


昨天某机构对智谱AI做了专家访谈,现整理内容如下,干货很多,值得详细阅读:
1/ 智谱AI在 GLM-5 发布后,其 Agent 和 Coding 能力显著进步的原因是什么?
智谱公司的 Agent 和 Coding 能力从 GLM-4.5 开始就一直很强,至少是业界最强之一。公司能够保证模型在发布时达到业界领先水平,尽管后续可能会被其他新发布的模型追赶。关于技术演进,可以参考 GLM-4.5 和 GLM-5 的两份技术报告。在 GLM-4.5 阶段,公司确立了 ARC 战略,即 Agentic、Reasoning 和 Coding 三个方向。当时公司对这三个方向的未来重要性并不完全确定,因此同时进行了投入。随着发展,公司发现 Reasoning 的直接经济价值有限,而 Agentic 在很长一段时间内未能找到合适的应用场景,因此逐渐与 Coding 融合。在 2025 年下半年,公司的主要方向是 Agentic Coding,并与 Claude code 等产品结合。公司在 GLM-4.5 期间,具体于 2025 年 9 月 1 日,率先推出了 Coding plan,这一技术在 GLM-4.6 版本中得到进一步发展,并在 GLM-4.7 版本中发挥到极致。因此,公司在业界的口碑在 GLM-4.7 发布时已达到一个高峰,但这也基本耗尽了当时的算力资源,为 2026 年的发展埋下了伏笔。进入 2026 年,GLM-5 和 GLM-5.1 等 4.x 系列的模型尺寸较大,其相对实力也更强。
2/ 从 GLM-4.5 到 5.x 系列,模型迭代速度很快,这主要得益于哪些因素,例如推理能力的提升、训练范式的优化,还是专家系统的改进?
模型的迭代速度并没有必然加快。许多被外界视为迭代的发布,实际上是多条研发线路并行推进的结果,并非在一个模型完成后再开始下一个。例如,GLM-5 的训练在 GLM-4.7 尚未退役时就已经开始。因此,一个月或一个多月发布一代模型,不代表训练周期就是一个月。模型团队花费最长的时间是在“观察”上。公司的强项在于抓住市场机会的能力,通过深入观察市场风向、评测结果,判断哪些模型表现稳固、哪个技术方向代表未来趋势,从而在研发上少走弯路。
当前智谱最先进的模型水平比较接近 Claude 的 4.6 版本,但存在明显短板,例如缺乏多模态能力。因此,可以将其视为一个稍弱化的 Sonnet 4.6 版本。如果从 benchmark 评测分数来看,差距大约是 4 个月;但如果从底层技术的扎实程度来看,差距可能在 6 个月左右。
3/ 业界普遍存在模型蒸馏的现象,近期 Anthropic 等公司也加强了管控。公司如何应对日益严格的监管环境?
首先,蒸馏在模型整体能力中的占比正在持续降低。蒸馏的关键作用并非赋予模型当前的核心能力,而更多是使其在 Code 或 Coding Agent 等场景下的表现风格与 Claude 等顶尖模型相似。当前业界模型能力的提升,如 DeepSeek 等,主要还是依靠其自身的架构创新、预训练以及强化学习。例如,公司发布的 SFT-Bench Pro 能取得 SOTA 成绩,主要归功于强化学习。其次,应对监管方面,这取决于产业链中是否有合作方愿意提供帮助。这类操作通常不是由模型公司直接进行,而是通过第三方执行,这背后存在利益驱动。
4/ 与 2025 年相比,公司当前的算力分配策略有何变化?训练和推理的算力占比分别是多少?
算力的分配比例变动非常剧烈,没有固定的比例。例如,像 DeepSeek 那样的新架构出现,可以将 FLOPs 降低至原先的十分之一,这将显著减轻推理端的算力压力,从而可以将更多资源重新分配给训练。在没有技术架构创新的情况下,只能依靠增加资源来满足用户需求;而技术突破后,则可以回收资源。公司长期处于供不应求的状态,因此算力分配更多是按比例划分给不同的大客户,核心在于保证对大客户的资源承诺。
5/ 考虑到模型能力是公司的核心竞争力,未来用于训练的算力比重是否会下降?
预计不会下降,反而可能会投入更多资源,因为市场和资本对 AI 公司的估值主要基于其产品能力和技术领先性,而非短期财务指标。持续推出领先的大模型是根本,这需要遵循 Scaling Law,即通过扩大规模来训练更大、更多的模型。因此,用于训练的算力是公司的生命线,其投入是刚性的,不太可能削减。
6/ 公司目前训练和推理算力的分配模式是怎样的?如何管理训练任务对稳定算力资源的需求与推理任务的潮汐波动之间的矛盾?
训练和推理的算力很难完全拆分。公司采用潮汐调度等技术,将算力资源池化管理。推理负载并非每时每刻都处于峰值,在凌晨等低谷期,空闲的算力会被调度给训练任务。虽然训练任务需要长期稳定的算力,但目前的集群挂起和启动技术已经比较成熟,一个集群的启停过程大约只需要半小时。夜间的闲时算力窗口通常有 8 到 10 个小时,足以被高效利用。这种模式优先保障线上服务,服务空闲的资源则全部投入训练,从而提升了整体架构的运行效率。
7/ 对于未来的算力规划,是倾向于第三方租赁,还是自行采购国产推理芯片?考虑到技术迭代速度快,需求预测难度大,公司在算力储备上是倾向于提前进行强预判式准备,还是在需求出现时临时从市场获取?
算力的规划和储备策略本质上是一种多方博弈,很难进行精确预测。这与厂商选择开源还是闭源路线的博弈相似,都取决于对未来的判断和赌注。具体到算力,核心的博弈在于选择相信技术创新的动能还是遵循现有技术路径。如果更相信技术创新,那么资源会更多地投入到人才储备,例如在 Training Team 和 Infra Team 之间进行调配,更偏向于通过 Infra Team 的努力来提升训练效率,从而弥补算力不足。反之,如果判断技术不会有重大突破,大家都会沿用现有方式,那么最理性的选择就是囤积计算卡。作为一家初创公司,智谱更倾向于相信技术的力量,因为与资金雄厚的大厂相比,智谱无法在囤积算力上进行竞争。
8/ 在保持低成本运营的同时,如何确保模型智能水平的持续提升?从国内竞争格局来看,DeepSeek、Kimi、智谱AI 等几家主要厂商在模型能力,特别是在 Coding 和 Agent 技术实力上,应如何排序和评价?
