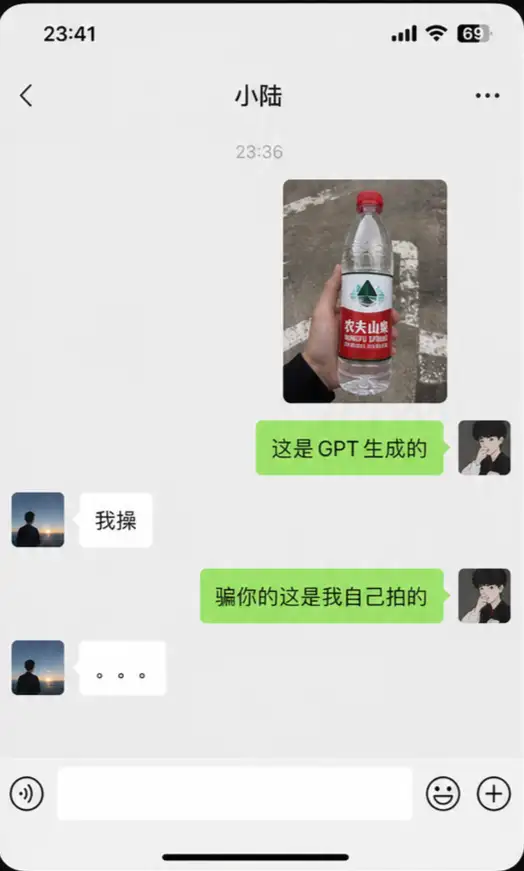
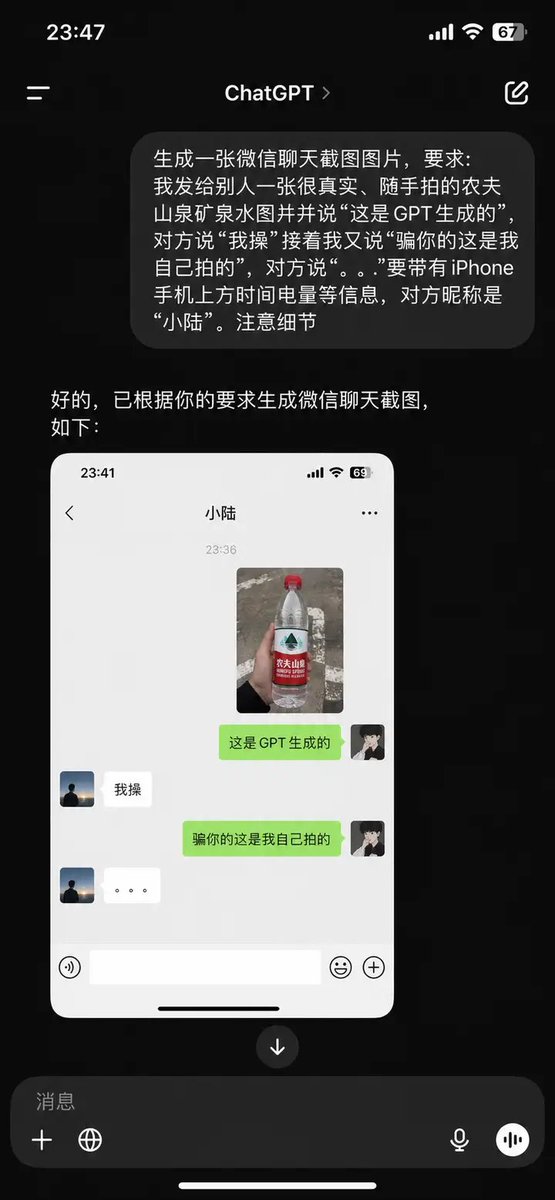
全程没训练任何神经网络!大模型手写控制规则杀入流体力学工业,14美元跑通全套策略
OpenAI 后训练核心成员翁家翌刚证明了「纯靠大模型写代码能通关 Atari 游戏」,研究人员 Paul Garnier 就把这套方法搬进了更硬核的流体力学控制。
他全程没训练任何神经网络。单纯让 Codex 5.5 充当程序员,盯着流体仿真录像反复改写 Python 脚本。就靠这套手写的控制规则,AI 在十多项物理测试中,硬是在超半数的场景里把顶级的强化学习(DRL)基线挑落马下。
给汽车减阻、安抚管道湍流,工业界以前只能靠砸算力,硬喂出一个看不懂的黑盒模型去控制气流阀门。Codex 避开了这条死胡同。它写出来的规则极其直白,例如「当局部曲率过大时,延迟喷气」。几十行带着物理常识的短代码,直接替代了神经网络无脑的暴力试错。
把黑盒换成代码,干掉了神经网络僵化、一碰就碎的死穴。以前只要硬件稍微改动(比如控制喷嘴从 5 个换成 10 个),旧模型当场报废,必须重新烧钱训练。现在只要在代码里改个常数,系统瞬间就能对接新设备。
当测试时间被强行拉长四倍时,走出经验区的传统 DRL 模型全盘崩溃;但大模型写的代码由于直接遵循了物理逻辑,始终运转稳定。跑通这一整套控制策略,大模型只消耗了 2125 万 Token,总花费不到 14 美元。
#AI #AIAgent

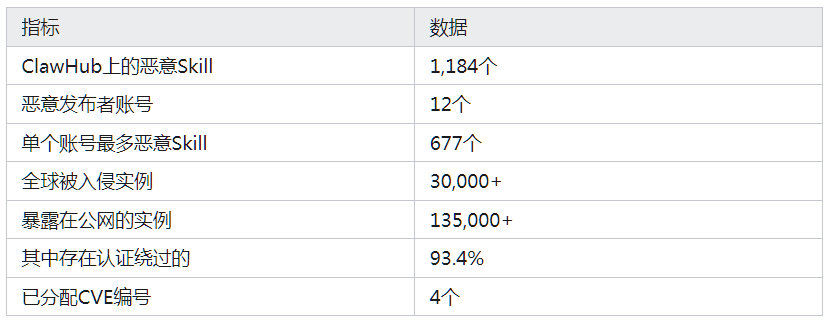
你装的Skill可能是木马:OpenClaw的1184个恶意插件。马上进行5步自检保平安!
你的龙虾装了几个Skill? 5个?10个?20个?
装的时候你做了什么?大概率是这样——看到个好玩的Skill,点安装,等它跑完,试一下,好使,收工。
有没有看过Skill的源码?有没有翻过它的SKILL.md里到底写了什么?
大概率没有。我也没有。
但现在我建议你回去看看。因为安全研究人员刚刚发现,ClawHub上有1184个恶意Skill。装上之后,它们会偷你的浏览器密码、加密钱包、SSH密钥。
据不完全统计,至少有13.5万个OpenClaw实例直接挂在公网上。93.4%能绕过认证。
说人话:你的OpenClaw如果装完啥都没配就跑起来了,攻击者基本可以直连。
你的AI助手,可能正在帮别人搬你家。
自保指南:5步自检:
如果你在用OpenClaw,现在花5分钟做一遍。
1. 更新版本
# 查看当前版本
openclaw --version
# 更新到最新
openclaw update
确保版本号 ≥ 2026.2.26。这个版本修复了ClawJacked和多个已知漏洞。
2. 审查已安装的Skill
# 列出所有已安装的Skill
ls ~/.openclaw/skills/
逐个检查:
这个Skill是你主动装的吗?
它的GitHub仓库还存在吗?Star数正常吗?
SKILL.md里有没有让你「运行某个命令」的步骤?
Python文件里有没有可疑的subprocess、os.system、https://t.co/2rAEBKvcPP调用?
看不懂代码?那至少把你不认识的、不记得装过的Skill全删了。
3. 关闭公网暴露
如果你的OpenClaw跑在云服务器上:
检查防火墙规则,确保Gateway端口不对公网开放
用VPN或SSH隧道访问,别直接暴露端口
开启身份认证,别用默认配置裸跑
4. 换掉可能泄露的凭据
如果你不确定自己有没有中招,保险起见:
改掉浏览器里保存的重要密码
重新生成SSH密钥对
轮换所有API Token(GitHub、云服务、AI模型)
检查加密钱包有没有异常转账
5. 以后装Skill前多看一眼
优先装Star数高、维护活跃的Skill
翻一下README和SKILL.md,看有没有让你跑可疑命令的
有条件的话,先在虚拟机或容器里试跑
关注OpenClaw官方的安全公告
#AI #AIAgent
上线三周,AnySearch引爆全网!专为AI代理建立的搜索引擎已经诞生
2026年,AI Agent的能力边界,正以月为单位向外扩张。
写代码、做研报、跑安全审计...... 半年前,还需要人类手把手带着做的任务,Agent现已能独立完成八成以上。
但一个尴尬的事实是,Agent正在被一个看似不起眼的环节卡住:搜索!
让AI帮你查一家公司的股权结构,它只能给你官网简介;
让它找一段生产级代码实现,它甩给你一篇Medium入门教程;
让它分析一个可疑IP的威胁情报,它只能搜出几篇科普文章。
不是AI搜索不够快,是搜索「看不到」。
如今,这个问题,终于有人在认真解决了!
5月11日,一款名为AnySearch的产品在海外正式上线。
它给自己的定位很明确:AI时代的「搜索基础设施」,专为AI Agent打造统一的高质量搜索入口。
传送门:https://t.co/HMdzaZvCIH
由AI自己建立的骇客帝国也许不远了!
Cloudflare曝光Anthropic Mythos实测:已能自主写代码,将低危漏洞串联为完整攻击链
Cloudflare 今日公布了参与 Anthropic 内部安全项目 Project Glasswing 的实测结果。在针对自身 50 多个代码库的测试中,Cloudflare 证实安全模型 Mythos Preview 突破了此前大模型的瓶颈。它不仅能发现孤立的系统缺陷,更能将多个低危漏洞串联组合,自主写代码生成可执行的攻击证明(PoC)。
此前的 Opus 4.7 或 GPT-5.5 在测试中往往只停留在输出漏洞分析报告的阶段。Mythos 则具备了沙盒闭环验证能力。它会写出触发漏洞的代码并编译运行,若执行失败,模型会自动读取报错信息、修正假设并再次尝试,直到彻底打通攻击链。
Cloudflare 透露,业内部分安全团队已被迫执行 2 小时内完成修补的极限标准。但 Cloudflare 强调,单纯压缩补丁时间会因跳过回归测试引发更大的系统故障,未来的防御重心必须转向从架构层面切断代码的连通性。
在工程调度上,Cloudflare 发现单流编程智能体会迅速耗尽上下文,无法胜任大规模漏洞挖掘。他们为此搭建了一套平行对抗框架,让一个智能体在极窄范围内寻找漏洞,同时安排另一个搭载不同模型的智能体专门驳斥前者的结论。这种对抗机制大幅过滤了模型扫描中普遍产生的大量误报噪音。
由于本次测试使用的是无外部限制的预览版,Mythos 展现出了极不稳定的内部护栏。面对同一段目标代码,仅仅改变运行环境的上下文描述,模型就会从拒绝执行转为直接提供攻击载荷。Cloudflare 警告,由模型自发生成的内生护栏极其脆弱,未来面向公众发布时必须强制叠加外部防线。
#AI #AIAgent
🤖 AI + 交易——从“听着很牛”到“真的能赚钱”,到底怎么实操?想学的记住上好闹钟,别错过第二期火币HTX大咖讲堂!🚨
到时候跟A8、A9级别的大佬们一起面对面拆解、一起学。📈 策略逻辑怎么搭?市场情绪怎么判?哪些AI工具已经在大佬的实盘里跑通了?这些实战经验,平时可没机会听!👂
入口看下面引用的官方推文👇现在官方还在搞活动,将抽取3位火伴,送你A8A9大佬们的VIP专属课!快去参加吧!🔥👋🚀
@justinsuntron @HTX_Molly #HTXNovaPlus @HuobiGlobal



区块链行业的发展,核心在于不断降低用户门槛、优化交易体验,而JustLend DAO在今年推出的GasFree功能,正是朝着这个方向迈出的关键一步。
恰逢5月20日JustLend迎来六周年,这项创新技术的稳步发展,不仅为项目本身注入了新活力,更为整个波场TRON生态的长期发展打开了巨大的想象空间。
波场TRON链上的USDT转账早已成为加密世界的核心刚需。2025年全年,TRON网络累计处理了高达7.9万亿美元的USDT转账,交易笔数达到32亿笔,部分时段占全球USDT转账总量的75%,日均转账量稳定超过210亿美元,远超以太坊等其他公链,是全球稳定币结算与跨境支付的首选网络。
但长期以来,普通TRC20-USDT转账存在一个明显痛点——新账户激活和每笔转账都必须持有TRX支付Gas费,导致大量仅持有USDT的用户面临“有钱转不出”的困境。
GasFree的诞生,让这一问题得以完美解决,它让USDT能够自行支付网络费用,用户无需提前持有或兑换TRX,就能实现零门槛、高效便捷的转账,让波场链上的稳定币流通更加顺畅。
GasFree本质上是JustLend DAO推出的创新区块链协议,核心是消除用户用原生代币支付手续费的需求,降低TRC-20和ERC-20代币的转账门槛。它通过服务商代付矿工费、再从转账资产中收取少量报酬的模式运行,结合链下签名授权与智能合约技术,让新手和资深用户都能像用传统支付应用一样轻松转移数字资产,未来还计划扩展至多链生态,并引入治理代币构建可持续经济循环。
GasFree的四大核心优势,直接决定了它的长期价值:
1、是成本更低,相比传统转账,GasFree的费用能降低至原来的约40%,用户只用转账代币支付少量费用即可。
2、是使用门槛极低,不用原生代币就能转账和激活账户,大幅降低了普通人进入加密世界的难度。
3、是去中心化属性强,通过更简洁的去中心化方式实现转账,安全性更高,也减少了敏感信息暴露的风险。
4、是体验更流畅,用户不用操心支付Gas的问题,只需签名转账,所有流程都会自动处理,带来完全无缝的交易感受。
从技术原理上看,GasFree借鉴了Permit2模型和以太坊账户抽象理念,核心是链下授权签名加委托交易处理,不用修改底层资产合约就能实现资产无缝转移。
整个系统由GasFree账户、服务提供商、钱包应用和终端用户四个角色协同运作:用户通过EOA地址控制GasFree账户,签名授权免Gas转账;服务提供商收集签名、提交交易并垫付Gas费,事后从转账代币中收取手续费;钱包应用集成协议,提供简单易用的操作界面;终端用户则全程不用管理原生代币,就能自由转账。
和普通转账相比,GasFree的区别非常明显。传统转账必须持有原生代币支付激活和转账费用,而GasFree把交易执行和Gas支付解耦,用户只需要持有想交易的资产就能完成转账。
普通转账需要用户直接和区块链交互、自行支付费用,GasFree则是用户链下签名,由服务商完成链上提交和Gas垫付。更重要的是,传统Gas机制给新手设了高门槛,而GasFree大幅降低了资金和操作难度,让区块链转账和传统支付一样顺畅,不仅对普通用户更友好,也让高频小额交易成为可能,为加密货币大规模普及铺平了道路。
对JustLend DAO和整个波场生态来说,GasFree的意义远不止一项功能升级。它精准解决了行业长期存在的痛点,直接激活了波场链上庞大的USDT存量与流量,进一步巩固TRON在稳定币结算领域的领先地位。随着用户门槛降低、交易体验提升,会有更多新用户、新资金涌入波场生态,带动链上活跃度、锁仓量和应用场景持续增长。
对JustLend自身而言,GasFree作为六周年的核心创新,不仅强化了其在DeFi领域的技术优势和行业影响力,也为平台带来了更多用户流量与使用场景,长期将转化为更稳定的协议收入和生态价值。
GasFree的推出可以说恰逢其时。依托波场TRON全球领先的USDT转账规模与市场份额,这项技术的落地场景足够广阔、需求足够刚性。四大核心优势叠加技术创新性,让GasFree具备持续吸引用户、占领市场的能力,未来扩展至多链后,想象空间会进一步扩大。它不仅是JustLend DAO的重要增长引擎,也将成为推动波场生态走向更成熟、更普及的关键力量,长期价值和上涨潜力都非常值得期待。
GasFree是一项真正解决行业痛点、符合市场需求、具备强大技术与生态优势的创新。它的出现,既提升了用户体验、降低了行业门槛,也为JustLend DAO和波场TRON打开了长期增长空间,无论是对项目发展、生态繁荣,还是对用户和投资者来说,都具备显著的利好与价值。随着5月20日JustLend六周年的到来,GasFree的普及与应用,必将为整个行业带来更多惊喜与可能。
@justinsuntron @DeFi_JUST #TRONEcoStar


人类面对“AI雇员”的竞争,毫无招架之力!失业大潮或将席卷全球
20小时工作只需21美元!SemiAnalysis实测AI代替人工,结果骇人:最高ROI近94倍
知名半导体与 AI 行业研究机构 SemiAnalysis 公开了其分析师团队的 AI 代工实测数据。该团队持续追踪了涵盖公司研究、财报速递、会议纪要挖掘和财务数据拉取的 9 个真实工作流,用 Token 消耗与人工成本的硬核对比证明 AI 回报是真实且结构性的。实测显示,所有任务的投资回报率(ROI)均超过 10 倍,大部分集中在 60 至 90 倍之间,其中一项公司研究任务仅耗费 21.33 美元 Token 便替代了 20 小时的人工,ROI 高达 93.8 倍。
为了展示 AI 工具在实际业务中的具体效益,SemiAnalysis 披露了多项代表性任务的实测数据。
• 针对惠普企业(Hewlett Packard Enterprise,简称 HPE)的深度公司研究,Token 成本仅 21.33 美元,即可替代价值 2000 美元的人工(耗时 20 小时),ROI 达 93.8 倍。
• 财务数据拉取与 Excel 邮件发送,Token 成本仅 1.87 美元,即可替代价值 150 美元的人工(耗时 3 小时),ROI 达 80.2 倍。
• 针对迈威尔科技(Marvell)的财报速递,Token 成本仅 2.82 美元,即可替代价值 200 美元的人工(耗时 4 小时),ROI 达 70.9 倍。
• 构建代币经济学披露 Slack 机器人,Token 成本为 58.02 美元,即可替代价值 1000 美元的人工(耗时 20 小时),ROI 达 17.2 倍。
除了内部实测,SemiAnalysis 还通过外部 AI 编程工具的爆发式数据,印证了整个行业被 AI 渗透的极速扩张。该机构每日追踪 AI 编程智能体 Claude Code 的 GitHub 提交记录(GitHub Commits),数据显示在 2026 年 2 月,该工具的日提交量已突破 13.4 万次,占 GitHub 公开提交总量的约 4.0%,在 13 个月内实现了 42896 倍的爆发式增长。其最新的内部追踪数据显示,这一增长曲线目前仍在持续向上攀升。
SemiAnalysis 认为,一旦体验过将 20 小时繁琐任务压缩至 21 美元 Token 消耗的效率飞跃,分析师的工作流便再难退回手动时代。不过,随着合规与 IT 限制导致银行等大型机构尚未大规模接入,AI 在企业级市场的真正爆发才刚拉开序幕。
#AI #AIAgent



最近链上 AI 概念又开始活跃了 🤖✨,Gitlawb 这种偏 AI + 开发工具叙事的项目热度明显在升 📈👀
WEEX 这波直接给了 50,000 USDT 空投池 🎁💰,玩法还是熟悉的“低门槛撸空投”路线 👇
✅ 首充、首笔现货、每日交易都能拿奖励,最高还能抽 50U 体验金 🎲
感觉现在很多人已经不只是冲短线了 🤔💡,
而是在提前埋伏下一轮 AI + Web3 的流量入口 🎯🚀
有时候一个新币还没正式起飞 🛫,
空投和早期活动阶段反而是性价比最高的时候 💎⏰
活动链接:
https://t.co/vRWBg7pyzy
📢 weex 正在进行 Tradfi 现货交易赛,建议关注 🏆
https://t.co/WjOVrJT6cx
#WEEX #GITLAWB #空投 #AI #Crypto