在模型能力上,DeepSeek、Kimi 和智谱 AI 可以算作第一梯队,各有特色。通常模型参数量越大,其世界知识就越强,在这一点上 DeepSeek 和 Kimi 的模型优于智谱 AI。然而,智谱 AI 的传统优势在于其模型与 Coding 及 Agent 能力的深度结合,在代码相关的应用场景中表现最强。而在前端体验和审美方面,DeepSeek 和 Kimi 可能稍好一些。第四名是小米的 MiMo,但它与前三者存在一个档次的差距,可以看作是第二梯队的领头羊。千问、混元等模型则处于其后。
然而,单纯的模型表现与团队的技术实力并非完全等同,尤其是在 Coding 领域。如果抛开模型大小的因素,仅从对特定场景的钻研深度和数据储备来看,智谱 AI 在 Coding 技术上是独一档的。此外,MiniMax 也应被归入第二梯队,其模型绝对能力不佳主要是因为模型尺寸过小,但这并不完全反映其技术团队的实力。当评估团队实力时,需要对模型尺寸进行加权考量,能够以小模型实现与大模型相近性能的团队,其技术实力应得到更多认可,因为他们后续推出更大尺寸、表现更优异的模型的可能性也更高。
9/ 中国大模型厂商在出海方面面临哪些挑战?
中国大模型厂商出海面临规模化的巨大困难。当收入规模达到 10 亿以上时,会直接面对持有美国许可证的供应商,这些供应商拥有充足的算力资源,如 B 卡,和政府关系优势。大模型作为一项涉及政治敏感性的技术,使得海外大型机构客户在采用时非常谨慎。例如,阿里云的海外总部设在新加坡,其公有云服务可以覆盖散户,但服务大型机构时仍会遇到障碍。这与一些海外云服务在中国难以被机构采用的情况类似。对于开源模型,海外大客户可能会使用其进行评估、know-how,但不会将其用于核心业务,这使得模型提供商难以直接通过出海盈利,更多是作为一种间接的品牌建设行为,以提升在国内的口碑。MiniMax 其业务增长主要仍来自国内市场。
10/ 如何评价 DeepSeek 近期的低价策略及其商业模式的可持续性?其他厂商为何难以复制?
DeepSeek 的低价策略源于其独特的商业模式和路径,其他厂商已无法模仿。DeepSeek 是一家纯粹的 to C 企业,其商业模式有几个特点:首先,它不维护旧版本模型,例如会直接淘汰 V3.1、V3.2 等旧版本,这极大地提升了资源管理效率。其次,它不提供面向 to B 业务的 SLA,也就是服务等级协议,和稳定性保障。相比之下,智谱 AI 等作为商业服务机构,无法瞬间关停上一代模型以迁移用户,必须为企业客户保留旧版本模型。因此,尽管其他厂商可能认同 DeepSeek 模式在毛利上的潜力,但由于自身商业定位的不同而无法采纳。
11/ 从商业模式角度看,to B 和 to C 哪条路径更优?DeepSeek 是否在追求盈利?
DeepSeek 正在以一个独立商业主体的身份非常深入地思考其发展路径,其所有商业行为均以自身盈利为目标,与其他商业主体无关,并非一个不计成本的“玩具”。其选择的 to C 路径,如果能成功走通,长期来看理论收入可能会更高,因为它无需依赖渠道或合作伙伴,也不必提供大量折扣,只需管理好自身资源。然而,这种模式的抗风险能力较低,容易受到其他更具性价比的竞争对手的冲击。目前海外市场短期内 to B 模式表现更顺畅,商业化自动化程度高,客单价也高。相比之下,OpenAI 的 to C 业务虽然用户基数大,但月度订阅费,如 20 美元,增长缓慢,爆发力稍显不足。
12/ 豆包在 to C 市场的用户规模是否意味着阶段性战役已经结束?AI 行业的 to C 模式与传统互联网有何不同?
尽管豆包在 2026 年春节后的第一季度用户数增长显著,呈现一边倒的态势,但这并不意味着 to C 市场的战役已经结束,甚至可以说战争尚未开始。当前所有厂商都未进入收费阶段,尚未形成经济正循环,仍处于准备阶段的“军备竞赛”。豆包凭借字节跳动在 to C 领域的深刻理解,产品黏性做得很好。然而,AI 行业与传统互联网存在根本不同,它没有规模效应。用户越多,单位服务成本反而可能越高,因为集群规模变大导致网络通信更复杂,GPU 优化也更困难。因此,在“军备竞赛”中领先的赢家,在战争真正打响,也就是开始收费时,也可能因为高昂的成本而亏损最快。
目前字节跳动内部可能还未进入到不同业务单元为争夺 AI 资源而激烈竞争的阶段,或者说尚未到迫使高层必须立即做出决策的时刻。字节跳动倾向于一种去中心化的组织模式,相信各业务区块的自身优化能带来全局提升。但随着业务发展,资源分配问题将变得现实。例如,当计算资源有限时,公司内部会面临权衡:是将稀缺的算力资源投入到毛利率更高的业务,还是免费服务于尚不盈利的 to C 用户。
13/ 在面对强大的竞争对手时,应采取何种策略?如何看待当前 AI 行业的竞争格局和未来发展?
在当前竞争格局下,应采取差异化路线。行业内的领先地位是交替变化的,例如在国外,最初各家方向发散,但在 coding 领域实现闭环后,其他竞争者也迅速跟进。谷歌等巨头仍有强大的追赶潜力。当前 AI 行业正处在一个激动人心的大时代,但各家厂商的优缺点都非常明显,制约点也很多,即便是业内人士也难以预测“5 月 1 日”之后行业会发生什么。整个行业的发展路径并非按预定计划进行,一个微小的观察或事件都可能导致公司放弃原有方向、调整战略,这种变化每天都在发生。
14/ 如何看待未来国产推理芯片的应用前景,例如华为昇腾系列?公司是否有意愿采购?