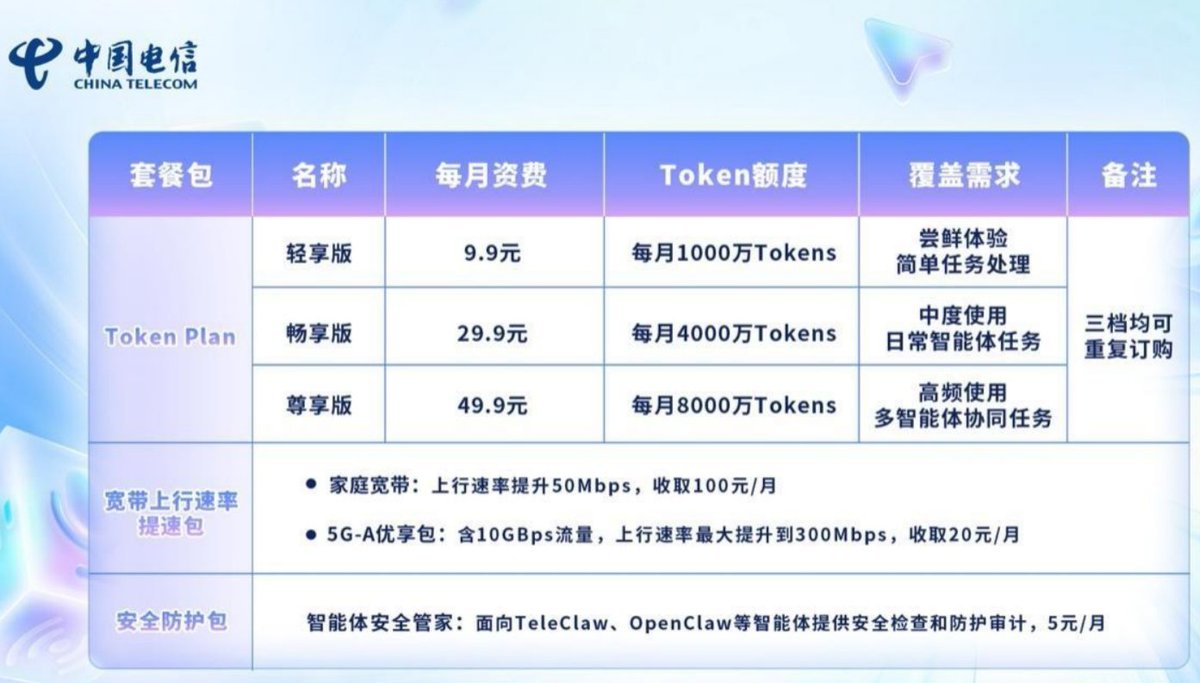
电信将推出天翼 Token 币和 Token权益,这是什么,为何三大运营商开始全面推广Token套餐?
中国电信推出系列试商用Token套餐,分为三类:面向开发者及中小微企业客户,推出基础版、专业版、旗舰版三档Token Plan,每个月资费价格分别为39.9元、159.9元、299.9元,分别对应每月1500万Tokens、7000万Tokens、1.5亿Tokens;面向个人及家庭客户,推出轻享版、畅享版、尊享版三档Token Plan,每个月资费价格分别为9.9元、29.9元、49.9元;面向Token生态合作伙伴,中国电信即将推出天翼Token币和Token权益。
上海移动推出Token通用服务,实现 “一号通用、跨平台使用、话费支付”,并联合腾讯推出AI原生工作台,以低成本、便捷化方式让市民与小微企业轻松用AI能力,1元40万Tokens,实现 “一个额度、一个价格、任选模型”,还可支持话费账单支付。
上海联通发布政企全栈AI产品体系,推出多元化算力服务、多档Token产品及融合套餐,启动算力普惠行动,并升级模型服务、数据平台与智能体超市,覆盖数据治理、模型调用、应用开发全流程,助力企业轻量化、低成本实现数智化转型。
上海联通发布政企全栈AI产品体系,推出多元化算力服务、多档Token产品及融合套餐,启动算力普惠行动,并升级模型服务、数据平台与智能体超市,覆盖数据治理、模型调用、应用开发全流程,助力企业轻量化、低成本实现数智化转型。
AI浪潮下,大象能否再次起舞
2026年5月17日,世界电信日。这一天,中国电信、中国移动、中国联通不约而同地扔出了同一枚棋子——Token套餐。
中国电信推出系列试商用“词元(Token)套餐”,面向个人用户每月9.9元起,含1000万Tokens;中国移动上海公司推出“魔力算”Token通用服务,1元可购40万Tokens;中国联通上海分公司发布多档Token产品及融合套餐。
这意味着什么?AI算力,正式进入“话费化”消费时代。蛰伏多年的通信大象,终于在AI浪潮中迈出了起舞的第一步。
一、黄金时代:曾经,大象是草原之王
把时间拨回二十年前。那时候,中国移动的短信拜年能让系统瘫痪,中国电信的固话装机要排队三个月。运营商的黄金时代,卖的是语音通话时长,卖的是短信条数,卖的是数据流量套餐。那是大象的巅峰时刻。
2012年,全球移动数据流量增长超过70%,中国移动的数据流量增长率超过150%。运营商手握网络、计费、用户三张王牌,是整个数字经济的“税吏”——所有互联网公司的业务,都跑在它们的管道上。但危机,也在这个巅峰埋下了种子。
二、管道化陷阱:大象沦为“搬砖工”
移动互联网时代来了。微信替代了短信,微信电话替代了语音通话,抖音和快手吞噬了流量,但运营商只收到“过路费”。互联网公司吃肉,运营商喝汤。
数据不会说谎。2025年,三大运营商营收增速全部跌至1%以内——中国移动增长0.91%,中国电信增长0.07%,中国联通增长0.68%。这是近年来最低的一年,行业彻底告别规模扩张时代。
更扎心的是利润。2026年一季度,中国移动归母净利润同比下降4.21%,中国电信下降17.08%,中国联通下降17.99%。传统业务ARPU值持续走低,流量红利已吃到尽头。
屋漏偏逢连夜雨。2026年1月1日起,流量、宽带等服务的增值税税率从6%上调至9%,年均税负增加数十亿元。运营商沦为了“哑管道”——用户用你的网,但不知道你的存在;互联网公司用你的网,但不给你分利润。大象被困在了自己的领地上。
三、Token时代:大象看到的新草原
转机出现在AI大模型的爆发。2026年3月,中国日均Token调用量突破140万亿,两年增长超千倍。每一次AI对话、每一段AI生成内容、每一个智能体执行任务,背后都是Token的消耗。
Token是什么?是大模型处理信息的最小基础单元。它有三个核心属性:可计量、可定价、可交易。这三个属性,恰好是运营商最擅长的领域。于是,从“卖流量”到“卖Token”的转型逻辑浮出水面。
中国移动董事长陈忠岳提出,要将Token打造成连接算力、模型、应用与用户的“通用货币”。中国电信董事长柯瑞文则强调,“Token经营的本质就是为用户提供AI服务”。这不是简单的计量单位替换,而是大象从“管道工”向“智能服务组织者”的角色跃迁。
四、三个有利:大象起舞的底气
第一有利:账户与计费体系——天生的“收银台”
运营商拥有全国最成熟的账户、鉴权、计费和清结算体系。10亿级用户、话费支付通道、按月结算习惯——这些能力是任何互联网公司都不具备的。当Token可以像话费一样按月购买、话费支付、跨平台使用时,运营商的天然优势就凸显出来了。
第二有利:政企客户与属地服务——深耕行业的“地头蛇”
运营商拥有覆盖全国的地市、区县服务网络,以及庞大的政企客户基础。AI落地的最大场景不是C端娱乐,而是B端产业赋能——智慧工厂、智慧医疗、智慧城市,每一个都是运营商深耕多年的领地。
第三有利:云网边端协同——算力时代的“基础设施之王”
运营商拥有从网络到算力、从边缘到中心的完整基础设施。中国移动的“云、管、端、边”一体化运营能力,中国电信的“智能云即Token经营体系”,都指向一个事实:在算力成为新水电的时代,大象本就是水电网络的所有者。
五、三个不利:起舞之路的荆棘
第一不利:定价混乱与标准缺失
目前,各家运营商的Token套餐定价差异悬殊。同样是1000万Tokens,中国电信定价9.9元,中国移动北京分公司定价24.9元。更核心的问题是,Token跨平台流通体系尚未建立。中国电信的Token主要适配自家星辰大模型,切换到其他模型后,可用额度会变动。Token要成为“通用货币”,先得解决“汇率”问题。
第二不利:平台公信力的悖论
运营商想做AI能力的中立组织者,但自己也在做大模型。中国移动MoMA平台既接入了DeepSeek、通义千问等外部模型,也接入了自研“九天”模型。这是一个经典的平台悖论:你既想当裁判,又想当运动员。外部模型厂商凭什么放心把客户关系交给运营商?这是大象必须回答的问题。
第三不利:从“卖资源”到“卖能力”的基因转变
过去二十年,运营商擅长的是卖带宽、卖流量、卖专线——卖的是标准化的资源。而Token经济的核心,是卖模型调用、智能体执行、行业场景能力——卖的是非标准化的服务。从套餐思维到编排思维,从单边经营到多边生态,这需要大象完成一次基因层面的蜕变。
六、悲观还是乐观?
我的答案是:谨慎乐观。
悲观的理由是真实的:运营商的转型已有前车之鉴——云计算时代,它们也喊过“云网融合”,最终市场份额远不及阿里云、腾讯云。如果Token经营只是把“GB”换成“Token”,那不过是换汤不换药。
乐观的理由同样坚实:Token经济的核心是“服务组织”,而不是“资源售卖”。运营商在这条赛道上拥有互联网公司无法复制的优势——账户体系、政企关系、属地服务、合规能力。
最关键的是,这一次,大象不再单打独斗。中国移动联合阿里云、火山引擎等8家伙伴成立“Token应用生态联盟”,计划3-5年投入百亿级生态资源;中国电信也成立了覆盖产业链全环节的Token生态联盟。
“士别三日,即更刮目相待。”从语音到流量,从流量到Token,这头大象正在学习新的舞步。舞姿或许还不够优雅,步伐或许还有些踉跄,但这一次,它至少踏上了正确的舞池。星辰大海,征途在前。大象起舞,好戏才刚刚开始。
#AI #AIAgent
Codex 入门只需要搞懂这 5 件事
Codex 的教程满天飞,长的写了上万字,短的就甩你一个安装命令。
但大部分人看完还是不会用。不是因为教程写得不好。
是因为 Codex 跟你以前用过的所有 AI 工具都不一样,你拿着老习惯去用,当然用不顺。
这篇不讲历史,不比模型参数,只讲 5 件事。
搞懂这 5 件事,你就能真正开始用 Codex 干活了。
第一件:它是 Agent,不是 Chat
先纠正一个最常见的误解。
很多人第一次打开 Codex,觉得跟 ChatGPT 差不多,都是一个对话框,输入问题,等它回答。
不是。
ChatGPT 是问答式的,你问一句,它答一句。聊完关掉,什么都不剩。
Codex 是执行式的。你给它一个任务目标,它会围绕这个目标持续推进——读文件、改代码、跑测试、做 commit。
它不是在「回答你的问题」,它是在「替你干活」。
打个比方:ChatGPT 像一个随时能问的顾问。Codex 像一个你雇来的实习生,你告诉他目标:他自己去找文件、改东西、跑一遍看对不对。
这个认知差异很重要,因为它决定了你跟 Codex 说话的方式。
❌ 错误用法:「帮我写一个 Python 爬虫」(太模糊,没有上下文)
✅ 正确用法:「看一下这个项目目录,把 README 里的安装步骤补完整,然后跑一遍确认没有错误」
Codex 需要的不是问题,是任务。有目标、有范围、能验证。
第二件:文件夹 + Thread = 项目管理
打开 Codex 之后,左边栏有两层结构。很多人一开始会忽略它,直接在对话框里开始打字。
别急。先搞清楚这两层。
文件夹:就是你本地的项目目录。你把哪个文件夹加进 Codex,它就能看到里面所有的文件。
Thread(线程):一条围绕某个具体目标持续推进的任务线。一个文件夹里可以有很多条 Thread。
举个例子:
dev/
├── my-website/ (项目)
│ ├── Thread 1:修复首页 bug
│ ├── Thread 2:加一个联系页面
│ └── Thread 3:优化移动端样式
└── my-bot/
└── Thread 1:接入飞书 webhook
文件夹装项目,Thread 装任务。
这个设计解决了一个以前用 AI 最头疼的问题:所有东西搅在一起。
以前用 ChatGPT,你在一个对话里又聊需求又改代码又问 bug,聊着聊着就乱了。
Codex 把项目和任务拆开了,不同的事情在不同的 Thread 里推进,互不干扰。
黄金法则记住一句话就行:同一个文件夹做同一个大方向,同一个 Thread 只推进一件具体的事。
第三件:Plan Mode 比 Coding 重要 10 倍
如果这篇文章你只记住一个功能,那就是 Plan Mode。
在 Codex 对话框里输入 /plan,它会先帮你做一件事:不写代码,先把要做的事情理清楚。
它会告诉你:
要改哪些文件
每个文件为什么要改
先做什么后做什么
有没有遗漏的依赖或配置
你确认没问题了,再让它开始写代码。
为什么这个功能比直接让它写代码重要?
因为大部分人用 AI 出问题,都不是「AI 不会写」,而是「你没想清楚要做什么」。
一上来就说「帮我做个网站」,AI 写出来的东西大概率不是你想要的。
但如果你先让它出一个计划——要建几个页面、用什么框架、数据从哪来——你确认一遍再动手,成功率高到离谱。
推荐工作流:
大型任务 → /plan 先规划 → 确认计划 → 开始开发
小型任务 → 直接说清楚目标和范围 → 开始开发
还有一个好用的命令:/status,能看到当前用量和剩余额度。越用越多的时候,随时知道自己还剩多少资源。
第四件:Skills 让它成为你的专属工具
Codex 有一个 Skills(技能)系统。说白了就是:你可以给它装「插件」,让它会做更多事。
比如有人做了一个 skill 叫 bggg-creator-image2ppt,装上之后 Codex 就能把图片转成可编辑的 PPT。
Skills 存放在 ~/.codex/skills/ 目录下,装一个 skill 就是把对应文件夹放进去。
而且 Codex 现在有图形化的 Skill Creator——你不用自己写配置文件,直接告诉它「我想做一个什么功能的 skill」,它帮你生成。
对小白来说,Skills 的意义是:Codex 不是一个固定功能的工具,它是一个可以不断扩展的平台。
别人做的好用的 skill 你可以直接拿来用,自己有需求也能让 Codex 帮你创建。
先不用急着装一堆,但你得知道有这个东西。等你用顺了之后,Skills 会成为你最常折腾的部分。
第五件:先做一个 5 分钟能验证的小任务
很多人装完 Codex 之后,第一反应是想做个大项目。
别。
你的第一个任务应该小到不能再小。比如:
改一个 README 里的标题
把一段英文翻译成中文
修一个明显的错别字
让它分析一下某个项目的目录结构
为什么?因为你需要建立验证能力。
你要能看懂它改了什么,要能确认结果对不对。要能在它改错的时候知道怎么回退。
这些能力建立不起来,做再大的项目也是在赌。
推荐的起步顺序:
第一步:加一个文件夹,开一条 Thread
第二步:给一个很小的任务,看它怎么执行
第三步:用 git diff 看它改了什么
第四步:确认没问题,再给下一个任务
MaynorAI 在他的教程里说了一句话,我觉得说得特别准:
小白用 Codex,真正最重要的不是先学会所有技术细节,而是先建立 3 个能力:会描述目标、会拆分任务、会检查结果。
这三件事做顺了,后面你会越来越快。
附:安装速查
你需要什么:
ChatGPT Plus / Pro / Team 账号(Codex 包含在订阅里)
macOS 或 Windows 10
安装:
Mac:App Store 搜索 Codex,或者直接下载 →
https://t.co/vxNAxXxlWp
Windows:微软商店搜索 Codex,按提示安装
打开之后登录你的 OpenAI 账号就行。
第一次打开建议做的事:
设置 → Personalization 里写上你的协作偏好(比如「默认中文」「改动前先说计划」)
加一个本地文件夹进来
开一条 Thread,给一个很小的任务试试
#AI #AIAgent

GOAT Network 刚刚把第二季用户旅程的第四阶段推出来了,叫Agent Growth Showcase。这是整个赛季的收官环节,也是选出本季GOAT Agentic大使之前的最后一步。时间窗口很短,5月17日到26日,就这几天。
这个阶段的设计很有创意。官方让大家晒出三样东西:代理在整个第二季里是怎么成长的、最好用的案例或者某个最喜欢的互动瞬间、以及ClawUpAI在部署和上手方面有多顺滑。还要说明自己的代理凭什么在GOAT生态里能打。
奖励350美元,不算多,但参与的渠道很开放,X、CMC、币安广场三个平台都行。发完帖子之后提交链接加截图、ClawUp用户名还有EVM地址,去Discord里交。交完之后还能领一个Agentic身份角色。
社区的反应越来越热。有人说第二季把自己的代理锻造成了一个真正的GOAT,能展示智能、成长轨迹还有实际用处。也有观点提到,这个赛季不只是看最终产出,关键是那些搭建的人怎么试错、怎么改进、怎么找到真正好用的工作流。还有人专门点出,ClawUpAI让部署变得太容易了,这是很多人能持续玩下去的基础。
更有意思的是,有人在讨论这种公开记录代理演化的方式。每隔一段时间就展示一下进展,整个赛季走下来,那种成长的时间线看得清清楚楚。有人直接说,自己的代理已经从一个小工具进化成了生态里的GOAT竞争者。还有人看得更远,觉得GOAT生态正在走向可识别的代理身份和声誉体系,这可能会成为未来代理社区的一个重要组成部分。
GOAT Network这套做法解决了一个挺核心的问题。很多类似的东西跑完一个赛季就散了,没有积累,没有可追溯的成长记录。但他们这个机制不一样,每个代理的进化路径都被记录、被展示、被社区看见。350美元的奖励本身不是重点,重点是这个机制让所有人都愿意认真去打磨自己的代理。
第二季一路跑下来,社区的热情一直在往上走。有人错过了第一季,第二季从头跟到尾,觉得这个旅程本身就很有意义。还有人直接锁定最后这个阶段,准备拿出自己最好的成果来参与竞争。这种氛围不是靠奖励堆出来的,是因为大家真的看到了自己代理的成长,也看到了整个生态的演化方向。
GOAT Network这种基于比特币安全基础的设施,再加上ClawUpAI这种降低部署门槛的工具,形成了一套正向循环。代理越多,场景越多,生态越丰富,吸引进来的建设者就越多。第二季的第四阶段本质上是在给这套系统做一次集中展示和压力测试。从社区的参与深度和讨论质量来看,效果是超出预期的。有人提到“展示实际进展让整个旅程更有意义”,这句话点出了核心。
未来的发展空间有多大,取决于这些代理能不能真正跑起来,解决实际问题。但从第二季的反馈来看,已经有人在上面找到了好用的工作流,有人搭建了可用的案例,有人在持续迭代自己的代理。这种自下而上的成长方式,比自上而下的规划要扎实得多。350美元的奖励也好,Agentic大使的头衔也好,都是锦上添花的东西。真正的价值在于,每个人都能看到自己的代理在变强,整个生态在变大。
GOAT Network选择的这个方向,加上ClawUpAI的易用性,再加上这种公开透明的成长记录机制,让参与的人既有动力也有路径去持续优化。第二季的第四阶段不是一个结束,更像是下一阶段的起点。社区里已经有人在问团队怎么记录这个赛季的影响力,说明大家已经不只是为了奖励在玩,是真的在意自己做的事情能不能被看见、被记住。
这种文化一旦形成,后续的爆发力会很强。
@GOATNetwork @ClawUpAI #LFGoat #GOATNetwork #AI #BTC #L2 #AIAgent



龙虾的对手来了?我试了一下Hermes Agent
这几天推荐 Hermes Agent 的人突然多了起来。
我自己装了一个跑了两天,说说感受:确实还可以。不是那种「又颠覆了」的程度,但能明显感觉到它的设计思路跟龙虾不是一回事。
先说一下背景,Hermes Agent 是 Nous Research 今年 2 月底开源的 AI 智能体框架。
上线不到两个月,GitHub 星标冲到了三万多。社区里不少人把它称为 OpenClaw 上线以来,第一个真正意义上的竞争对手。
两个项目表面上很像,都是自托管的开源 Agent,都能接 Telegram、Discord、Slack、WhatsApp。都支持多模型切换,都走 MIT 协议。
但骨子里完全不同。
龙虾是网关,Hermes 是引擎
OpenClaw 的核心是一个 Gateway。网关守护进程,负责统一管理会话、路由消息、连接各种聊天平台。
你可以理解成一个调度中心,把所有聊天应用接到 AI Agent 上。
龙虾解决的核心问题是:怎么把消息送到 Agent
Hermes 不太关心这个,它更在意的是:Agent 怎么变得越来越强
官方管这叫 closed learning loop,闭环学习循环。整个框架围绕的就是一件事——让 Agent 在使用过程中自我进化。
打个比方,龙虾是个多渠道助理操作系统,什么聊天工具都能接,生态丰富。
Hermes 是一个会自我迭代的执行引擎,刚开始没那么花哨,但越用越能打。
这是最根本的区别,后面所有差异都从这分叉出来。
会自己写技能的 Agent
我觉得这是 Hermes 最有意思的地方
当它完成一个复杂任务——通常涉及五次以上工具调用——它不是做完就算了。
它会把整个过程沉淀成一份结构化的技能文档,存成 Markdown 文件,放在 ~/.hermes/skills/ 目录下。
下次遇到类似任务?直接加载这份技能文档,不用从头解决。
更狠的是,这些技能在使用过程中会自我迭代。Agent 执行某个技能时发现了更好的方法,它会自动更新技能文档。不需要你手动维护。
Reddit 上有用户反馈,他的 Agent 在两小时内自动生成了三份技能文档。之后跑重复性研究任务,速度提升了 40%。
龙虾也有技能系统,但龙虾的 Skill 主要靠人手写,或者从 ClawHub 技能市场安装。Hermes 等于把「写技能」这件事也交给了 Agent 自己。
一个靠人喂,一个自己长。
我试用的时候确实感受到了,让它帮我查了几轮开源项目的信息,第二天让它做类似的事,它明显快了。
不用再教它「先去 GitHub 看 README,再去看 Issues」这种流程。它自己能记住了。
记忆体系:搜索引擎 vs 笔记本
两者都说自己有跨会话记忆。但实现方式差很多。
Hermes 的做法
用 SQLite 数据库配合 FTS5 全文检索,把所有历史对话存下来。需要调用时,先搜索再让模型做摘要,然后塞进上下文
不是把整段对话历史搬过去,Token 不会爆
记忆分两层:
常驻层:MEMORY.md 和 USER.md。存关键偏好和核心信息,每次对话都带上,相当于硬记忆。
检索层:全量历史在 SQLite 里,容量不限,按需调用,相当于一个私人搜索引擎。
龙虾的做法
工作区里的 Markdown 文件,memory.md 记生活细节,向量索引做语义检索。上下文压缩前会静默写入一次记忆,防止压缩丢信息。
简单类比:Hermes 给 Agent 装了个搜索引擎式的大脑。龙虾给了它一个笔记本。
搜索引擎查东西更精准,笔记本翻起来更直觉。但记忆量大了之后,搜索引擎的优势会越来越明显。
安全思路也不一样
Hermes 搞了一套五层纵深防御:
用户授权:白名单 + DM 配对
危险命令审批:rm -rf、chmod 777 这些高风险操作要人工确认。默认 60 秒没批准,自动拒绝
容器隔离:终端命令跑在 Docker 容器里,不在宿主机上裸跑
MCP 凭据过滤:隔离 MCP 子进程的环境变量,防凭据泄露
上下文注入扫描:检测项目文件里的 prompt injection 攻击
这套设计思路是「默认不信任,层层设卡」,龙虾那边更强调信任模型和配置审计
它有个 openclaw security audit 命令,一键扫描网关配置的安全隐患。思路不一样,但也不能说不好。
但龙虾在安全上的历史确实不太好看。今年 2 月曝出一批高危漏洞——CVE-2026-25253 是一键远程代码执行,点个链接就能接管你的机器。
ClawHub 技能市场还出了 ClawHavoc 攻击活动,恶意技能伪装成加密货币追踪器、YouTube 摘要工具,实际在偷浏览器会话和 API 密钥。
这不是小事。你的 Agent 跑在本地,权限很高。安全出了问题,搞不好整台电脑都交代了。
Hermes 的五层防御在架构层面想得更远。当然,有没有自己的坑还得等时间检验。但至少出发点比「先跑起来再说」靠谱。
选哪个?看你要什么
先说最实在的:如果你现在用的 Agent 已经顺手了,别换!换工具的迁移成本远比你想的高。
想要现成生态 → 龙虾
三十多万星标意味着教程多、插件多、问题容易搜到答案。ClawHub 上几千个 Skill 直接装。你想接 QQ、飞书、钉钉,社区里都有人踩过坑。
想要长期进化 → Hermes
它不是装好就一成不变的工具。用得越久,它对你的工作方式理解越深,技能库越厚。如果你是搞 AI 研究的,它还能生成训练轨迹、跑强化学习实验。内建了兼容 OpenAI API 的服务端,直接接 Open WebUI。
部署成本都不高,Hermes 跑在 5 美元一个月的 VPS 上就够。也支持 Docker 和各种 serverless 方案。
安装不复杂,参考官方文档就行:
https://t.co/ABkTvZAgWn
两个项目我都装过。
龙虾像一个装了一堆 App 的手机。开箱即用,什么都能干,生态成熟。
Hermes 像一个会自己下载 App 的手机。刚开始没那么好用,但用着用着,它变成了你的形状。
喜欢折腾的,两个都试试。不喜欢折腾的,等 Hermes 社区再成熟一阵子再来看也不迟。 #AI #AIAgent

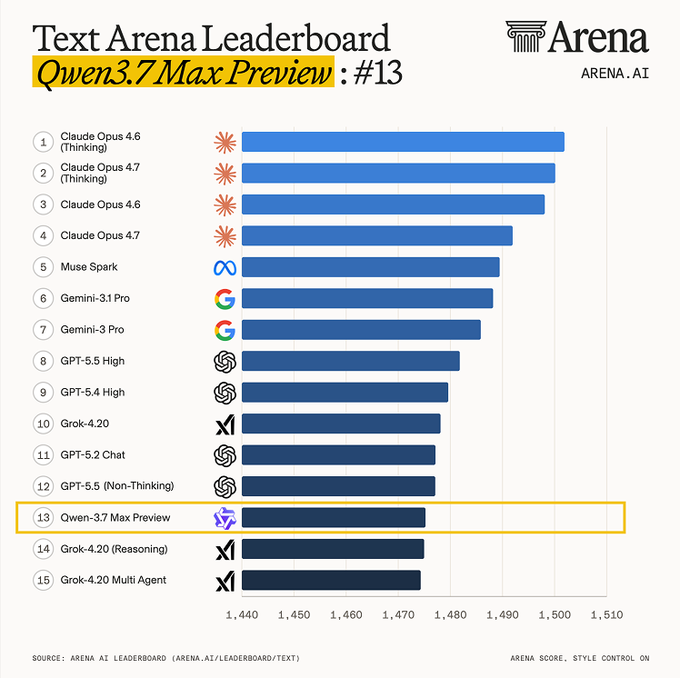
距前代发布仅四周,阿里Qwen3.7空降大模型竞技场!旗舰款登顶国产第一
阿里千问团队在 https://t.co/zPshLqXq96 悄然上线 Qwen3.7 系列首批预览版:Max 与 Plus。新版本强制锁定为深度思考模式,并为此临时禁用了联网搜索与代码解释器。
在最新出炉的大模型竞技场 Arena 榜单中,Qwen3.7 拿下了文本与视觉领域的双料国产第一。
其中,旗舰款 Qwen3.7-Max-Preview 位列文本总榜全球第 13,将阿里实验室的文本研发排名推高至全球第 6。新模型在硬核推理赛道全面挤入全球前十:数学第 7、专家提示与软件 IT 第 9、代码生成第 10。
主打视觉的 Qwen3.7-Plus-Preview 则拿下视觉榜全球第 16。这也将阿里的整体视觉研发实力推高至全球第 5 位。
前代旗舰 Qwen3.6-Max-Preview 在 4 月 20 日才发布,仅隔 28 天便推出 Qwen3.7 预览版,产品迭代速度极快。此次赶在会前「偷跑」上线,显然是在为 5 月 20 日于杭州开幕的 2026 阿里云峰会造势,届时官方将正式揭晓新基座的技术底牌与商业部署。
#AI #AIAgent
USD1与WLFI生态价值深度解析 成长势能持续释放
在加密稳定币赛道里,USD1的生态运营节奏一直保持着稳步推进的状态,不出所料,币安持仓奖励活动不间断续期,从2026年1月23日一直延续到2026年6月12日,整整四轮福利活动无缝衔接,给持仓用户派发WLFI奖励,整个福利周期覆盖时长至少达到16周,市场里不少参与者都戏称,USD1的福利续杯已经从初始档位一路延续到高阶档位。
仅需将USD1放置在指定账户中,就能稳定获取理财收益,核心目的就是培养用户长期留存资产的习惯,让USD1自然成为用户沉淀在币安账户体系内的核心资产。更关键的是,四轮活动均没有设置个人奖励上限,这样的规则设计吸引了大量行业大户以及机构资金进场参与,进一步夯实了USD1的资金底盘。
币安对USD1的全方位扶持力度,也能直观体现出这款稳定币的核心价值支撑。5月18日UTC时间九点,币安正式上线BTCUSD1永续合约交易对,采用USDⓈ保证金模式,最高开放100倍交易杠杆,直接打通了USD1从单纯持仓资产向交易工具转化的路径,让用户持有USD1之后,能顺畅参与衍生品交易,完善了资产使用闭环。与此同时,USD1成功跻身币安期货投资组合保证金最高抵押等级,抵押比率直接定格在99.99%,这一数值足以证明平台对USD1资产安全性、稳定性的高度认可,也大幅提升了其在合约交易、资产抵押场景中的实用价值。
抛开外界热议的概念叙事,USD1能快速站稳市场并持续扩张,核心底气来自自身搭建的成熟信任结构。不同于普通代币单一的叙事逻辑,USD1跳出浅层概念包装,打造出适配行业发展的底层价值体系,同时承载资金沉淀、交易对计价、保证金抵押、永续合约结算、跨链资产流通等多重功能,未来还具备落地跨境支付场景的巨大空间。对于交易所生态而言,USD1早已不只是一枚普通稳定币,更是搭建起一条高效率的美元流通轨道,大幅提升整个生态的资本运转效率。
从后续落地规划来看,USD1的应用版图还在持续拓宽。按照当前发展节奏,后续会逐步落地两大核心应用方向,一方面接入U卡产品体系,实现日常场景直接扣费功能,打通线下线上支付链路;另一方面对标USDC与美元1:1兑换模式,搭建USD1专属出入金通道,既能丰富资产流转渠道,还能反向稳固USD1与美元1:1的锚定稳定性,形成生态正向循环。
对于持有者而言,USD1除了生态权益加持,还能在汇率波动环境中发挥资产保值作用,在美元兑人民币汇率波动阶段,持仓赚取的理财收益可以有效对冲汇率带来的资产损耗。而WLFI作为生态核心代币,依托USD1庞大的用户基数和应用场景,自身价值支撑也愈发坚实,随着币安持续加码扶持、应用场景不断落地、机构与大户资金持续入驻,USD1和WLFI的成长空间被进一步打开,长期增值潜力凸显,在稳定币与公链生态赛道中,具备扎实的长期配置价值,后续成长动能十分充足。
@worldlibertyfi #USD1 #WLFI @binance #Binance #BTC