国产芯片如昇腾 910B,其对标的是英伟达的 H200,主要作用是弥补 H200 在中国市场的缺位,但它无法替代英伟达 Blackwell 系列,也就是 B 系列芯片。B 系列芯片在推理性能上有显著优势,其能力上限非常高。例如,使用 H 系列芯片推理智谱 AI 这类模型,速度很难超过每秒 50 个 token,而 B 系列芯片推理 DeepSeek 的 FP4 模型可以达到每秒 150 个 token。因此,是否采购国产芯片取决于未来市场对何种类型算力的具体需求。如果应用场景对推理性能和吞吐量极为敏感,B 系列芯片仍是首选。
15/ 海外市场对模型推理速度的敏感度与国内有何不同?
海外市场用户对速度的敏感度远高于国内用户,中国用户可以接受的响应速度在海外市场可能被认为是无法忍受的。这主要是由硬件差距造成的,海外主流厂商已经开始采用 B300 级别的芯片,这不仅带来了更低的时延,单位时间的 token 输出量也高出数倍。综合来看,性能差距非常显著,不同地区用户的敏感度也截然不同。

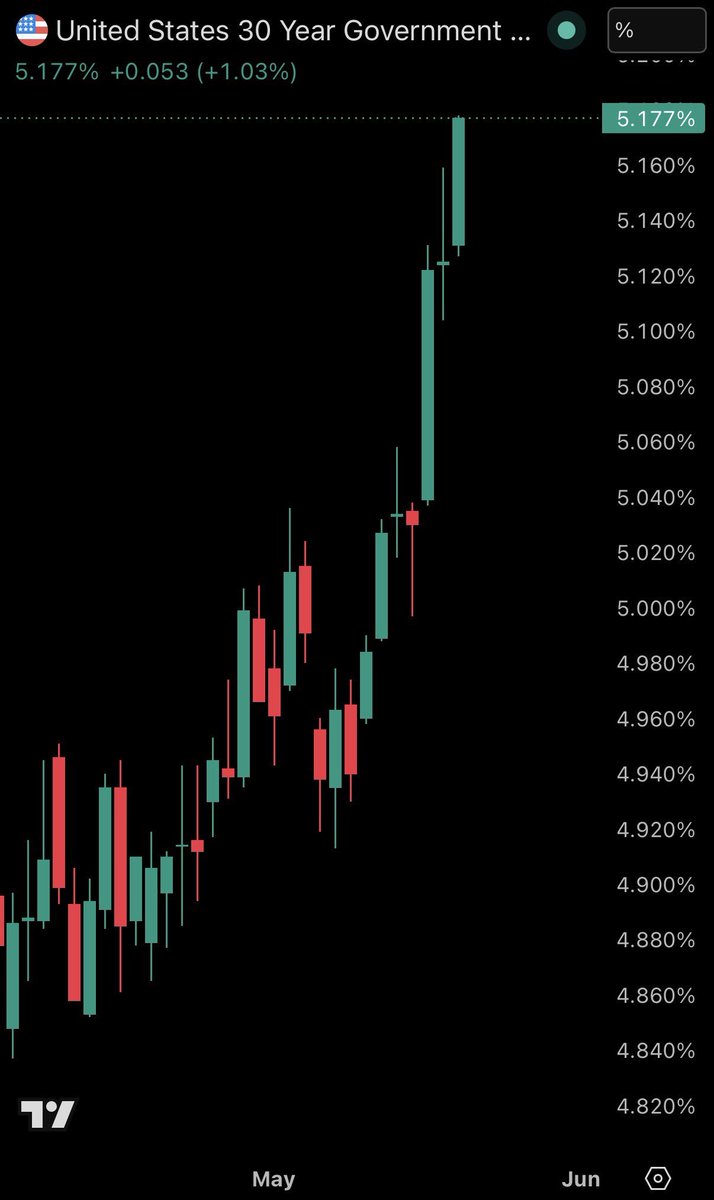
英伟达明天520公布财报,这可能又是一份好业绩,但市场会为好成绩买单吗?
过去几个季度,英伟达财报的主线信号非常统一且明确,就是AI 需求强,数据中心收入强,Blackwell 放量强。
但到了这次财报,市场已经不满足于简单的超预期了。真正的问题是,英伟达能不能继续把 2027 年和 2028 年的收入、EPS、毛利率和现金回报模型继续提升。
从 Citi、UBS、大摩、Jefferies 和美银五家报告看,核心共识是一直的:英伟达大概率继续 beat and raise。
但分歧在于,这次上修到底来自哪里?
第一,最直接的看点是收入和下一季指引。
Citi 和 UBS 都给出了比较明确的短期数字。Citi 预计 Apr-Q 收入约 800 亿美元,高于 Street 约 786 亿美元;Jul-Q 收入约 887-890 亿美元,高于 Street 约 866-870 亿美元。UBS 的判断更偏强,认为 F1Q 收入约 806-810 亿美元,July 指引至少应该接近 900-910 亿美元。
Jefferies 和大摩把这个门槛讲得更直接:卖方共识已经不是核心,买方预期才是核心。Jefferies 认为 July guide 的市场门槛已经升到 900-920 亿美元。换句话说,如果英伟达只是略高于 Street,但没有明显超过买方门槛,财报后股价未必会有特别舒服的反应。
第二,B300 和 1.6T 光互连是短期上修的关键证据。
Citi 的报告最适合解释“这一季高在哪里”。它把短期弹性放在两个供应链信号上:B300 爬坡强于预期,以及 1.6T transceiver 出货快于预期。
这件事的重点不只是光模块。1.6T 出货加速意味着整套 AI 集群交付更顺,B300、Blackwell 平台和数据中心系统收入更容易超预期。如果英伟达在电话会里继续确认 B300 需求和交付节奏,市场会把它理解成 AI capex、GPU、networking 和供应链共同上修。
第三,Rubin 是中期模型的关键变量。
UBS 和大摩都重点讨论 Rubin。市场担心的是,Rubin 是否因为机柜级散热、compute board、rack mass production 等问题影响 2026 下半年到 2027 年收入衔接。
UBS 的判断相对温和:Rubin 芯片和 compute board 生产仍按计划启动,机柜级散热微调可能让 rack mass production 推到 9 月或 10 月,但这更像一两个月的时点问题。大摩也强调 Blackwell+Rubin 收入路径,并把 CY26-CY27 收入估算上调到约 8840 亿美元,高于共识约 7850 亿美元。
所以财报电话会里,Rubin 的措辞非常关键。如果管理层把它描述成正常工程优化,市场可能接受;如果变成季度级别延后,2027 年模型上修逻辑就会受到压力。
第四,毛利率和 HBM 成本转嫁会决定收入上修能不能变成 EPS 上修。
大摩和美银都提醒毛利率压力。HBM 成本提高、先进封装、系统级 BOM、Rubin 新架构 ramp,都可能影响未来毛利率。Jefferies 则更关注 HBM pass-through,也就是英伟达能否把 HBM 成本上涨顺利转嫁给客户。
英伟达未来卖的不仅仅是 GPU,更是把一套完整的 AI 系统卖给客户。如果公司能把 HBM、网络、系统集成成本通过平台定价权转嫁出去,市场会继续认可它的系统级利润率。如果毛利率下行快于预期,收入上修未必完全转化成 EPS 上修。
第五,现金回报会变成新的估值锚。
UBS 和 Jefferies 都提到回购和自由现金流。UBS 预计英伟达本年自由现金流约 1900 亿美元,并认为更大的回购授权或分红承诺可能成为积极信号。
当英伟达已经是全球最大市值公司之一,单纯依赖估值倍数扩张越来越难。未来市场会越来越关注现金流、回购、分红和长期 EPS 可见度。如果管理层在财报中释放更强现金回报信号,股价的估值锚会更稳。
第六,美银把这次财报放进了更大的 AI 数据中心 TAM 框架。
BofA 把 2030 年 AI 数据中心系统 TAM 上修到约 1.7 万亿美元,其中 AI accelerator 约 1.2 万亿美元,AI networking 约 3160 亿美元。这个框架的含义是,英伟达财报不仅是在验证一个季度,也是在验证 AI compute、networking、memory、storage 这条基础设施链条是否继续扩张。
这也是为什么英伟达财报会影响整个 AI 半导体链:不仅是 NVDA,市场还会重新定价 AVGO、MRVL、AMD、MU、光模块、HBM、先进封装和电源管理等方向。
我的财报前瞻判断:
这次英伟达财报最理想的组合是三件事同时成立。
第一,July guide 接近或高于 900-920 亿美元,证明 Blackwell/B300 仍在加速。
第二,Rubin 时间线可控,管理层确认芯片、compute board 和机柜级量产只是正常工程节奏,没有扩大成季度级延后。
第三,毛利率没有明显失守,同时 HBM 成本转嫁、自由现金流和回购给出更强支撑。
如果这三点都成立,财报后的主线会从“本季继续超预期”升级为“2027-2028 年盈利模型继续重写”。这对英伟达估值是最强支撑。