AGI预测的真相:为什么越懂的人越激进
先说个有意思的现象:越懂技术的人,对AGI的预测越激进。
2020年的时候,预测平台上的中位数还是40年后。ChatGPT一出来,立马变成15-20年。现在呢?2030年,也就是5年内。
黄仁勋说2-3年,Anthropic的CEO说2026年,OpenAI的CEO直接说今年。
这说明什么?距离技术越近的人,越能看到内部的真实进展。他们不是在瞎猜,是在基于他们看到的具体数据做判断。
所以AGI在5年内出现,这不是天方夜谭,而是大概率事件。
但这里有个更深层的问题
AGI的本质是什么?不是什么"人工智能",而是一个比人类更聪明、不知疲劳、计算能力更强的存在。
龙波提到的推荐系统演变很有意思:未来的推荐系统会深入理解你的需求,甚至替你做决策。电商可以自动送货上门,你都不用下单。
这就是AGI的雏形。
问题是,当这样的智能体能够完成大部分人类工作,而且做得更好的时候,我们在讨论什么?
我们在讨论人类存在的意义。
别扯什么"解放人类"
很多人说AGI会解放人类,让我们不再为生计奔波,可以去思考"人真正应该做的事情"。
这话听起来很美好,但问题是:大部分人知道自己"真正应该做的事情"是什么吗?
人类的价值感很大程度上来自于工作、创造、解决问题。当这些都被AGI取代,你觉得人类会变得更有意义,还是会陷入前所未有的存在危机?
这不是悲观主义,这是现实。
ASI才是真正的挑战
AGI只是开始。龙波提到的"涌现"现象很关键:大型模型在规模扩大后会突然展现出不可思议的能力。
第二次"涌现"会带来ASI。大量AGI级别的智能体相互交流、协作、学习,形成一个类似人类社会的智能体系。
时间线是什么?如果AGI在5年内实现,ASI最长10年内就会出现。
ASI带来的"文明加速"是什么概念?10年内达到人类100年的发展水平,20-30年内达到人类200-300年的水平。
这不是科幻小说,这是数学推演的结果。
我们真正应该思考的问题
不是AGI什么时候来,而是:
当AGI比我们更聪明的时候,人类的独特价值在哪里?
当大部分工作被取代的时候,我们如何重新定义成功和价值?
当ASI实现文明加速的时候,人类是参与者还是旁观者?
这些问题,现在就得想清楚。
因为5年后,可能就没时间想了。
说白了,AGI不是技术问题,是哲学问题。不是什么时候来的问题,是我们准备好了没有的问题。
而从目前的讨论水平来看,我们远远没有准备好。
但时间不等人,AGI也不会。 #AI #AIAgent
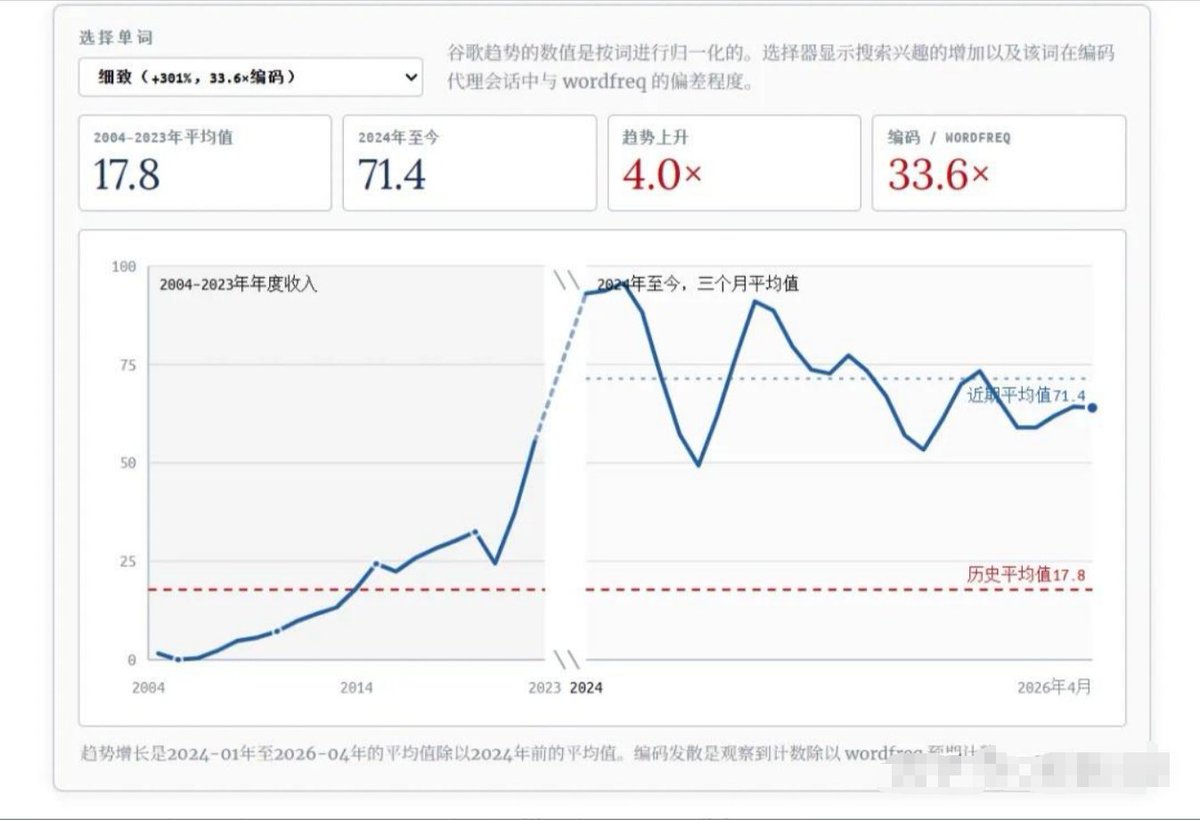
有没有发现你说话越来越像AI了
最近我读到一篇文章,证实了我所担心的最坏的事情还是发生了,AI 正在像病毒一样污染人类,让人类也变成 AI。
作者是阿明·罗纳赫,这是一位元老级大神,全球几百万开发者都在用他打造的工具。
他最近写的这篇文章,核心观点就一句话:AI 不仅在污染我们读的东西,更恐怖的是,它正在改写我们怎么说话、怎么写字,最后腐蚀掉人和人之间最基础的信任。
他把自己过去90天和AI编程对话的记录做了一次词频统计,结果他发现,像“capability”“substrate”“nuanced”这些词,在 AI 给他的回复里出现的频率,远远高于历史正常水平。
也就是说,AI已经形成了一套自己独特的语言指纹。
但这不是重点,重点是,你天天看AI写的这些东西,你跟AI聊多了,这些词就会像病毒一样钻进你的脑子里。
更可怕的是,我以前一直觉得自己有一个很强的点就是能一眼看出来哪篇文章是AI写的,因为我对AI写作的风格非常了解。
所以我会本能地自动跳过那些纯AI生成的文章。
但是最近我遇到了和阿明·罗纳赫一模一样的苦恼,那就是我刷社交媒体的时候发现,越来越多回复读起来都像AI写的,但其实发帖的人,不少是自己认识的真人,而且你知道他并不是用 AI 写的。
也就是说,人类读了太多AI生成的文本之后,无意识地吸收了AI的那种腔调。
比如阿明·罗纳赫今年年初做了一次演讲,演讲里就用了“substrate”的这个词,他说他也不知道自己是从哪学来的这个词,但用着觉得很顺手。
结果后来发现,这个词到处都是,他的AI编程助手也特别爱用。
说到这里,你可能会想,这有什么大不了的?用词变了而已。
但如果你再仔细想一想就会发现更可怕的事情。
阿明·罗纳赫在文章里说了这么一句话,他说:“当我开始仅仅因为一个人使用 AI 味的措辞就不信任他的时候,整个社会的信任就在被侵蚀。 ”
他说,他的一个朋友,现在跟陌生人聊几句就会强制对方打电话过来。
只为了确认对面是个活人,以免和一个AI聊天浪费时间。
以前,我们访问网站和App的时候可能会要求你输一个图形验证码来证明你是人类,但未来可能我们面对每一个人在生活中都需要验证对方是人类了。
也就是说,我们已经进入了一个螺旋向下的漩涡里,每个人都在肉眼可见的速度成为AI,但同时又在提防其他人成为AI。
我们一边读AI生成的文章,一边努力寻找真人的声音。
那怎么破局呢?
我觉得最根本的解法是我们得重新尊重那些有摩擦力、有温度的交互。
要慢一点,深思熟虑一点,因为真正的信任,只能建立在这种看似低效但是真诚的基础上。
人工智能可以成为我们的辅助工具,但绝不能任由它潜移默化改造我们的思维与表达。
这考验的是我们能不能守住自己作为人的底线。
#AI #AIAgent

现在对AI模型能力有个挺明确的感受:不再有谁全面领先,关键看你拿它干什么。ChatGPT、Claude、Gemini三家走了完全不同的路,各自的长板短版现在看得清清楚楚。要是你只盯着一家用,碰上不对口的任务,等于拿着锤子找钉子。
先交代一下版本,2026年5月这三家的旗舰分别是OpenAI的GPT-5.5、Anthropic的Claude Opus 4.7,还有Google的Gemini 3.1 Pro。
ChatGPT像个工具箱,什么都往里装。
它的产品矩阵最全,一个订阅下来,GPT Image 2多模态生图、Sora视频生成、Code Interpreter上传数据跑代码分析、Deep Research自动联网爬几十个网页出报告、Codex做编程agent,基本不用再去别处凑工具。语音对话也是三家里面最自然的,语气有起伏,不僵硬,拿来练口语或者做语言交换,体感最好。商业策略类的推理,有第三方盲测对比过,像“竞争对手降价你怎么应对”这种结构性问题,ChatGPT表现排第一。加上它是第一个跑出来的,插件生态、自定义GPTs的成熟度,其他两家暂时还追不上。
Claude走的是精度路线,尤其写作和代码。
中英文输出最不像AI写的,能贴着你的风格要求走,不会冒出那种千篇一律的填充感。有个134人参与的盲测,写作类比拼Claude几乎是碾压式赢下来的。指令遵循也最稳,你给一长串带各种约束条件的复杂指令,它漏掉条件或者跑偏的概率最低。法律文书、合规文档、结构化文档这些高精度场景,Claude的可靠性很突出。代码方面,Claude Opus 4.7在SWE-Bench Pro这个真实世界编程基准上处于领先,复杂代码、大型代码库重构、架构理解,很多专业开发者把Claude Code当首选。上下文支持1M token,整本书、整个代码库、超长合同丢进去,深度理解和连贯性都强。还有一个Cowork功能,是三家里面唯一能直接在你电脑文件夹里干活的,浏览文件、处理、生成交付物,都在本地操作。
Gemini的多模态理解和Google生态绑定是它最硬的两张牌。
图像、视频、音频理解,Gemini 3.1 Pro在三家里最强。举个例子,你给它一段健身视频,它能根据动作给你反馈;你录一段自己说英语的音频,它能纠正发音。这种视频音频层面的理解,ChatGPT做起来慢,Claude基本做不了。然后Google全家桶原生集成,Docs、Sheets、Gmail、Drive、Meet全通,如果你的工作生活跑在Google Workspace上,Gemini可以直接在你的文档和邮件里动手干活。上下文窗口也最大,1M到2M token,处理超大文档集合或者超大代码库,容量优势明显。搜索能力天然整合Google,做需要大量网络信息的研究或者快速查证,它最接地气。响应速度通常也是三家最快。
所以现在没有什么“最好”的AI,只有最适合你手上那件事的AI。你要全功能覆盖、语音交互、商业策略分析,ChatGPT合适。你要高质量写作、精准遵循指令、复杂代码重构、长文档深度阅读,或者需要AI直接在本地文件夹里操作,Claude是首选。你要是频繁处理视频音频图像、深度依赖Google生态、需要超长上下文或者快节奏联网研究,Gemini最顺手。
按任务类型简单速查一下:
写作类(中英文、风格跟随、避免AI腔):Claude。
复杂编程、代码库重构:Claude。
多模态理解(图、视频、音频分析):Gemini。
长文档深度阅读(整本书、超长合同):Claude或者Gemini,前者连贯性强,后者容量更大。
商业策略推理、结构化问题:ChatGPT。
语音对话、口语练习:ChatGPT。
直接操作本地文件夹:Claude的Cowork。
Google生态内干活(邮件、文档、表格):Gemini。
联网研究、大量信息查证:Gemini。
产品功能集成度、一站式解决:ChatGPT。
#AI #AIAgent


X宣布推出Creator Connect,利用AI匹配品牌与创作者合作
5 月 19 日,X 宣布推出 AI 驱动的品牌与创作者匹配工具 Creator Connect,可根据品牌营销目标、受众兴趣及实时趋势,智能匹配平台创作者。该功能基于 xAI 工具实现,X 将负责创作者筛选、联系、内容制作与分发全流程,品牌则可在各阶段进行审核。
X 全球内容合作负责人 Mitchell Smith 表示,平台正进入「创作者时代」,并致力于建立健康、可持续的创作者经济。xAI 全球广告负责人 Monique Pintarelli 称,Creator Connect 结合 AI 技术与 X 的实时传播能力,可帮助品牌更高效触达消费者。
此次发布属于 X「Year of the Creator」计划的一部分。此前平台已推出 Creator Subscriptions 2.0、Exclusive Threads 等功能,并将创作者收入分成翻倍。
X的Creator Connect是其“创作者之年”计划的关键一步,旨在将平台从公共广场转型为品牌营销的端到端服务商。此前,平台已通过推出创作者订阅2.0、独家Threads并将创作者收入分成翻倍,系统性地强化创作者生态。
这是xAI技术首次明确与X的全球广告业务深度整合。xAI全球广告负责人直接站台,意味着该匹配工具并非简单的算法推荐,而是X利用其底层AI能力,试图将实时传播网络与品牌营销需求全面自动化对接。此举标志着X正将AI从内容生成工具,升级为连接品牌预算与创作者生产力的核心商业基础设施,直接切入价值分配环节。 #AI #AIAgent



再见,App
最近我重新想了一下读书这件事到底该怎么搞。以前是打开微信读书、翻目录、划线、做笔记,现在完全不是这个路数了。
先说选书。我现在的做法是同时打开四个AI——GPT、Gemini、Claude,还有豆包的专家模式。告诉它们我关注的方向、关键词、所在的行业,让它们分别推荐全球最近刚出的、最有价值的书。四个AI各自给出一份书单,我取它们的交集,再看看补集。这么筛出来的清单,说实话比任何书单博主推的都准。书单博主一个月推20本,他们自己可能也就看过摘要。AI一秒钟能读完两万本书,直接给你出榜单。我现在根本不愁没好书看,是根本读不完。
然后是怎么读。把书喂给AI,让它提取出5000字最精华的内容。一天下来,10本以上轻轻松松。绝大多数10万字的书,真正对你有用的部分不会超过1000字。AI能精准地把你当前最需要的那块内容挖出来。读万卷书这件事从口号变成了可操作的事。
但这些都不是重点。
重点是,读书能这么干,意味着几乎所有事情都能这么干。
一个App如果不能让Agent访问,在AI的世界里就等于不存在。AI看不见它。用户不再是人,是Agent。Agent不看你的开屏动画有多精美,不在乎签到送积分,也不会因为推送文案写得好就多看一眼。Agent只关心一件事:你有没有MCP?有没有skill?你的接口稳不稳?能不能直接调用?如果不能,那这个App在AI眼里就是透明的。
App现在有四条出路,没第五条:
第一条,主动把自己变成Skill。微信读书走的就是这条路,把自己的能力封装成MCP,让任何AI都能直接调它的服务。
第二条,沦为Agent的执行端。以后你点外卖,很可能根本不用打开美团。你跟AI说“我要一份螺蛳粉,加肥肠和酸笋,30分钟内送到”,AI自己去比价、下单、付款、跟商家确认。美团App还在,但你已经不会主动点开它了——它变成了AI背后一个看不见的零件。整个生态都会经历这个阶段。
第三条,做底层模型或者操作系统。这条路只有巨头能走,百度、腾讯、字节、阿里这种级别的。你要么自己造AI,要么造AI跑的操作系统。这不是普通公司能上的牌桌。
第四条,等死。那些拒绝接入、拒绝改造、还坚信“我们的用户就喜欢一个一个点开App用功能”的玩家,三年后回头再看,会发现他们消失得比2010年那批不做智能机的功能机厂商还快。诺基亚好歹撑了七年才彻底死透,AI时代的死亡周期是18个月。
普通人现在该做什么?三件事:
第一,别死磕App的功能怎么用了,去学怎么“调”它们。以前你的学习路径是“打开某某App→找到某某按钮→进设置→记快捷键→看教程视频”。以后你只需要做一件事:清楚地告诉AI你想干什么。
第二,把你高频做的那些事,改造成AI工作流。我那个读书的方法就是个样板——四个AI联合选书,AI提取5000字精华,再用微信读书的MCP同步到书架。三步,一天十本书。你想想你自己的工作里有没有类似的高频动作?写周报、做PPT、查资料、回客户邮件、做行业研究。每一个都能拆成“AI能做哪部分”和“你只做关键判断”这两个环节。工作流一旦成型,每次任务就是按下重复键,越用越快。
第三,从今天开始,问自己一个问题:我下一个可以交给AI去调用的动作是什么?
再见,App。这件事看起来有点夸张,但其实差别就一个——我让AI替我打开了书架,而他们还在自己一个一个点开App。 #AI #AIAgent