如果只满足其中一两点,股价可能仍然不弱,但高位震荡概率会更高。比如收入指引很好但毛利率压力大,市场会担心系统级 BOM 侵蚀利润;Rubin 时间线稳定但现金回报没有新增信号,估值锚会弱一些;中国市场如果只有新闻但没有订单转化,也只能作为上行期权。


一个企业26 年一季度的利润,就是去年全年利润的接近 20 倍。
这就是长鑫存储,DRAM存储界三大龙头(美光、三星、海力士)之后的全球第四把交椅,也是中国市场向先进制程突围的希望。
长鑫存储今天更新IPO招股书:2026年第一季度实现营收508亿元人民币,同比增长719%,净利润达到330亿元。
AI基础设施建设带来的HBM需求激增,导致三大国际原厂将大量产能从传统DRAM转向HBM生产,进而造成DDR4、DDR5等通用型DRAM的严重短缺。2026年第一季度,DRAM合约价格相比上一季度暴涨了58%至63%。
在全球DRAM市场被三星(36.6%)、SK海力士(32.9%)和美光(22.9%)三大巨头垄断的格局中,长鑫存储以4.7%的市场份额位居全球第四。
本轮存储超级周期最显著的特征不仅是营收的增长,更是盈利能力达到了历史性的高度。SK海力士营业利润率72%、美光毛利率75%+,2026年第一季度,长鑫存储营业利润率约65%,这一水平虽然略低于SK海力士和美光,但考虑到长鑫存储目前的产品组合中尚不包含高利润的HBM产品,且制程成本相对较高,这一盈利水平已经相当可观。
HBM是长鑫存储与国际巨头之间技术差距最大的领域。截至2026年,SK海力士和三星已经开始量产HBM4,美光也在加速HBM4的量产进程。
相比之下,长鑫存储在HBM领域基本处于空白状态,公司目前的量产产品集中在DDR4、DDR5和LPDDR4/5等通用型DRAM,HBM3的研发仍在进行中,计划2026年底在上海封装厂实现量产。
这意味着在HBM领域,长鑫存储落后行业最前沿约两代,且16nm制程在缺EUV条件下与三星/海力士的12nm存在3-4年代际差距。
TrendForce预测,到2027年,全球DRAM市场规模将接近4000亿美元,但HBM在DRAM总收入中的占比将从2024年的约12%提升至超过35%。
这意味着,不能生产HBM的厂商将在高增长市场中被边缘化。对于长鑫存储而言,这既是最严峻的挑战,也是最大的机遇。
如果公司能够在HBM3量产的基础上,快速推进HBM4和更先进产品的开发,就有可能在2030年前跻身"HBM俱乐部",从而真正改变全球DRAM产业的竞争格局。反之,如果HBM的技术差距长期无法缩小,长鑫存储可能只能停留在通用DRAM市场的利基定位,难以实现从中国龙头到全球巨头的跃迁。







EOSE — 财报首次双 beat + 轧空行情
Q1 数据:营收 $56.96M,超过预期约 $2.65M,YoY +445%;EPS $0.12,市场原本预期约 -$0.28,首次实现表观盈利。
FY26 收入指引维持 $300M -$400M,中位数 $350M,高于市场预期约 $304M。
商业 pipeline 达 $24.3B,YoY +56%;在手订单 $644.6M,对应 2.6GWh。
公司还披露后续与 Frontier Power USA 签订 2GWh firm capacity reservation agreement,会进一步扩大订单能见度。
需要注意的是,EOSE 这次“盈利”质量不能只看 EPS。
Q1 净利润 $508.9M 主要来自与股价相关的非现金公允价值变动,经营层面仍然亏损。
好的一面是,adjusted EBITDA margin YoY 改善 294 个百分点,说明制造效率和规模效应确实在改善,但还没有进入真正经营盈利阶段。
现金与产能:截至 2026 年 3 月 31 日,公司总现金含 restricted cash 为 $472.4M。
第二条 Thorn Hill 电池模组产线计划在 Q2 末投产,这对全年 $300M-$400M 收入指引很关键。
财报还提到公司累计放电能源超过 6.0GWh,说明产品进入实际运行场景,但市场仍会继续盯交付质量、保修成本、客户复购和项目执行节奏。
市场反应:盘前一度 +27% 冲到 $10.28,距离 5/6 的 $6.54 已涨约 57%。SI 高达 30%-31%,轧空叙事全面发酵。
社媒上有人在 5/11 预判缺口回补,也有人确认 gap closed。技术面关键点在 200MA 约 $10.53,短线如果站不上,容易变成财报利好兑现后的震荡;如果放量突破,轧空叙事可能继续强化。
分歧点:看多逻辑集中在三个方向。
第一,长时储能是 EOSE 的核心甜点,公司披露 pipeline 中相当一部分项目偏 8 小时以上储能,和锂电的主流 2-4 小时场景形成差异化。