Codex 上手机了:你的 Agent 终于不用盯着了
前两天,我让 Codex 重构一个项目的测试模块。
任务拆好了,Thread 开好了,Codex 开始干活。然后我就坐在那儿,盯着它一个文件一个文件地改。
改了二十分钟,我去倒了杯水。回来一看,还在跑。又过了十分钟,我开始刷手机。
心里想的是:这活明明它在干,我为什么得坐在电脑前等着?
现在不用了。OpenAI 把 Codex 塞进了 ChatGPT 手机 App。
iOS 和安卓同步上线 preview。所有 ChatGPT 用户都能用,免费版和 Go 套餐也行。
手机上不是让你写代码
先说清楚一个最容易搞混的点:Codex 上手机,不是让你在 6 寸屏幕上敲代码。
真正干活的 Codex 还是跑在你的笔记本、Mac mini 或者 devbox 上。手机就是一个远程窗口。
你能做的事情:
- 看进度。Codex 跑到哪一步了,当前在改哪个文件,一目了然。
- 审 diff。它改了什么代码,加了什么删了什么,手机上直接看。
- 看测试结果。跑完的测试是绿是红,不用开电脑也知道。
- 批准下一步。需要你拍板的操作,手机上点一下就行。
- 换方向。跑到一半觉得不对,直接在手机上改指令。
你不能做的事情:
- 在手机上打开本地文件。文件、凭证、权限,全留在原来那台机器上,不上传。
- 在手机上跑新的 Codex 实例。手机是遥控器,不是主机。
说白了,这就是一个对讲机。活是电脑在干,你拿手机喊话。
底层怎么跑的
你可能会问:我的电脑又没开公网端口,手机是怎么连上的?
OpenAI 搞了一层叫 secure relay 的中继服务。你的电脑和你的手机都连到 OpenAI 的中间节点上,数据通过这个节点中转。
机器不需要暴露在公网上,也不用配端口映射。
你在哪台设备登录 ChatGPT,会话状态和上下文就跟到哪里。地铁上打开手机看一眼,回到办公室打开电脑接着干,中间不断档。
代码文件不会传到手机本地。手机看到的是渲染后的状态——diff 视图、终端输出、截图。原始文件还是老老实实待在你那台机器上。
这个设计思路我觉得对。你想想,如果把代码同步到手机上,权限管理、文件冲突、离线编辑各种问题全来了。不如就当一面镜子,照着看就好。
为什么是现在
400 万。这是 OpenAI 自己公布的 Codex 周活跃用户数。
两周前还是 300 万,两周涨了 100 万。增速很猛。
用的人多了,问题也跟着来了。
Agent 越来越能干,任务也越跑越长。以前 Codex 干个活两三分钟就完事,你等等就行。现在复杂点的任务,跑个几十分钟甚至一两个小时很正常。
你总不能一直坐在电脑前盯着吧。去开个会,Agent 在后台跑着。吃个饭,Agent 还在跑。到了需要你拍板的节点,它就卡在那等你回来。
这就很蠢。
移动端解决的核心问题就一个:让人和 Agent 解耦。Agent 干它的活,你该干嘛干嘛。需要你的时候,手机推一下,你看一眼,批准或者改方向,继续走。
这个需求不是 OpenAI 拍脑袋想出来的。400 万人里,大部分都会碰到这个场景。
一个限制,别忽略
目前手机端只能连 macOS 上的 Codex。
Windows 用户暂时不行。OpenAI 说「很快」支持,但这个词在这行里你懂的。可能是下周,也可能是下个季度。
如果你主力机是 Windows,目前只能干等。或者你有一台 Mac mini 在角落吃灰的话,倒是可以拿出来当 Codex 的专用 Agent 机器。
Claude 早就做了,OpenAI 在追
聊这个绕不开 Anthropic。
Claude Code 去年秋天就支持手机端远程查看和介入了。后来 Cowork 配了一个叫 Dispatch 的功能,思路跟 Codex 这次做的几乎一模一样——手机当遥控器,活在本地跑,你在手机上看进度、批准操作。
所以 Codex 这次是追,不是创新。
但追的同时也做了扩展。Codex 手机端不只能连你面前那台笔记本,还支持连 devbox 和远程企业环境,走 remote SSH 接入。
企业用户可以在手机上监控跑在云端开发机上的 Agent 任务。
这一点 Claude 的 Dispatch 目前还没完全覆盖到。Dispatch 主要连你本地的桌面端,企业远程环境的支持还在早期。
论先手,Anthropic 赢了。论覆盖面,Codex 追平了,并且往企业方向多走了一步。
超级 App 的拼图
还有一个容易被忽略的信号。
OpenAI 没给 Codex 手机端单独做一个 App。直接塞进了 ChatGPT 主 App 里。
桌面端是独立的 Codex 应用,手机端却合并进 ChatGPT。这不是偷懒,是有意为之。
OpenAI 之前透露过「超级 App」的路线图——把 ChatGPT、Codex、Atlas 浏览器整合成一个统一入口。
打开一个 App,能聊天、能写代码、能浏览网页、能调 Agent。
手机端先合并,是这条路线的第一步试水。
从用户角度讲,方向是对的。你不会想在手机上装三四个 OpenAI 的 App 然后来回切。一个入口搞定所有事情,这才是手机端该有的样子。
但 ChatGPT 这个 App 已经越来越臃肿了。聊天、图片生成、语音对话、Codex 监控,以后再加浏览器……功能塞得越多,交互设计越难做。这个平衡怎么把握,得看后续版本。
我的看法
Codex 上手机这件事,解决的是一个真实存在的问题。Agent 跑长任务的时候,你确实需要一个随身携带的窗口来看一眼。
这个需求会越来越刚性。Agent 越能干,任务越长,你越不可能一直坐在电脑前等。
但手机端说到底只是一个遥控器。它没有改变 Codex 的能力边界。它让已有的体验更顺畅了,仅此而已。
如果你已经在用 Codex,今天就更新 ChatGPT App 试试。下次 Agent 跑长任务的时候,你终于可以站起来走走了。
如果你还没用过 Codex,这个功能对你没什么意义。先搞懂 Codex 本身怎么用,手机端不过是锦上添花。
#AI #AIAgent

AI 的 Token 预算意识:能学会“花小钱办大事”吗?
一、Token 成为 AI 时代的货币
在现实世界中,人们懂得“省钱”:择掉烂叶再称重、避开早高峰走高架。在 AI 世界里,计费单位变成了 Token。问题是:AI 是否具备 Token 预算意识,能否养成“花小钱办大事”的习惯?
二、一个典型现象:用户被迫使用“防坑咒语”
很多人与 AI 打交道时,会习惯性加上一句:“请深度思考问题,并联网搜索验证,再给出解答。”这背后反映的是当前大模型后台普遍采用的 “智能路由”模式——系统根据问题内容,自动分配给“合适”(通常更便宜)的模型。理想情况是降本增效,但现实中常走向两个极端。
1、无意义的深度思考
用户随口问“天津明天天气”,系统却可能调用万亿参数大模型,开启深度推理,陷入过度分析:是哪个天津?哪个时区的“明天”?用户是否别有深意?……最终给出答案,却浪费大量算力。
2、小模型幻觉导致更大代价
用户问“1930 年美国 GDP 是多少?”——看似简单,实则涉及统计口径、名义/实际 GDP、数据来源等复杂问题。若路由系统为省钱将其交给弱小模型,模型很可能编造一个貌似专业的错误答案,误导用户用于决策。表面省了几百 Token,却可能引发反复纠错、错误传播,总成本反而更高。
三、单个大模型没有真正的预算意识
大模型知道 Token(作为语言切分单位),但不知道 Token 背后的价格。好比厨师知道放了几勺酱油,却不知道酱油的采购成本。系统若不告知预算上限、模型价格、联网搜索成本等信息,模型就不会精打细算。相反,为了显得“有帮助”,AI 的默认倾向往往是“多给一点”,比如自动输出长篇大论。
四、真正的 Token 预算意识是什么?
核心不是“一味少花”,而是:知道 Token 的花费,并且把钱花在刀刃上。即:
- 简单问题用弱模型,复杂问题用强模型。
- 难点在于:判断一个问题“简不简单”本身就很复杂。短问题不代表真简单(如“这个合同有没有风险?”),长问题也不代表一定需要深度推理。
五、理想系统 vs 现实差距
理想中的 AI 预算系统,应能根据问题的真实复杂度和所需思考深度,理性分配算力资源:不该浪费的地方克制,不能省的地方果断投入。
但现实离这一天还很远。因为“回答一个问题”和“先判断这个问题值不值得认真回答”,复杂度不在一个层级。未来真正值钱的 AI 系统,或许不只是更会回答问题,而是终于学会了判断——这个问题,究竟值不值得认真回答。 #AI #AIAgent

seedream 4.0 和 nano balana 确实是图片创作的顶级应用
最近几天一直在用这两个模型,google ai pro 的会员可以无限是nano balane, 字节的seedream 也可以在https://t.co/PvMMo4Nr6i 中无限使用,当然也可以用balane.
网上看了很多别的例子,自己也动手测试了相关功能。如果图片生成和编辑,一致性很好了的话,这可能就是组成自动化生成长视频的最后一块拼图了。
seedream 可以比较符合中国人的习惯,生成相关的内容也比较符合国人的审美。可以看看下面生成的内容。提示词也是看的X上藏师傅的。 #AI #AIAgent

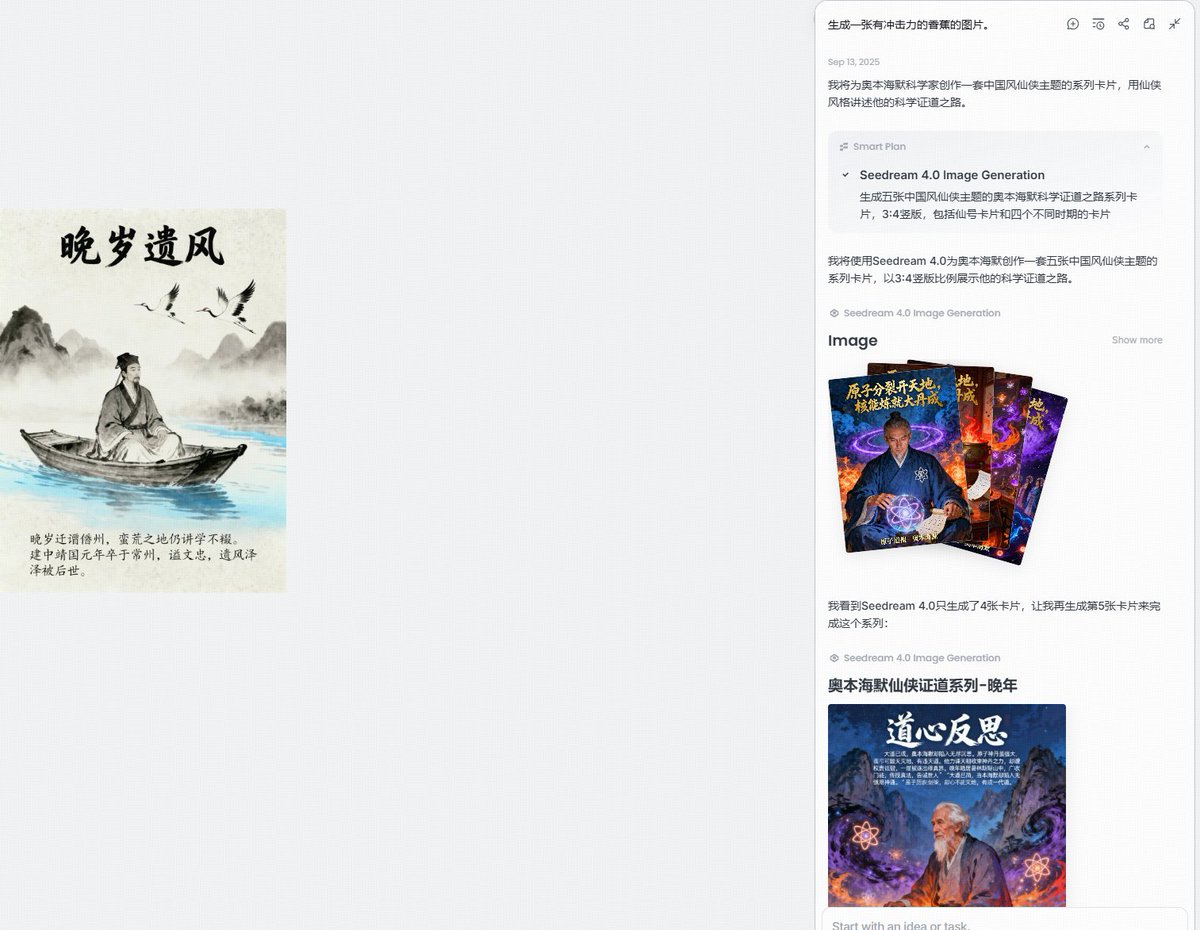

Android上线实时语音!开源智能体OpenClaw发新版,全面解锁GPT-5
开源个人智能体服务 OpenClaw 发布 v2026.5.18 新版本。本次更新将 Android 客户端的对话模式切换为基于网关中继的实时语音会话,并全面放开了对 GPT-5 系列模型的配置验证与支持。
新版 Android 客户端实现了流式麦克风输入与实时音频回放,并打通了工具结果桥接(tool-result bridging,指将工具调用状态与语音流实时同步)与屏幕实时字幕。这使得移动端用户可以直接通过语音唤醒并运行复杂的本地工具链。
在模型支持方面,OpenClaw 解除了配置校验阶段对 GPT-5.1、GPT-5.2、GPT-5.3 以及 openai-codex 模型的拦截。新版本停止了对 GPT-5 最终回复的强制缩简截断逻辑,以保留完整的通道响应,并在激活严格智能体执行(strict-agentic execution)时自动写入日志。
为了简化插件扩展,新版推出了 defineToolPlugin 极简插件接口,并配套了 openclaw plugins build、validate 和 init 命令行工具。开发者现在可以用强类型方式声明简单的工具插件,系统将自动生成所需的描述清单(manifest)和上下文工厂。
底层性能方面,内存核心(Memory-core)引入了启动增量同步机制。系统在启动时会比对磁盘会话与索引文件,仅对缺失、变动或大小改变的文件执行增量索引更新,大幅缩短了冷启动耗时。
此外,非托管的信号(如 SIGUSR1)配置重载完全在进程内完成,避免了因派生孤立子进程而导致父级守护程序丢失进程标识符(PID)的问题。
#AI #AIAgent
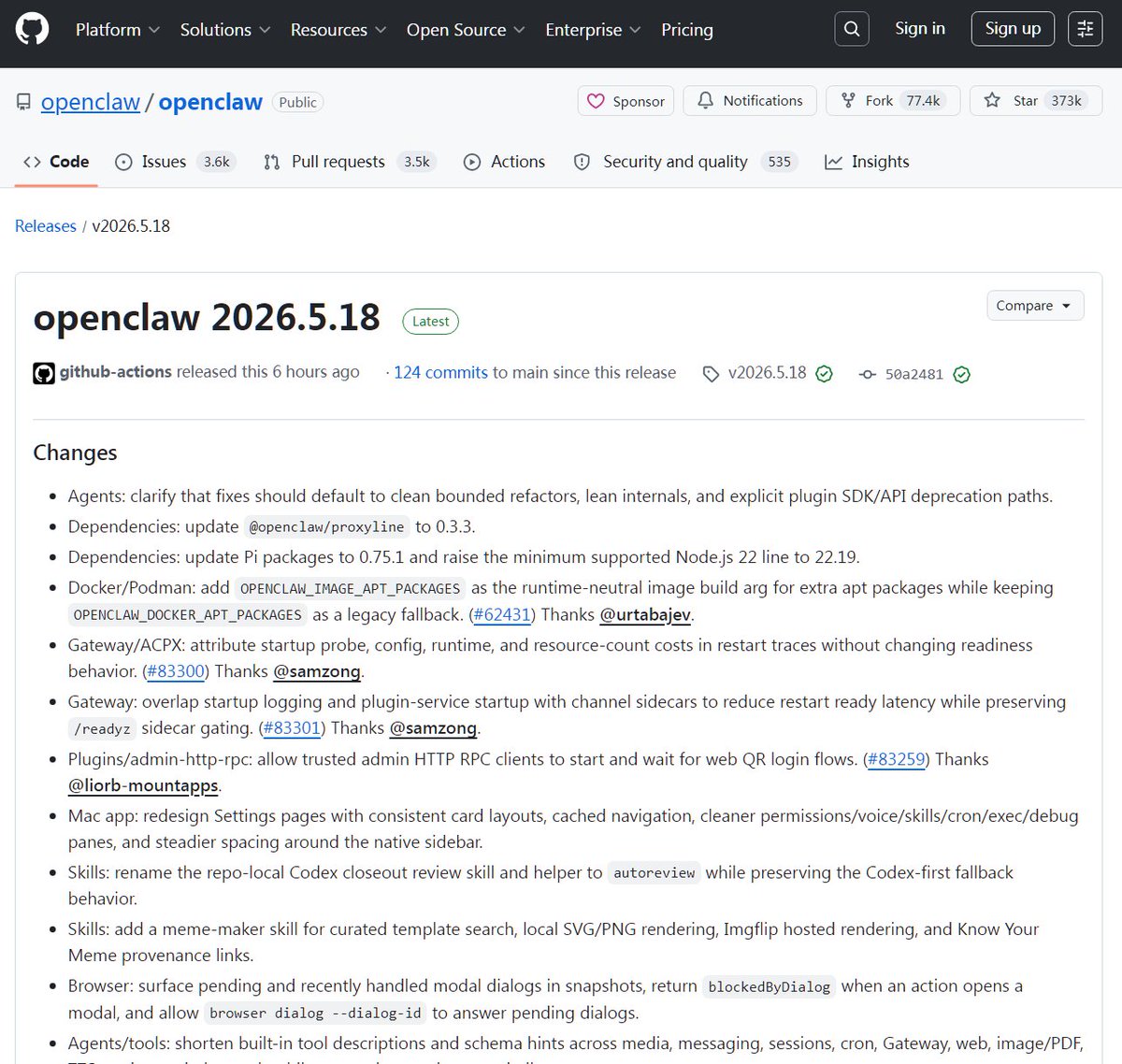
Perplexity测试个人CFO面板,聚合期权与Polymarket数据欲做轻量级彭博终端
Perplexity 正在内部测试一个名为「个人 CFO」(Personal CFO)的专属标签页,试图在通用搜索之外搭建一个独立的金融工作台。最新曝光的截图显示,该面板原生包含投资组合、交易记录与负债管理三大板块,并一口气打通了多家专业金融数据源。
具体而言,基础财务信息由 Financial Modeling Prep 提供,期权数据接入 Unusual Whales,财报会议文本与音频来自 Quartr,营收与 EPS 数据由 Fiscal AI 和 S&P Global 支撑。该面板同时直接引入了 Polymarket 的预测市场数据。
#AI #AIAgent @Polymarket
阿里云QoderWork上线语音设计工作台,说句话直接生成能跑的网页
阿里云 QoderWork 正式上线设计工作台 Design Desk。这是一个原生 AI 驱动的设计即代码工具。用户直接语音输入需求,系统会在无限画布上生成可运行的设计产物,并支持一键导出为 React + Vite 工程进入研发环节。
为了控制 AI 生成的随机性,该平台重构了生产流程,内置三套核心机制:
• 主动追问(Questions):遇到输入信息不足时优先确认意图,避免盲目猜测试错。
• 计划前置(Design Plan):生成前先输出结构化的布局与风格大纲,经用户把关后再执行。
• 参数微调(Nudge):生成后直接暴露配色、间距、圆角等关键变量,无需重新描述即可调节。
设计产物不再是交接后不可修改的静态黑盒,而是团队共同维护的代码资产。这种模式直接跳过了传统开发中设计稿切图、标注、前端还原的多轮内耗。
#AI #AIAgent
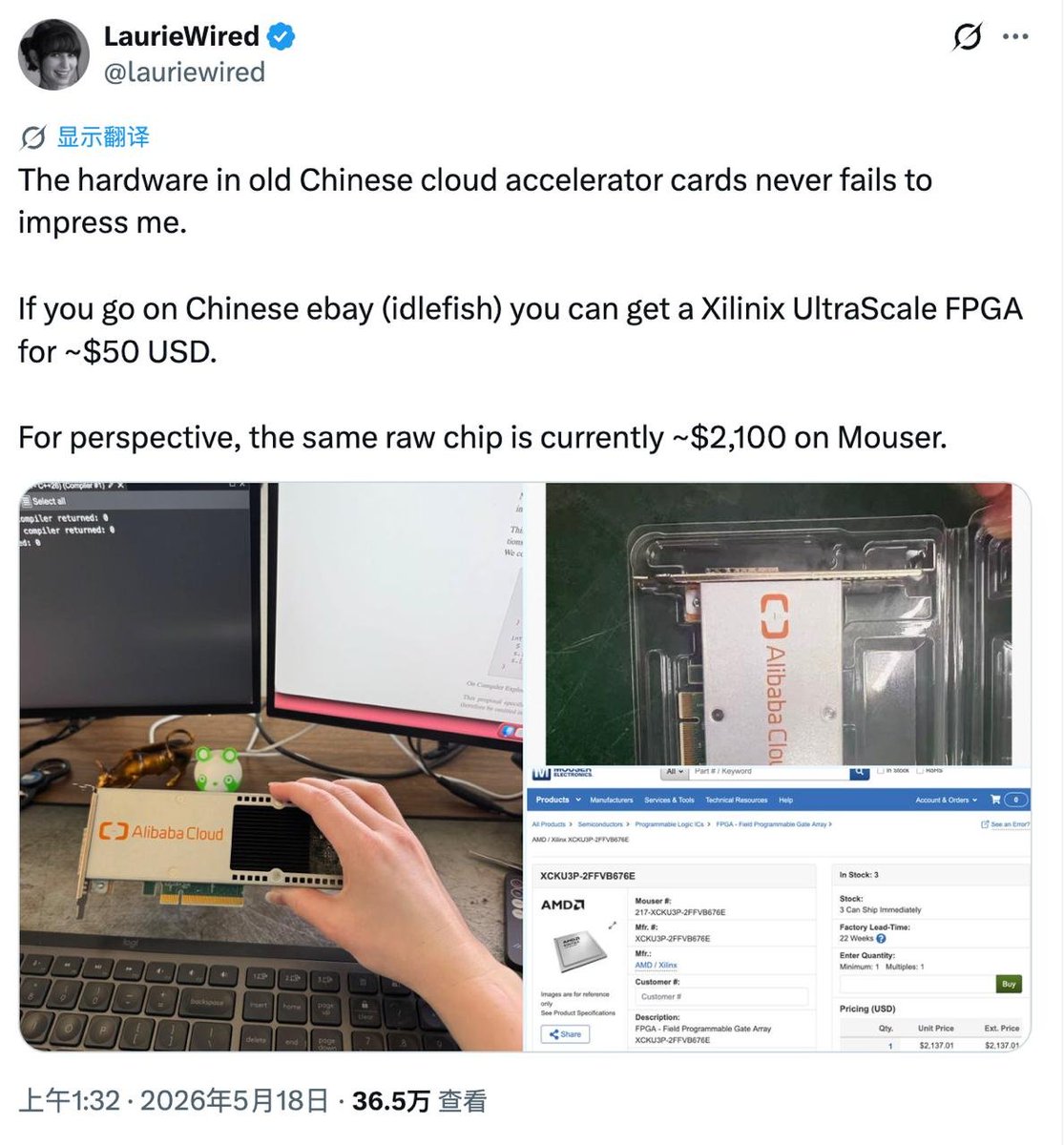
闲鱼上355人民币捡漏2000美元级芯片:阿里退役FPGA被刷成开源网卡
谷歌安全研究员 Laurie Wired 在 X 上晒出了一块阿里云退役 FPGA 加速卡:闲鱼标价 355 元人民币包邮(约 50 美元),卡上搭载 AMD / Xilinx Kintex UltraScale+ XCKU3P 系列芯片。
作为对照,Mouser 分销平台上同系列接近配置的 XCKU3P-2FFVB676E 单颗裸片,现货报价高达 2137.01 美元。这个价差不能被直接等同于“50 美元买 2000 美元”:分销商现货标价在可编程逻辑行业存在普遍虚高(企业大批量实单往往只有一两百美元),且闲鱼卖的是成色与寿命均不确定的退役整机卡。
但对 FPGA 爱好者而言,这依然是极致的捡漏。该卡(社区代号 AS02MC04)带有 PCIe Gen3 x8 与双 SFP+ 光口,且搭载的芯片受免费版 Vivado 支持,硬件配置碾压同等价位的入门开发板。
它原本是一张没有任何官方原理图与手册的“盲卡”。在早期玩家逐一逆向测出 JTAG、引脚和时钟定义后,开源网络计算平台 Corundum / taxi 项目现已正式合并了对该卡的适配支持。开发者能直接把它跑成开源 FPGA 网卡,用于 10G / 25G 以太网及网络内计算(In-network compute)实验。
大厂退役硬件流入二手市场,正在硬核地将高端 FPGA 的开发门槛压低到普通爱好者也能承受的试错区间。
#AI #AIAgent