第二,英国收入占 Q1 较高比例,市场把它和 UK Cap and Floor 政策推动的长时储能需求联系起来。
第三,Frontier Power USA 与 Cerberus 的结构可能帮助 EOSE 把制造能力和项目开发绑定起来,提升订单转化率。
看空方核心质疑仍然集中在产品可靠性、项目交付和真实盈利质量。有人指出匿名蓝筹客户项目“faded to black”,这类论点需要持续追踪,尤其要看后续是否出现客户取消、延期、质保费用上升或订单转化低于预期。
另一个细节是,虽然做多情绪很强,但也有人认为 CEO Joe 在 Q&A 环节表现偏弱,说明市场对管理层沟通和执行兑现仍有疑虑。
后续关键看:
1. backlog 是否继续增长,以及 backlog 转收入速度;
2. gross margin 是否从深度负值持续改善;
3. adjusted EBITDA loss 是否按季度收窄;
4. Thorn Hill 第二条产线是否按期投产;
5. Frontier Power USA 的 2GWh 订单是否能进入实质交付;
6. 产品可靠性、保修费用、客户复购与项目取消情况;
7. 股价能否有效站上 200MA 附近的 $10.53。

我发现很多时候我用AI工具有一个核心问题,就是不知道怎么精准地写prompt,特别是在生成图片和生成视频的时候。
对于非科班的我来说,我不知道要告诉AI怎么设置镜头角度,图片曝光度、饱和度、色调、色相,以及脚本语言应该怎么去描述,我甚至都不知道这些术语。
编程也一样,写prompt的时候只能模糊写个大概,无法给出我不知道的指令。
所以如果有AI工具能够在特定场景下,让实现效果达到“是你想要的,但是你说不出想要什么”的时候,AI工具才能发挥最大的作用。
xBubble胖鹅AI现在就在做这件事,先来看一下同样的prompt实现的效果(见下图)
可以看出来没有经过对齐的大模型输出了一个看似质量很高,但有严重bug的图片;而场景对齐后的xbubble则给出了相当令人满意的答案。
xBubble 的机制很简单:用户只需要说出想做什么,Bubble Pilot 会判断任务类型,并寻找是否有对应的 SOP(标准操作流程)。
命中 SOP 时,系统会自动选择合适的模型、工具和执行流程,给出更稳定的结果;没有命中时,就先用通用 Agent 完成任务。
后台的 Bubble Engine 会持续学习这些请求,尤其是反复出现但没有 SOP 的任务。它会测试不同的模型、工具和流程,把效果最好的方案沉淀成新的 SOP。
这样,xBubble 会越用越懂用户常见需求,把原本需要用户自己完成的模型选择、提示词设计、工具调用和结果测试,逐步交给系统自动处理。
xBubble目前也支持Bubble Computer和Bubble Personal两种模式,Bubble Computer是端到端项目工作空间,相当于在沙盒中自动运行,不需要用户中间干预。Bubble Personal是本地环境模式,可以支持操作用户本机文件、浏览器、应用与日程等本地应用。
AI工具背后都是大模型,但是好用的工具永远是需要的,有了好的工具,同样的token才能发挥出不同的价值。


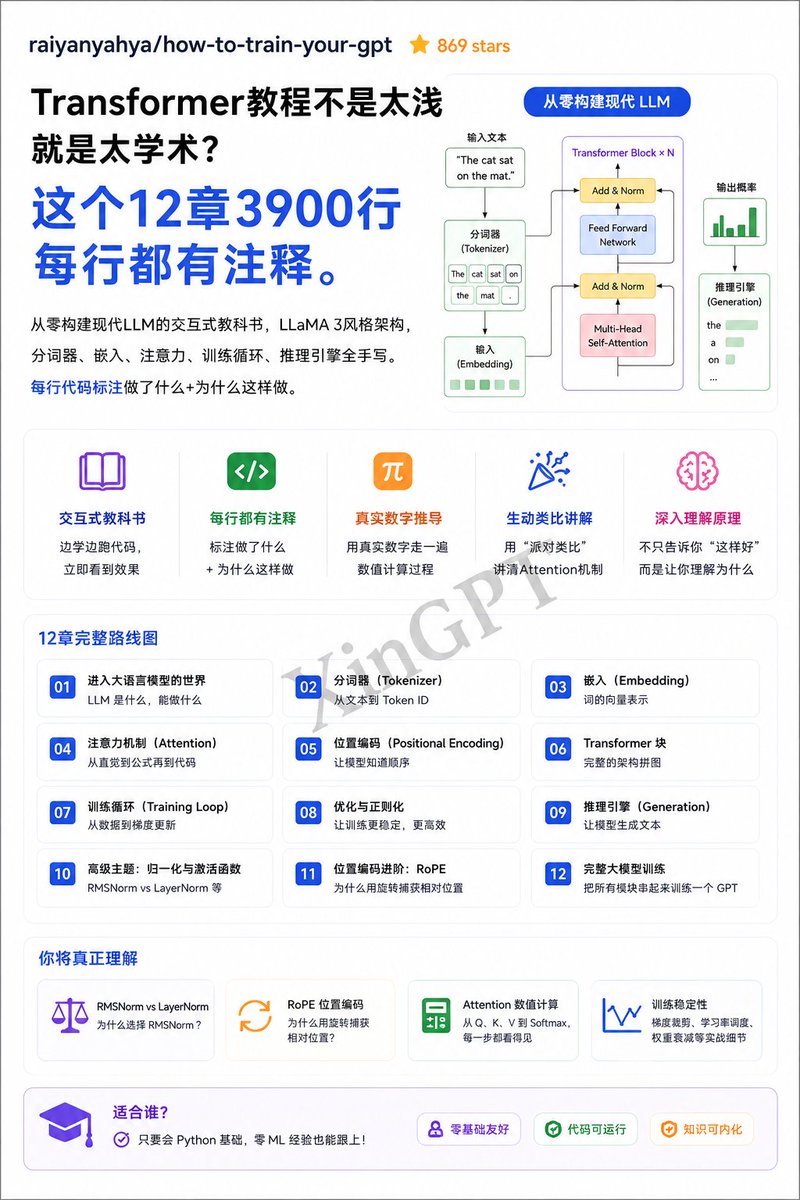
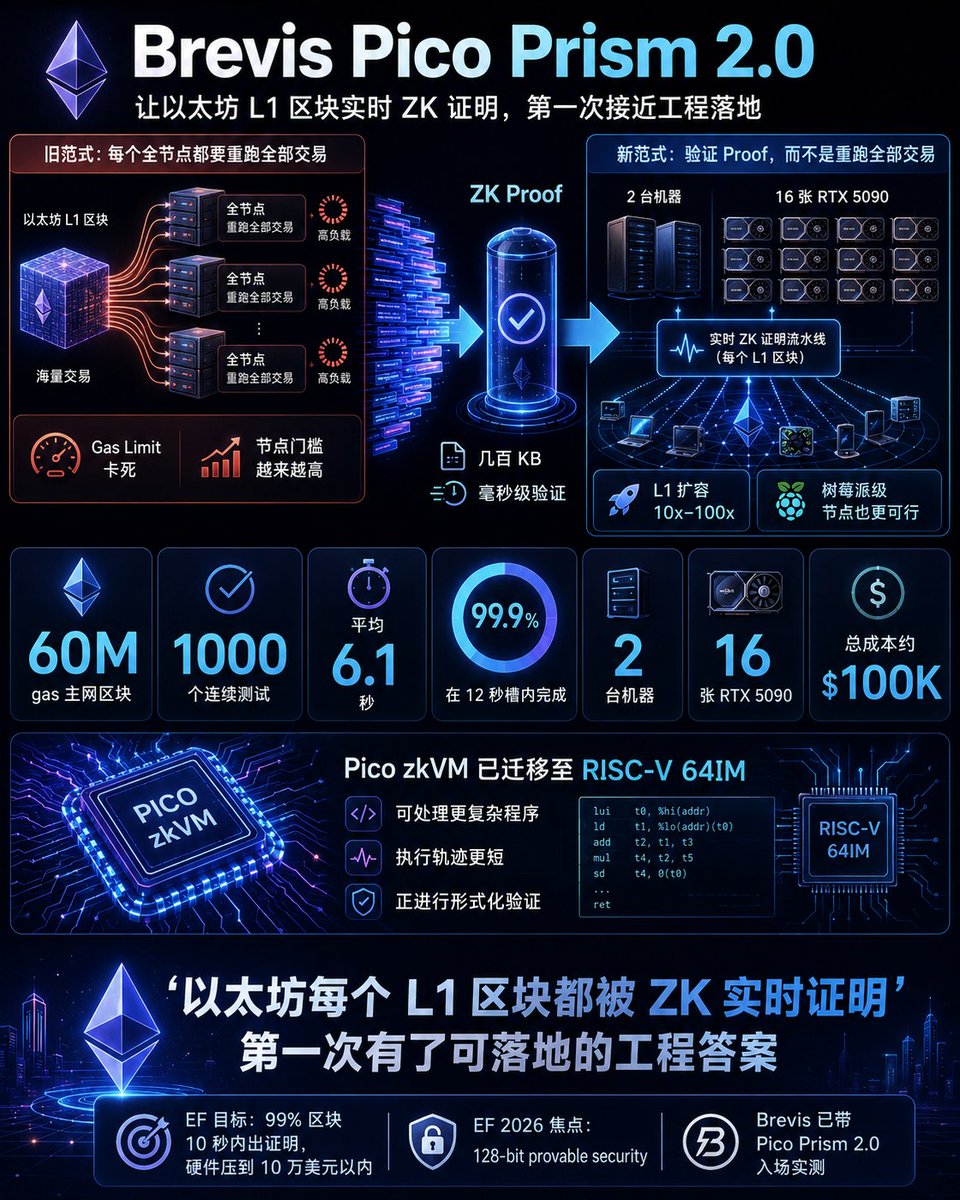
Brevis这个项目真的是Build了很久,从一开始到现在技术和方向一直在迭代。
一年前,以太坊基金会开始路线图逐渐回到L1 扩容,但是当前要验证区块交易需要每个全节点都要把所有交易重新跑一遍,这是 gas limit 卡死、节点门槛越来越高的根本原因。
EF 给的目标是很明确,就是99% 区块 10 秒内出证明、硬件压到 10 万美元以内。
Vitalik 说过 L1 gas limit 可以因此扩 10 倍甚至 100 倍,同时让一台树莓派都能跑全节点。
所以路径只能是ZK证明,如果换成 ZK 证明,节点只需要验证一个几百 KB 的proof,验证时间几毫秒。
今天 Brevis 的 Pico Prism 2.0 在技术上完成了突破:
- 60M gas 真实主网区块、1000 个连续测试
- 平均 6.1 秒、99.9% 在 12 秒槽内完成
- 2 台机器、16 张 RTX 5090(消费级的商用)GPU、总成本 ~$100K;
- Pico zkVM 的执行环境已迁移至 RISC-V 64IM,取代此前的 32 位 ISA。
这是 Pico 2.0 能够处理复杂程序且缩短执行轨迹的底层原因,也是目前正在进行形式化验证的核心。
这个数据意味着什么?
意味着"让以太坊每个 L1 区块都被 ZK 实时证明",这件路线图里最关键也最难的一段,第一次有了可落地的工程答案。
ZK 进入协议核心、L1 扩容 10 倍但不牺牲去中心化,从研究问题变成了工程问题。EF 2026 焦点已经切到安全性(128-bit provable security),5 月 cohort 启动,Brevis 带 Pico Prism 2.0 来临。




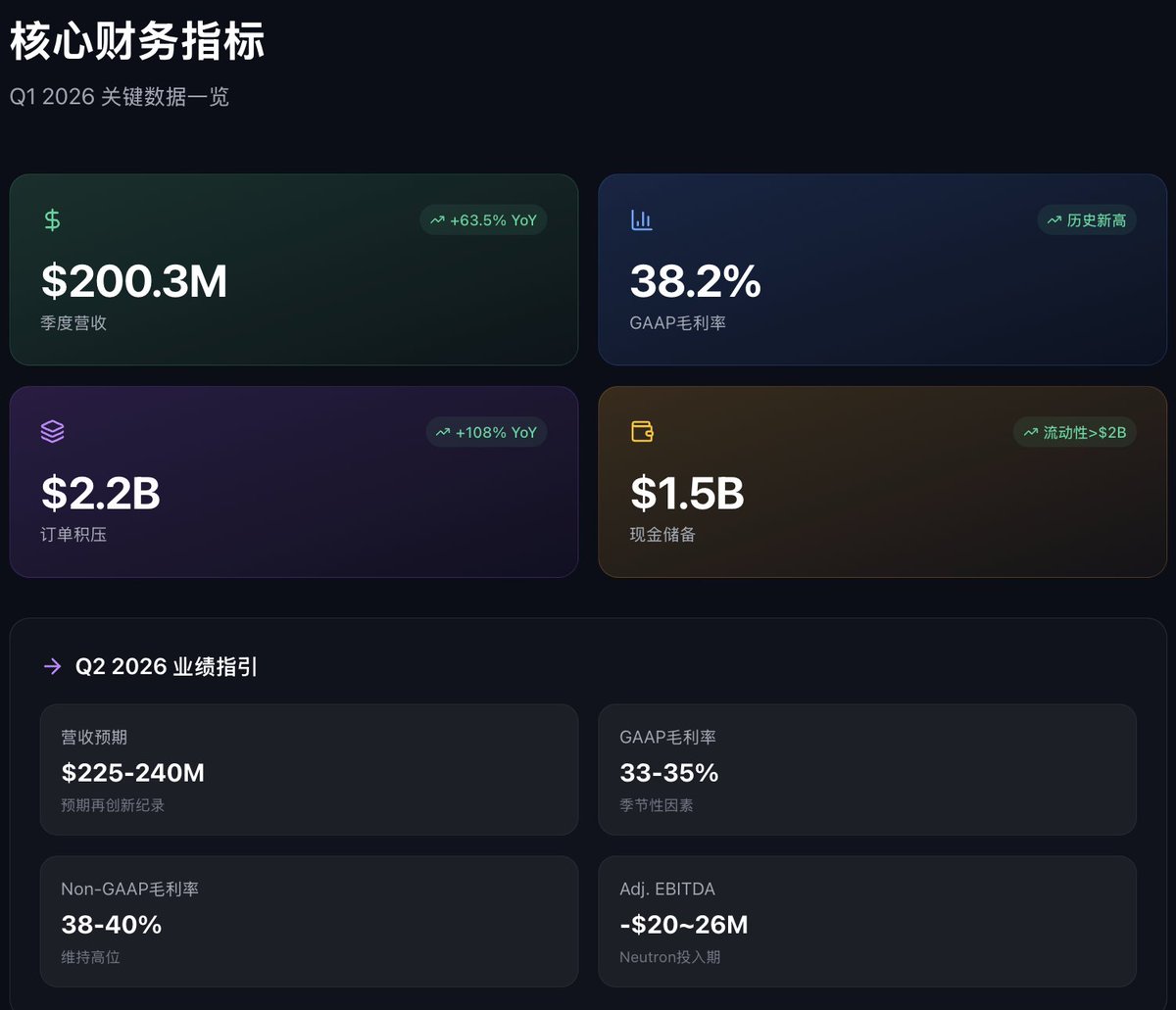
之前跟大家讲过的Rocketlab($RKLB)在发布一季度财报之后,今天大涨 26%,盘中一度超过 100 美金。大涨
大涨的核心原因是一季度公司业务超预期的增长:
1. 财务方面
单季度营收 2 亿美金,同比增长超过 60%;毛利率38.2%,比 24 年四季度提升了 10 个百分点;订单积压量达到创纪录的22亿美元;而Adjusted EBITDA(调整后息税折旧摊销前利润)亏损在本季度收窄至$1,180万美元,相较于2025年第一季度的$2,996万美元同比大幅改善61%。
2.业务方面
最关心的还是中子火箭Neutron的进展,项目因早期测试中的一级储罐破裂事故而将首飞时间调整至2026年第四季度,CEO Peter Beck在财报电话会议上表示在公司已成功完成了在满载飞行压力下的分离事件鉴定测试,这是确保一二级在飞行过程中能够可靠分离的关键步骤。
3. 总结
我认为Q1 反应出来的RKLB进展还是令人乐观的,股价也一步到位了。最主要还是关注Neutron火箭能否如期四季度发射,以及公司盈利能力能否持续达到预期。
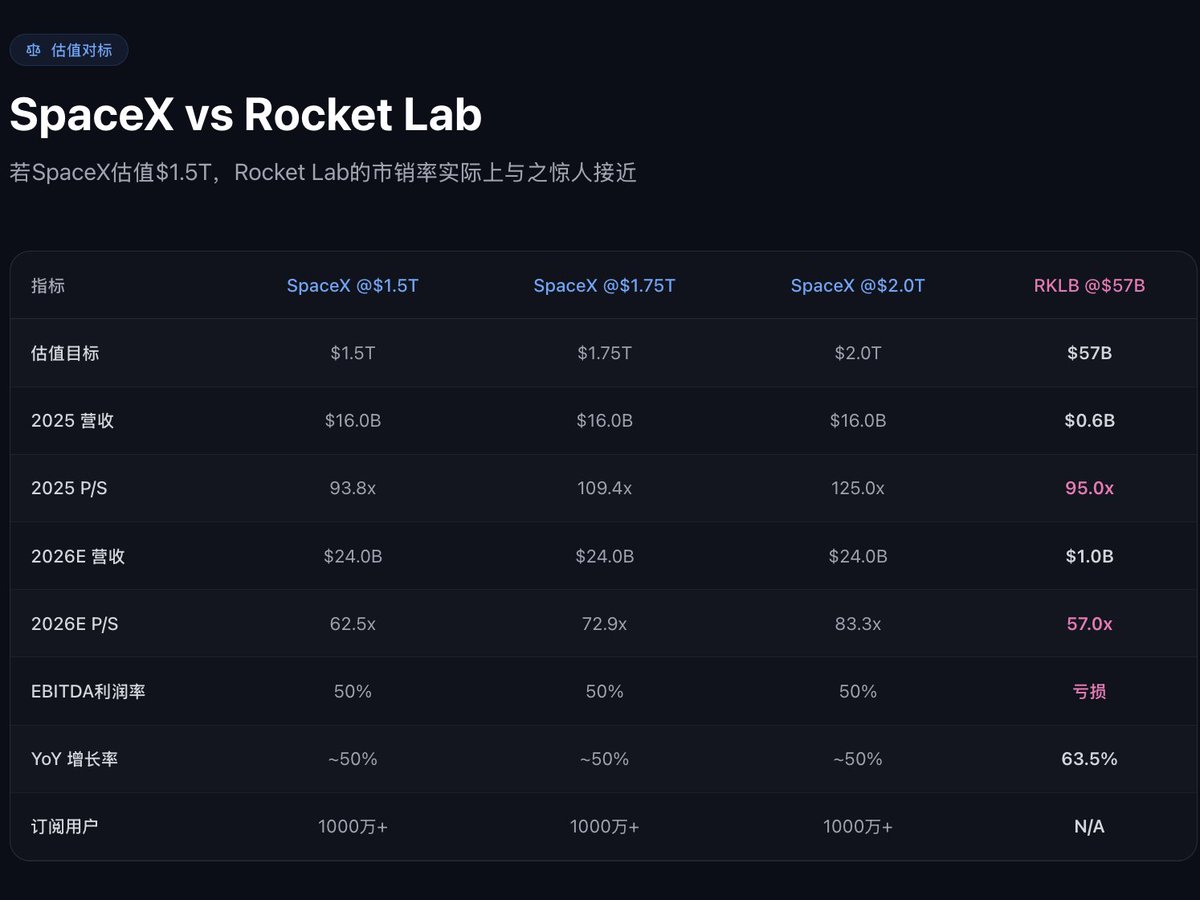
估值上来说,目前价格不算便宜,对标SpaceX的话,26 年市销率57x,也相当接近SpaceX。
继续持有,但是追高可能有风险。
更多关于SpaceX的背景知识,请看之前做过的视频



用过 AI 中转站的人都知道,这个市场的水有多深。
面对巨大的需求,市场上出现了大量草台班子,很多中转站本质上是在倒卖API接口,用户在前端充值,平台说是调用 OpenAI、Anthropic 等模型,实际给的是Qwen,Mimo;甚至有的中转站还能看到用户的隐私信息。