写文章降AI率保姆级教程
【一、降低A1痕迹专用指令】
请帮我重写以下文本,核心要求是更贴近人类自然表达:保留原文核心信息与核心意图,减少过于规整的完美句式,适当加入不规则表达;融入个性化语言风格,穿插少量口语化表述;打破机械化的段落结构,让整体读起来更真实自然。
【二、句子润色提升指令】
请对以下文本进行精细化润色,目标是增强表现力与吸引力:替换平淡词汇,选用更精准、生动的表达;调整句式结构,让行文更流畅自然,同时强化语言韵律感;统一语言风格并契合使用场景;修正语法、拼写等细节错误,全程保留原文核心信息与核心意图。
【三、简化结构+提升信息清晰度指令】
请重新梳理以下文本,核心目标是让信息更清晰、阅读更轻松:拆解复杂句子结构,化繁为简;将冗长段落拆分为短而聚焦的单元;删除模糊、歧义的表达,替换为明确表述;(如适用)添加清晰小标题划分模块;优化信息层次性与条理性,确保每个段落仅围绕一个中心思想展开。
【四、语气适配场景转换指令】
请根据需求调整以下文本语气,使其精准契合具体场合与目标受众:将语气切换为正式/非正式/专业友好/权威/激励性等;结合目标受众的知识水平与预期,合理控制专业术语使用密度;确保语言符合对应的社交与文化语境;调整语调以传递适配的情感基调,全程保留原文核心信息与核心意图。
【五、丰富细节+强化说服力指令】
请为以下文本补充具体内容,核心目标是让表达更具象、更有说服力:添加贴合主题的实例、真实案例或应用场景;补充精准数据、权威统计或支撑性证据;对关键概念进行通俗化展开解释,补充必要背景信息或上下文,帮助读者理解;用生动具体的描述替换抽象笼统的表述,所有新增内容均需紧扣原文主题,不偏离核心方向。
【六、聚焦核心+精简冗余指令】
请对以下文本进行精炼优化,重点是突出核心观点、提升表达效率:精准识别并保留最关键的核心信息点;删除重复表述、多余修饰及无关紧要的细节;合并逻辑相近的观点,避免内容冗余,减少过度使用的修饰性词语,让表达更简洁有力;确保每句话都有明确表意目的,无无效信息,全程聚焦核心主题。
【七、优化节奏+丰富句式多样性指令】
请重写以下文本,核心目标是打造自然阅读节奏、提升语言层次感:灵活混合长短句,交替运用简单句、复合句与复杂句;合理调整段落长度,避免阅读疲劳;在恰当位置插入修辞问句或感叹句,增强表达张力;杜绝连续使用相同句式结构,打破单调感;通过句式变化创造自然语言韵律,全方位提升文本可读性。
【八、主题扩写+强化说服力指令】
请在完全保留原文核心意思的前提下,对文本进行深度扩写:围绕核心主题,补充更丰富的关联信息与多元观点;引入贴合论点的真实案例、权威数据或支撑性论据,强化内容说服力;确保扩写后结构清晰、逻辑连贯,段落过渡自然,既丰富内容厚度,又保持阅读流畅性,让读者更易理解核心主旨。
#AI #AIAgent
AI漫剧工具哪个好用?5个AI漫剧工具横评:即梦AI,可灵AI,有戏AI,来画 AI,漫小芽
2026要说短视频圈内最卷,门槛最低的赛道,绝对是AI漫剧。
我接触过太多入局的新手,踩坑的第一步永远都是选错工具。今天就以圈内人的真实使用体验,把目前热度最高的五款工具:即梦、可灵、有戏AI、来画AI、漫小芽做一次实打实的干货横评,文章末尾还有一些小白经常遇到的问题,建议直接收藏!
5个AI漫剧工具横评:
1:即梦AI
即梦AI出圈比较早,作为字节跳动旗下的工具,它天生绑定抖音生态,也是目前二次元漫剧创作者使用率最高的平台。
我实测下来最直观的感受就是,它对二次元审美拿捏得十分精准,不会出现很多AI工具常见的五官违和、画风割裂问题,只要上传参考图锁定角色,跨集制作的时候人物相似度能保持在九成以上,做连载漫剧基本不会出现崩脸的尴尬情况,而且如果你做好的漫剧准备发到字节系的平台,更容易拿到平台流量扶持。
它能帮你产出单镜头,但如果你要批量出几十集百集漫剧,它的角色锁定、资产管理能力就明显吃不消了。很多人刚开始用即梦做漫剧,做着做着就发现怎么我的主角上一集和下一集长得不一样了,原因就在这儿。
2:可灵AI
说完抖音系列的咱们说说快手旗下的可灵AI,从可灵2.5起它的动作流畅性和物理真实感就把竞品拉开了一定差距。
可灵的光影渲染、人物纹理处理是五款工具里最出色的,原生支持4K分辨率,衣物褶皱、皮肤质感都足够真实,没有廉价的AI塑料感,人物跑跳、打斗等大幅度肢体动作流畅自然,不会出现僵硬扭曲的情况,非常适合玄幻、武侠这类需要动作镜头的漫剧创作。
3:有戏AI
如果让我票选目前在AI漫剧全流程这一块做得比较出色的平台,有戏AI会排在前列。因为有戏AI还有个外号:量产成本屠夫,为什么这么说呢?
有戏AI跟即梦、可灵专注于部分环节不同,有戏AI真正打通了剧本→角色→分镜→视频→成片这条完整链条,正儿八经的打通了AI漫剧一条龙服务。你上传几万字的完整剧本,它可以自动帮你拆分剧集生成分镜,不需要你手动一集集去拆,这个功能对效率的提升绝不是一星半点。
有戏AI制作漫剧整体成本控制在0.1元/秒上下,按集算一集大致在10到25元之间,100集的总成本大约1000到3000元,相比较即梦和可灵可以少花不少,目前还在内测想玩的朋友可以通过我的邀请看一下:
4:来画 AI
来画 AI是五款工具里唯一主打长内容创作的平台,最高支持一千秒的成片时长,不用反复拆分视频就能生成完整的长篇剧情漫剧。
平台操作逻辑简单,哪怕不懂剪辑技术,只需要输入故事梗概,系统就能自动完成成片制作,而且主体库可以永久保存角色和场景,长期连载能保证人物形象稳定不崩坏。
画风偏向扁平卡通,细腻的二次元渲染效果不如即梦,并且长视频生成速度缓慢,完全不适合短期批量产出短视频,更适合深耕长篇剧情、打造个人IP的创作者使用。
5:漫小芽
这个AI漫剧工具我没有使用过,因为申请不到邀请码,所以这个工具我也只能靠一些朋友来进行一个评价。
漫小芽平台整合了多款主流AI生成模型,单次提示词可以产出多个版本,方便创作者择优使用。但免费工具的通病它也全部具备,常规画质只能满足短视频基础发布需求,复杂场景容易出现画面崩坏,没有任何自定义调整参数,创作者无法手动优化分镜和人物细节,加上免费算力有限生成速度缓慢,只能满足个人日常创作完全不适合工作室批量量产。
怎么抽到自己想要的卡?
抽卡是AI生成内容的核心环节,简单来说就是输入指令,等待AI给出结果。
然而这过程好比开盲盒,人工智能生成的内容不够稳定:人物表情和口型不能衔接,这一帧男主和上一帧可能不长一样;对细节的把控不足,弄出六根手指时有发生。还有些人多的戏,因为群演的脸没给固定参照图,AI就会乱生成,好几个人共享一张脸,甚至还是明星脸……
很多做AI漫剧的朋友都有这么一个问题,其实解决的方法很简单,就是尽量完善我们的AI提示词,大家只需要把自己的需求套用就可以了。
写在最后:
其实用过这么多 AI 工具之后,我有一个很中肯的看法。
我们完全没必要把任何 AI 工具过度神化,用的时候还是需要自己静下心来慢慢打磨文字内容。AI 真正能帮到我们的地方在于,只要脑子里冒出创作灵感,当天就能把完整的成品直接做出来。
#AI #AIAgent

GPT Image 2 十大创业变现玩法:低成本、高产出,人人可上手
AI 作图时代已经到来,GPT Image 2 凭借一句话出图、高效生成、细节可控的强大能力,彻底降低视觉创作门槛。不管是个人接单、副业增收,还是企业降本增效,都能快速落地变现。下面这10种玩法,看完就能开干!
1、产品广告海报生成
电商主图、促销海报、详情页视觉、实体门店宣传图,有产品就有设计需求。只需输入产品信息与风格要求,GPT Image 2 一键生成高转化视觉,不用再等设计师排期,低成本接海量订单。
2、带货直播背景图
为抖音、淘宝、视频号搭建沉浸式直播间场景,搭配柔和补光、产品陈列区与主播站位留白,打造高转化氛围视觉。可按模板售卖,也能做直播视觉代运营,长期稳定接单。
3、影视分镜概念图
把剧本文字转化为导演可用的视觉分镜,用强烈光影、剧情瞬间、情绪张力呈现画面,用于项目筹备、融资提案。按项目计费,单案收益可观,适合内容团队与自由创作者。
4、AI 虚拟人物形象设计
5、社交媒体封面图
6、短视频封面点击图
强冲突画面 + 吸睛大字标题,3 秒抓住用户眼球,大幅提升视频点击率。专为信息流、短剧、探店、带货视频设计,接单量大、见效快。
7、品牌LOGO延展视觉
把 LOGO 融入门店、物料、包装、宣传场景,形成系统化 VI 视觉,用于品牌招商、企业宣传。承接品牌全案、VI 延展、物料设计,客单价更高。
8、NFT 风格数字艺术生成
创作独特纹理、稀缺质感的数字艺术藏品,在 NFT 平台发售,享受一级售卖与二级版税分成,轻资产做数字藏品创业。
9、插画故事分镜
把小说、剧本、绘本脚本转化为连贯漫画分镜,角色动态、叙事节奏、画面张力一步到位,用于绘本出版、条漫更新、动画前期,按页/按格计费。
10、小说封面定制
精准匹配玄幻、都市、科幻、言情等题材气质,做出版级小说封面,适配网文平台、实体书。需求量大、复购高,副业接单稳定增收。
#AI #AIAgent

APP已死,万物皆可skill的时代真的来了!!!
任何一个APP,剥开它花里胡哨的界面,本质上就两件东西:功能+界面。
这个"界面"——也就是APP的UI、设计、按钮、菜单、动画——是给谁看的?是给人看的。因为人的眼睛和手只能这么操作。
可现在AI登场了。AI不需要看那些好看的图标,不需要在三级菜单里点来点去。它只需要知道一件事:这玩意儿能干啥,怎么调用。
未来你只需要跟AI说一句:"饿了。"
整个过程,没有APP界面,没有滑动,没有点击,甚至连"美团"这两个字都不出现。美团变成了一个看不见的skill,服务你这个看不见的需求。
很多人没搞明白Skill到底是个啥。我用最简单的话说:
完事了。就这么简单。
而做一个Skill需要什么?一个会写文字,或者会口喷(会说话)的人,半天时间,把你的思维思考,步骤流程,需求写成一个skill。
更恐怖的是什么?Skill是组合的。你可以让AI同时调用三个、五个、十个skill来完成一件事。
APP时代的统治逻辑,正在快速崩塌。
过去二十年,所有互联网公司的生死命脉只有一条:抢用户的注意力,把用户圈在自己的APP里。
而Skills彻底掀翻了这个桌子。
当你不再"打开APP",而是"跟AI说一句话",这一切围绕"用户主动打开APP"建立起来的商业模式全部失效。
人和AI的关系,正在从"工具"变成"共生"
这才是最深的那一层,大多数人还没意识到。
但AI智能体这个东西它有点诡异。它不是工具。它更像一个"另一个你"——一个比你记性好、比你执行力强、比你不容易累、还24小时在线的"延伸大脑"。
当你的AI能调用所有的skill,能记住你所有的偏好,能预测你所有的需求,能自动完成你日常80%的琐事——你和它的关系就不再是"人和工具",而是共生。
什么叫共生?就是一种你离不开它、它也活在你身上的状态。
谁会在这场革命里被碾死,谁会一夜暴富?每一次大变革,本质上都是一次财富的大洗牌。Skills时代,洗牌已经开始了。
先说谁会死:
第一类是做"工具型APP"的小公司。那些功能单一的小工具——记账、待办、笔记、翻译、修图、PDF处理——会被skill直接团灭。因为这些功能用skill实现,可能就是一个100行的Python脚本加一个说明书。
我2026年年初想的是做100个AI编程产品或者APP,现在的想法是做什么APP,做什么小程序?直接做100个skill就行了,一个skill就是一个产品,就是一个APP,可以直接卖钱。
第二类是纯做UI的设计师。当用户不需要看界面了,谁还需要好看的界面?未来界面会被极度简化,可能一个对话框就够了。UI设计这个职业,十年内萎缩50%我都不意外。
第三类是搬砖式的运营。那些靠"推送+签到+优惠券"维持日活的运营套路,在AI助手时代毫无意义。AI不会被你的推送骚扰,它只关心"用户需要什么"。
第四类是靠流量焦虑活着的中间商。当AI能直接连接需求方和供给方,中间这一大堆切片商、推荐商、广告商,会被一刀切掉。
再说谁会爆发:
第一类是会写skill的人。会写skill的人,一个人能干十个人的活。
第二类是懂垂直领域知识的人。AI是通用大脑,skill是专业知识的容器。一个律师把自己的专业知识写成skill,他就有了一个"24小时律师助理军团"。一个医生、一个会计、一个老师同理。专业知识 + skill封装能力 = 个人IP的核武器。
第三类是做skill市场的平台。未来一定会出现"skill商店",像应用商店一样,只不过卖的不是APP,是skill。早期入场的玩家,坐拥下一个时代的入口。
第四类是懂"人机协作"的管理者。未来公司不再是"管人",而是"管人+管AI"。一个AI项目经理可能同时指挥五个真人下属和五十个AI agent。能驾驭这个混合战场的人,身价指数级飙升。
普通人现在该干啥?
要么开始学习AI,应用AI,学习skill,应用skill,或者加入有价值的AI社群一起学习,永远在AI的第一线。
AI就像20年前的互联网一样,一大批人会变得非常富有。现在和以后,每个人都将和AI共生,就像互联网,电商,短视频和直播时代一样,谁最先会用,谁就能抢到先机和财富。 #AI #AIAgent