但WorldClaw团队本身就是顶级的安全和白帽,团队发布过AI路由安全问题深度的研究报告,所以他们做的产品不仅保证透明计费,用量充足,还能保证安全和隐私,这点就足够打败市面上的草台班子了。
WorldRouter统一聚合 300+ 主流模型,包括 Claude Opus 4.7 / Sonnet 4.6、GPT-5.5 / Mini、等主流模型。用户只需要一个账户,就能调用不同模型,不用在五六个平台之间反复切账户、配 Key、充余额。
第二个卡点是支付。很多中转站在支付上其实也很麻烦,尤其对全球用户和开发者来说,银行卡、信用卡的地区限制、通道风控等都会影响体验。但好在我们有稳定币啊:WorldClaw 接入 USD1 和 WLFI 体系后,用稳定币完成 AI token credits 的充值、结算和分发,稳定币天然适合跨地区、高频、小额、程序化的 AI 调用场景。
最值得强调的优势之一是价格。
WorldRouter 对主流模型的价格普遍比官方 API 低 30%,相比部分中转站也更有优势。
以Claude Opus 4.7为例:
官方与 OpenRouter 为 $5 / $25,https://t.co/49idxCoqVG 为 $5.5 / $27.5(比官方还贵),WorldRouter 为 $3.5 / $17.5。其他模型也都有优惠价,买不了吃亏,买不了上当。
但 WorldClaw 真正有意思的地方在于,它并不只想做又一个 AI 中转站,团队的野心和愿景远不止于此。
WorldClaw 的定位是 Agent 经济的基础设施,WorldRouter 只是入口之一。围绕这个入口,Agent生态会真正地被激发出来,比如全能的助理WorldAgent、支付的应用Agent Pay以及未来更多的Agent 生态都在roadmap。
带货最后的彩蛋是懂王的邀请函:项目方会送出100 个与 Donald Trump Jr. 在 Mar-a-Lago 共进晚宴的席位的机会,首批订阅 Pro / Max的订阅里抽出。
不说了,我先去用WorldClaw去Vibe Trading了。


这个项目
目前NFT前几天已经打完了,与之对应的代币 $slop 即将启动。
创始人@MichaelHirsch
1. 项目是什么?
Slonks 是一个基于 Ethereum 的链上生成艺术 + 机制实验项目。它的核心是把 CryptoPunk 用一个全链上的神经网络模型重新生成 24×24
